
“李航《统计学习方法》学习笔记” 系列教程以李航老师《统计学习方法》为基础,系列笔记内容主要包括我学习过程中对于书中算法原理的理解和重点知识的汇总。
由于能力有限,不足支持请大家多多指正,大家有什么想法也非常欢迎留言评论!
关于我的更多学习笔记,欢迎您关注“武汉AI算法研习”公众号!
本文分三个部分“【针对朴素贝叶斯法的理解】”、“【朴素贝叶斯算法原理】”、“【文本分类上应用】”来进行展开,总共阅读时间大约10分钟。
【针对朴素贝叶斯法的理解】
1、朴素即是“简单”,朴素贝叶斯方法朴素体现在对各个条件的独立假设,引入独立假设后,大大减少了参数假设空间,有时会牺牲一定的分类准确率;
2、朴素贝叶斯算法理论依据贝叶斯公式,简单的贝叶斯公式能够从历史经验入手,预知未来;
3、朴素贝叶斯分类:对于给定输入x,通过学习到的模型计算后验概率 P(Y=C(k) |X=x),将后验概率取值最大的类作为x的类输出;
【朴素贝叶斯算法原理】
1、公式推导
朴素贝叶斯算法的理论基础是一个贝叶斯公式,贝叶斯公式定义如下(X:表特征;Y:表类别),已知样本特征需要确定所属类别情况可以转换为基于历史统计数据“已知样本类别和特征”的运算中来。
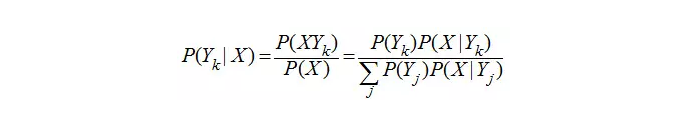
X表特征,一般情况特征属性值是众多的,于是有:
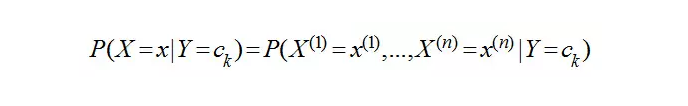

朴素贝叶斯思想:朴素定义了在确定分类的情况下各个特征属性之间是独立互不相关的,于是有:
朴素贝叶斯分类器:在已知历史的样本的情况下,通过贝叶斯公式计算未知样本所属多个可能类别的概率值,能确定最终分类,于是有:
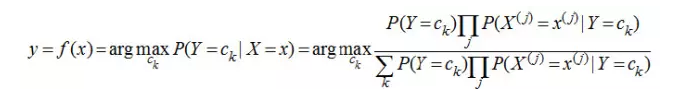
由于针对每个样本,上式分母均一样,简化计算,于是有:

2、朴素贝叶斯参数估计
知道了朴素贝叶斯计算公式,主要是对公式中先验概率和条件概率进行计算,其计算方法分为“极大似然估计”和“贝叶斯估计”
![]()
2.1、极大似然估计
估计(estimating)是一种手段,一种对模型参数进行推测的手段,就是利用训练数据对模型进行calibration. 在标定之前,首先需要有一个模型。模型中需要有待辨识的参数。极大似然估计是 现象--->原理 的过程。
极大似然估计公式见下:

2.2、贝叶斯估计

【文本分类上应用】
背景介绍:文本分类应用广泛,比如垃圾邮件和短信过滤等,需要我们建立一个分类模型,对文本进行归类。贝叶斯模型运用文本分类上:通过一篇文档d,判断其所属的类别Ck,其实是计算文档d在各个类别的概率值,取其最大的类别为最终分类结果。分类过程中所需要的样本特征,针对文本类型来说,最直观的就是“特征词”,在一篇文档d中,可以将部分特征词归为<t1,t2,…,tnd>,这些特征词直接可以决定我们最终文章的分类结果。
方法介绍:
根据朴素贝叶斯分类器公式:
得到针对文本分类器公式:式子中

由于实际计算过程中,概率P(tj | ck)的连乘积容易导致下溢出为0,因此转换为对数计算,进行连加运算:
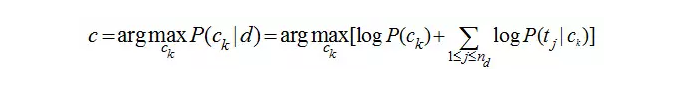
则最终需要我们通过样本文本数据,进行计算得到:

参考文献:
李航.统计学习方法.清华大学出版社