Python中的多进程与进程池
文章目录
1.multiprocessing类
| 方法 | 含义 |
|---|---|
| current_process() | 获取当前进程对象 类似于threading.current_thread() |
| active_children() | 获取当前进程所有活动的子进程列表。注意:不包含自己,即当前进程。有点类似于threading.enumerate() |
| cpu_count() | 返回当前系统CPU的数量 |
import multiprocessing
if __name__ == "__main__":
p = multiprocessing.Pool(4)
print(multiprocessing.current_process())
print(multiprocessing.active_children())
print(multiprocessing.cpu_count())

2.multiprocessing.Pool进程池
构造方法
Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]]) #构造方法
-
processes #进程池最大使用的工作进程数量,默认值为None,会使用os.cpu_count()来获取cpu的数量作为最大进程数量。
-
initializer #进程初始化函数,进程初始化时会调用该函数。
-
initargs #参数,为initializer函数调用时传递的参数。
-
maxtasksperchild #工作进程退出前可以完成的任务数,完成后用一个新的工作进程来替代原进程,让闲置的资源释放,默认是None,此意味只要Pool存在工作进程就一直存活(如果改为maxtasksperchild=1每次线程执行worker时都会重新创建一个新的进程并执行show)
-
context #用在制定工作进程启动时的上下文,一般使用multiprocessing.Pool()或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context。(context中有一个进程或者工作任务的队列,会产生阻塞,保证进程会永久存在。)
-
注意Pool创建后,会立即实例化指定个数的进程。以备使用
import multiprocessing import logging import sys import time logging.basicConfig(level=logging.INFO,format="%(name)s %(process)d %(processName)s %(thread)d %(message)s",stream=sys.stdout) log = logging.getLogger(__name__) def show(i): log.info("我启动了{}".format(i)) def worker(k): time.sleep(2) log.info("正在打印-{}".format(k)) if __name__ == "__main__": pool = multiprocessing.Pool(processes=2,initializer=show,initargs=(8,),maxtasksperchild=None) # # 如果改为maxtasksperchild=1每次线程执行worker时都会重新创建一个新的进程并执行show #pool = multiprocessing.Pool(processes=2, initializer=show, initargs=(8,), maxtasksperchild=1) time.sleep(3) for i in range(4): pool.apply(worker,args=(i+5,))
常用方法
| 名称 | 说明 |
|---|---|
| apply(self,func,args=(),kwds={}]) | 柱塞执行,导致主进程执行其他进程就像一个个执行 func #要执行的函数 args #函数的位置参数 kwds #函数的关键字参数 |
| apply_async(self,func,args=(),kwds={},callback=None,error_callback=None) | 与apply方法用法一致,非阻塞异步执行,得到结果会执行回调函数callback,如果出现异常会执行异常回调函数error_callback。会返回一个将来的返回对象。 |
| close(self) | 关闭池,池不能再接受新的任务,所有任务完成后退出进程 |
| terminate(self) | 立即结束工作进程,不再处理未处理的任务 |
| join(self) | 主进程阻塞等待子进程的退出,join方法要在close或terminate后使用。 否则由于进程池的进程默认不会消亡,会永久阻塞 |
-
apply(self,func,args=(),kwds={}])->return #同步调用,会阻塞,一个个执行。相当于串行
- func #要执行的函数
- args #函数的位置参数
- kwds #函数的关键字参数
- return #返回函数执行的放回结果
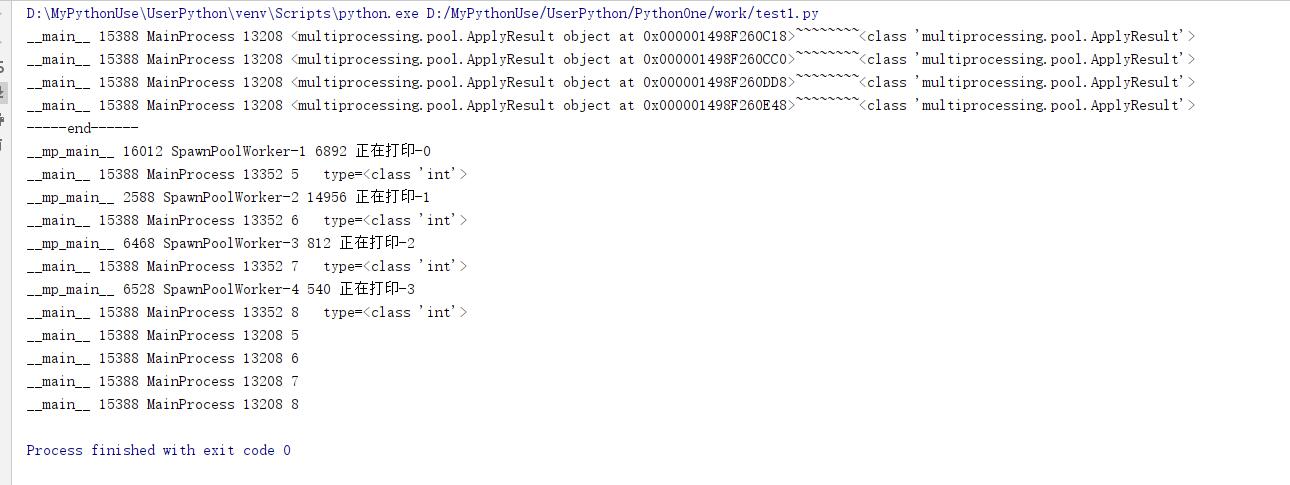
