一、并发任务执行框架
架构师是什么?
在一个软件项目开发过程中,将客户的需求转换为规范的开发计划及文本,并制定这个项目的总体架构,指导整个开发团队完成这个计划的那个人,就是 架构师。一般是一个项目里的最资深的专业技术人员,可以说架构师首先一定是个Java高级开发人员。
主要职责
主要是架构设计、软件开发,具体来说包括
1、确认需求
在项目开发过程中,架构师是在需求规格说明书完成后介入的,需求规格说明书必须得到架构师的认可。架构师需要和分析人员反复交流,以保证自己完整并准确地理解用户需求。
2、系统分解
依据用户需求,整个系统是否需要分层,如何进行分层,架构师将系统整体分解为更小的子系统和组件,从而形成不同的逻辑层或服务。随后,架构师会确定各层的接口,层与层相互之间的关系。架构师不仅要对整个系统分层,进行“纵向”分解,还要对同一逻辑层分块,进行“横向”分解。
软件架构师的功力基本体现于此,这是一项相对复杂的工作。
3、技术选型
架构师通过对系统的一系列的分解,最终形成了软件的整体架构。技术选择主要取决于软件架构,就是不断找到系统的瓶颈和弱点,采用分而治之、缓存、异步、集群等手段逐渐化解,并平衡处理系统各项要求(性能、安全、可用性、伸缩性、扩展性…)的过程。由此形成了架构。
什么样的架构才是好的架构?
答案:是适用于当前业务和团队成员,并保留适当前瞻性(最多半年的业务增长)的就是好架构。
Web Server运行在Windows上还是Linux上?数据库采用MSSql、Oracle还是Mysql?需要不需要采用MVC或者Spring等轻量级的框架?前端采用富客户端还是瘦客户端方式?类似的工作,都需要在这个阶段提出,并进行评估。
架构师对产品和技术的选型仅仅限于评估,没有决定权,最终的决定权归项目经理。架构师提出的技术方案为项目经理提供了重要的参考信息,项目经理会从项目预算、人力资源、时间进度等实际情况进行权衡,最终进行确认。
4、制定技术规格说明
架构师在项目开发过程中,是技术权威。他需要协调所有的开发人员,与开发人员一直保持沟通,始终保证开发者依照它的架构意图去实现各项功能。
5、核心、关键或者难点任务的开发
6、开发管理
通常还需要承担一些管理职能:规划产品路线、估算人力资源和时间资源、安排人员职责分工,确定计划里程碑点、指导工程师工作、过程风险评估与控制等。这些管理事务需要对产品技术架构、功能模块划分、技术风险都熟悉的架构师参与或直接负责。
7、沟通协调
项目目组内外各种角色沟通协调,可以说架构师相当多的时间用在和人打交道上。处理好人的关系对架构和项目的成功至关重要。
架构师的方方面面
作用
负责系统架构设计,同时也要负责架构的实施落地、演化发展、推广重构。
充当救火队员的角色,系统出现故障或者“灵异现象”,会请他们出马解决。
架构师对某一领域有较深刻的认识,有时候甚至是坚定的技术信仰,乐于同他人分享自己的知识,希望能够推广自己的技术主张。
效果
不管项目有多么艰难复杂,只要有优秀的架构师,大家就会坚信,项目一定能顺利完成。优秀的架构师带给项目组的,不只是技术和方法,更重要的是必胜的信念。这种信念是架构师自己积累起来的气场和影响力。
架构师通常会开发项目中最具技木难度和挑战性的模块,从而为整个项目的顺利进行铺平道路。这些模块包括基础框架、公共组件、通用服务等平台类产品。在大型互联网应用中,基础服务承担着海量的数据存储和核心业务处理服务,有许多挑战性的工作。所以我们的实战就是实现一个基础框架和对一个项目进行性能优化。
二、实现一个基础框架
1、需求的产生和分析
公司里有两个项目组,考试组有批量的离线文档要生成,题库组则经常有批量的题目进行排重和根据条件批量修改题目的内容。架构组通过对实际的上线产品进行用户调查,发现这些功能在实际使用时,用户都反应速度很慢,而且提交任务后,不知道任务的进行情况,做没做?做到哪一步了?有哪些成功?哪些失败了?都一概不知道。
架构组和实际的开发人员沟通,他们都说,因为前端提交任务到Web后台以后,是一次要处理多个文档和题目,所以速度快不起来。提示用多线程进行改进,实际的开发人员表示多线程没有用过,不知道如何使用,也担心用不好。综合以上情况,架构组决定在公司的基础构件库中提供一个并发任务执行框架,以解决上述用户和业务开发人员的痛点:
1)对批量型任务提供统一的开发接口
2)在使用上尽可能的对业务开发人员友好
3)要求可以查询批量任务的执行进度
2、需要做什么
要实现这么一个批量任务并发执行的框架,我们来分析一下我们要做些什么?
