问题描述:
在利用DeeplabV3+ 训练自己数据集时,loss一直在0.4附近震荡,测试集MIOU值在0.55附近(结果较差),折腾许久,终于有所提高,最近计算结果:测试集 MIOU > 0.8,且过拟合现象不明显。
参考链接:
1. https://blog.csdn.net/u011974639/article/details/80948990;
2. https://blog.csdn.net/qq_32799915/article/details/80070711
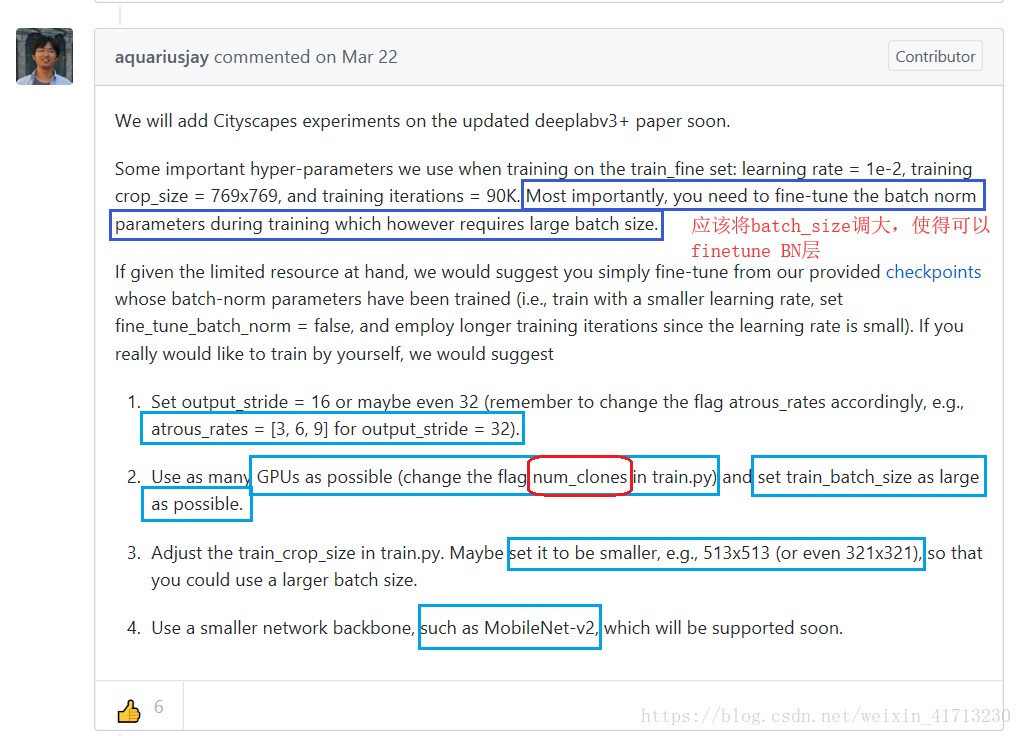
3. https://github.com/tensorflow/models/issues/3730
数据集描述:
数据共 2 类,其中:Images [256, 256, 3], jpg格式;Labels [256, 256, 1], png格式。
具体修改步骤:
1. 更改图片大小
编写脚本,将图片大小进行扩充,修改后为:Images [512, 512, 3], Labels [512, 512, 1]。至于为什么要更改图片大小,后面我会进行说明。
2. 运行datasets下build_voc2012_data.py
生成.tfrecord数据。为了方便,我将自己的数据集直接替换 VOC2012里面的数据集,因为之前将 VOC2012 数据集已跑成功,如果不懂如何跑 VOC2012数据集,请参考:利用DeeplabV3+训练VOC2012数据集。
3. 修改datasets下segmentation_dataset.py
根据自己的数据集情况进行修改,由于我的数据集只有2类,所以num_classes 取 2.
_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1689, # 在PASCAL数据集上更改为自己的数据
# 'train_aug': 10582,
# 'trainval': 2913,
'val': 564, # 样本数:1689 + 564 = 2253
},
num_classes=2, # 一共有2类,0:背景 1:**
ignore_label=255, # ignore_label 用来 crop size 做填充的,默认为255
4. 修改utils下train_utils.py
由于数据集不平衡,对loss的权重系数进行修改。经过计算,像素比 px(0):px(1)=15:1, 所以取 label0_weight = 1, label1_weight = 15.
# 训练自己的数据集,针对数据不平衡,此处进行修改
ignore_weight = 0
label0_weight = 1 # 背景的权重系数
label1_weight = 15 # ** 的权重系数
not_ignore_mask = tf.to_float(tf.equal(scaled_labels, 0)) * label0_weight + \
tf.to_float(tf.equal(scaled_labels, 1)) * label1_weight + \
tf.to_float(tf.equal(scaled_labels, ignore_label)) * ignore_weight
tf.losses.softmax_cross_entropy(
one_hot_labels,
tf.reshape(logits, shape=[-1, num_classes]),
weights=not_ignore_mask,
scope=loss_scope)同时,修改 exclude_list。
exclude_list = ['global_step', 'logits'] # 训练自己的数据集时,此处进行修改5. 修改train.py
根据自己的电脑情况设置参数,我这里将 num_clones设置为2,因为含有2个1080tiGPU。
如何需要训练BN层,batch_size值最好大于12,如果显存不够,可调整Crop_size大小,但不得小于[321, 321],我之前效果一直不好,就是因为将Crop_size设置小了。
至此已完成训练,将Crop_size从[256, 256]改为[321, 321]后,模型MIOU值从0.55增加到 > 0.8,目前仍在优化中。
python train.py \
--logtostderr \
--num_clones=2 \ # 设置GPU的数量,默认为1
--train_split="train" \ # 选择用于训练的数据集
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=321 \ # 该值最小为[321, 321]
--train_crop_size=321 \
--train_batch_size=12 \
--initialize_last_layer=False \
--last_layers_contain_logits_only=True \
--training_number_of_steps=30000 \
--fine_tune_batch_norm=True \ # 当batch_size大于12时,设置为True
--tf_initial_checkpoint='./weights/deeplabv3_pascal_train_aug/model.ckpt' \
--train_logdir='./checkpoint' \ # 保存训练的中间结果的路径
--dataset_dir='./datasets/tfrecord' # 生成的tfrecord的路径曾经的尝试:
1. 修改预训练权重
从官网上下载了不同的预训练权重用于初始化,但结果无明显变化。
2. 修改 initialize_last_layer 和 last_layers_contain_logits_only的值
对这三种情况均进行了计算,结果变化不大。

3. 调整 Batch_size 和 Learning_rate
尝试了不同的 batch_size 和 learning_rate值,最大跌代步数 100K 步,MIOU 差值不超过 0.1.
4. 修改Crop_size
Crop_size 的设置要求:
1. 不得小于 [321, 321]
2. (Crop_size - 1) / 4 = 整数
将 Crop_size设置为[256, 256],结果不会好,因为其有ASPP(atrous spatial pyramid pooling)模块,如果图片过小,到feature map时没有扩张卷积的范围大了,所以要求一个最小值。这就是为什么在开始的时候,将自己的图片放大。
最后一句:
因为一个参数(crop_size)设置错误,导致结果迟迟不理想,想想觉得真的是……
哎……