import multiprocessing import logging import sys import time logging.basicConfig(level=logging.INFO,format="%(name)s %(process)d %(processName)s %(thread)d %(message)s",stream=sys.stdout) log = logging.getLogger(__name__) def worker(k): time.sleep(2) log.info("正在打印-{}".format(k)) return k+5 if __name__ == "__main__": p = multiprocessing.Pool(4) for i in range(5): req = p.apply(func=worker,args=(i,)) log.info("{}~~~~~~~~".format(req)) print("-----------")
-
apply_async(self,func,args=(),kwds={},callback=None,error_callback=None)->multiprocessing.pool.ApplyResult #同步执行,返回结果是一个未来的结果对象
- func #要执行的函数
- args #函数的位置参数
- kwds #函数的关键字参数
- callback #回调函数,当函数执行完成后,回调执行的函数,会在主进程中创建一个线程来执行。
- error_callback #异常回调函数,如果发生异常后,会在主进程中创建一个线程执行。(一参的回调函数)
- multiprocessing.pool.ApplyResult 函数执行返回的结果对象。在未来的函数执行完成后,会对这个结果对象赋值。(一参的回调函数)
-
class multiprocessing.pool.AsyncResult类
- 由Pool.apply_async()和Pool.map_async()返回的结果的类。
方法 函数 get(self,itemout=None) 获取异步请求函数执行的返回结果。如果未执行完成,会产生一个阻塞。直到返回结果为止。
timeout #设置超时时长,如果指定时间内没有返回会抛出一个multiprocessing.context.TimeoutError异常wait(self,timeout=None) 等待结果,会阻塞,直到结果返回。无论是否等到,都返回None。
timeout超时时长,默认为None表示无限等待。ready(self) 返回的调用是否已经完成,完成返回True,否则返回False successful(self) 返回的调用是否在没有引发异常的情况下完成。如果结果还未计算完成。会抛出AssertionError异常
import multiprocessing
import logging
import sys
import time
logging.basicConfig(level=logging.INFO,format="%(name)s %(process)d %(processName)s %(thread)d %(message)s",stream=sys.stdout)
log = logging.getLogger(__name__)
def worker(k):
time.sleep(2)
log.info("正在打印-{}".format(k))
return k+5
def callback(value):
log.info("{}\t type={}".format(value,type(value)))
if __name__ == "__main__":
p = multiprocessing.Pool(4)
reqs = []
for i in range(4):
req = p.apply_async(func=worker,args=(i,),callback=callback,error_callback=callback)
log.info("{}~~~~~~~~{}".format(req,type(req)))
reqs.append(req)
print("-----end------")
while True:
for i in reqs:
if not i.ready():
break
else:
for i in reqs:
log.info(i.get())
break
time.sleep(1)
多进程,多线程的选择
- CPU密集型
- CPython中使用到了GIL,多线程的时候锁相互竞争,且多核优势不能发挥,选用Python多进程效率更高。
- IO密集型
- 在Python中适合是用多线程,可以减少多进程间IO的序列化开销。且在IO等待的时候,切换到其他线程继续执 行,效率不错。
应用
- 请求/应答模型:WEB应用中常见的处理模型
- master启动多个worker工作进程,一般和CPU数目相同。发挥多核优势。
- worker工作进程中,往往需要操作网络IO和磁盘IO,启动多线程,提高并发处理能力。worker处理用户的请求, 往往需要等待数据,处理完请求还要通过网络IO返回响应。这就是nginx工作模式。
Linux的特殊进程
在Linux/Unix中,通过父进程创建子进程。
僵尸进程
一个进程使用了fork创建了子进程,如果子进程终止进入僵死状态,而父进程并没有调用wait或者waitpid获取子进 程的状态信息,那么子进程仍留下一个数据结构保存在系统中,这种进程称为僵尸进程。
僵尸进程会占用一定的内存空间,还占用了进程号,所以一定要避免大量的僵尸进程产生。有很多方法可以避免僵 尸进程。
孤儿进程
父进程退出,而它的子进程仍在运行,那么这些子进程就会成为孤儿进程。孤儿进程会被init进程(进程号为1)收 养,并由init进程对它们完成状态收集工作。
init进程会循环调用wait这些孤儿进程,所以,孤儿进程没有什么危害。
守护进程
它是运行在后台的一种特殊进程。它独立于控制终端并周期性执行某种任务或等待处理某些事件。
守护进程的父进程是init进程,因为其父进程已经故意被终止掉了。
守护进程相对于普通的孤儿进程需要做一些特殊处理。