2.1、批量任务,为提高性能:
必然的我们要使用java里的多线程,为了在使用上尽可能的对业务开发人员友好和简单,需要屏蔽一些底层java并发编程中的细节,让他们不需要去了解并发容器,阻塞队列,异步任务,线程安全等等方面的知识,只要专心于自己的业务处理即可。
2.2、每个批量任务拥有自己的上下文环境:
因为一个项目组里同时要处理的批量任务可能有多个,比如考试组,可能就会有不同的学校的批量的离线文档生成,而题库组则会不同的学科都会有老师同时进行工作,因此需要一个并发安全的容器保存每个任务的属性信息,
2.3、自动清除已完成和过期任务
因为要提供进度查询,系统需要在内存中维护每个任务的进度信息以供查询,但是这种查询又是有时间限制的,一个任务完成一段时间后,就不再提供进度查询了,则就需要我们自动清除已完成和过期任务,用定时轮询吗?
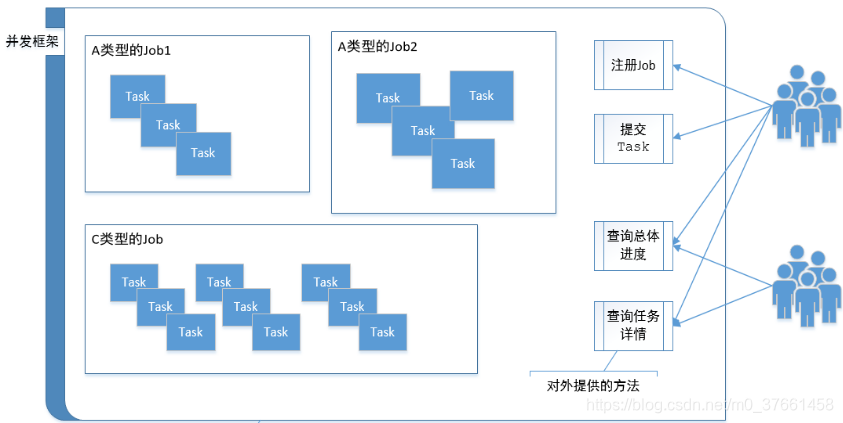
3、具体实现
可查询进度的并发任务执行框架
3.1、用户业务方法的结果?
一个方法执行的结果有几种可能?三种,成功:按预想的流程出了结果;失败:按按预想的流程没出结果;异常:没按预想的流程抛出了预料之外的错误。因此我们定义了一个枚举,表示这三种情况,
public enum TaskResultType {
success,/*方法执行完成,业务结果也正确*/
failure,/*方法执行完成,业务结果错误*/
exception/*方法执行抛出了异常*/
}
对于方法的业务执行结果,返回值有很多种可能,基本类型,系统定义的对象类型,用户自定义的对象类型都是存在的,我们需要用泛型来说表示这个结果。同时方法执行失败了,我们还需要告诉用户或者业务开发人员,失败的原因,我们再定义了一个任务的结果类。
public class TaskResult<R> {
// 方法执行结果
private final TaskResultType resultType;
// 方法执行后的结果数据
private final R returnValue;
// 如果方法失败,这里可以填充原因
private final String reason;
3.2、如何执行用户的业务方法?
我们是个框架,用户的业务各种各样,都要放到我们框架里执行,怎么办?当然是定义个接口,我们的框架就只执行这个方法,而使用我们框架的业务方都应该来实现这个接口,当然因为用户业务的数据多样性,意味着我们这个方法的参数也应该用泛型。
public interface ITaskProcesser<T,R> {
TaskResult<R> executeTask(T data);
}
3.3、用户如何提交他的工作和查询任务进度?
用户在前端提交了工作(JOB)到后台,我们需要提供一种封装机制,让业务开发人员可以将任务的相关信息提交给这个封装机制,用户的需要查询进度的时候,也从这个封装机制中取得,同时我们的封装机制内部也要负责清除已完成任务。
在这个封装机制里我们定义了一个类JobInfo,抽象了对用户工作的封装,一个工作可以包含多个子任务(TASK),这个JobInfo中就包括了这个工作的相关信息,比如工作名,用以区分框架中唯一的工作,也可以避免重复提交,也方便查询时快速定位工作,除了工作名以外,工作中任务的列表,工作中任务的处理器都在其中定义。
public class JobInfo<R> {
//工作名,用以区分框架中唯一的工作
private final String jobName;
// 工作中任务的长度
private final int jobSize;
// 处理工作中任务的处理器
private final ITaskProcesser<?,?> taskProcesser;
// 任务的成功次数
private AtomicInteger successCount;
// 工作中任务目前已经处理的次数
private AtomicInteger taskProcessCount;
// 存放每个任务的处理结果,供查询用
private LinkedBlockingDeque<TaskResult<R>> taskResultQueues;
// 保留的工作的结果信息供查询的时长
private final long expireTime;
同时JobInfo还有相当多的关于这个工作的方法,比如查询工作进度,查询每个任务的处理结果,记录每个任务的处理结果等等

负责清除已完成任务,我们则交给CheckJobProcesser类来完成,定时轮询的机制不够优雅,因此我们选用了DelayQueue来实现这个功能
public class CheckJobProcesser {
// 存放任务的队列
private static DelayQueue<ItemVo<String>> queue = new DelayQueue<ItemVo<String>>();
并且在其中定义了清除已完成任务的Runnable和相关的工作线程。
private static class FetchJob implements Runnable{
private static DelayQueue<ItemVo<String>> queue = CheckJobProcesser.queue;
// 缓存的工作信息
private static Map<String, JobInfo<?>> jobInfoMap = PendingJobPool.getMap();
@Override
public void run() {
while(true) {
try {
ItemVo<String> item = queue.take();
String jobName = (String)item.getData();
jobInfoMap.remove(jobName);
System.out.println(jobName+" 过期了,从缓存中清除");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 初始化队列中到期的任务
*/
static {
Thread thread = new Thread(new FetchJob());
thread.setDaemon(true);
thread.start();
System.out.println("开启过期检查的守护线程......");
}
3.4、框架的主体类
主体类则是PendingJobPool,这也是业务开发人员主要使用的类。这个类主要负责调度,例如工作(JOB)和任务(TASK)的提交,任务(TASK)的保存,任务(TASK)的并发执行,工作进度的查询接口和任务执行情况的查询等等。
public class PendingJobPool {
// 框架运行时的线程数,与机器的CPU数相同
private static final int THREAD_COUNTS = Runtime.getRuntime().availableProcessors();
// 用于存放任务的队列,供线程池使用
private static BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<Runnable>(5000);
// 线程池,固定大小,有界队列
private static ExecutorService taskExcutor = new ThreadPoolExecutor(
THREAD_COUNTS, THREAD_COUNTS, 60, TimeUnit.SECONDS, taskQueue);
// 工作信息的存储容器
private static ConcurrentHashMap<String,JobInfo<?>> jobInfoMap = new ConcurrentHashMap<String,JobInfo<?>>();
// /*检查过期工作的处理器*/
// private static CheckJobProcesser checkJob = CheckJobProcesser.getInstance();
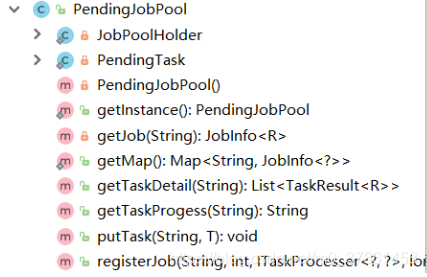
3.5、流程图
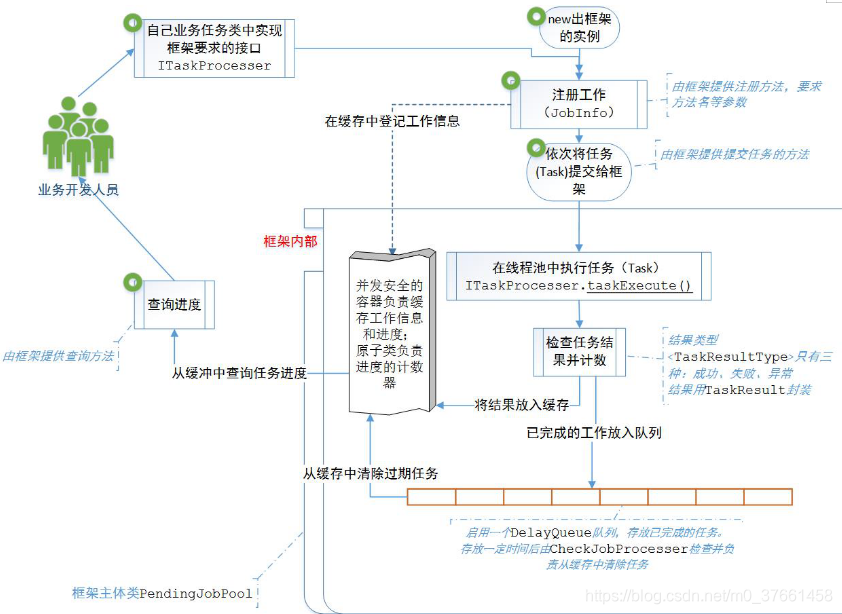
测试
参见代码包com.chj.thread.capt09下,以及和spring的集成,在模块TaskFramework中。
当然和spring集成的话,某些单例化的部分就不需要了。
三、性能优化实战
1、项目背景和问题
这个项目来自为电信教育系统设计开发的一套自适应的考试学习系统,面向的用户主要是职业学院的的老师和学生以及短时间脱产学习的在职人员。什么叫自适应呢?就是当时提出一种教育理念,对学员的学习要求经常考试进行检查,学员的成绩出来以后,老师会要求系统根据每个学员的考卷上错误的题目从容量为10万左右的题库中抽取题目,为每个学员生成一套各自个性化的考后复习和练习的离线练习册。所以,每次考完试,特别是比较大型的考试后,要求生成的离线文档数量是比较多的,一个考试2000多人,就要求生成2000多份文档。当时我们在做这个项目的时候,因为时间紧,人员少,很快做出第一版就上线运营了。
当然,大家可以想到,问题是很多的,但是反应最大,用户最不满意的就是这个离线文档生成的功能,用户最不满意的点:离线文档生成的速度非常慢,慢到什么程度呢?一份离线文档的生成平均时长在50~55秒左右,遇到成绩不好的学生,文档内容多的,生成甚至需要3分钟,大家可以算一下,2000人,平均55秒,全部生成完,需要2000*55=110000秒,大约是30个小时。
为什么如此之慢?这跟离线文档的生成机制密切相关,对于每一个题目要从保存题库的数据库中找到需要的题目,单个题目的表现形式如图,数据库中存储则采用类html形式保存,对于每个题目而言,解析题目文本,找到需要下载的图片,每道题目都含有大量或大型的图片需要下载,等到文档中所有题目图片下载到本地完成后,整个文档才能继续进行处理。
2、分析和改进
第一版的实现,服务器在接收到老师的请求后,就会把批量生成请求分解为一个个单独的任务,然后串行的完成。
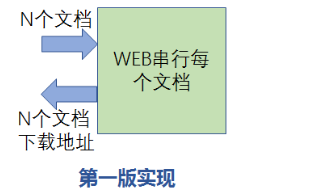
于是在第二版的实现上,首先我们做了个服务拆分,将生成离线文档的功能拆了出来成为了单独的服务,对外提供RPC接口,在WEB服务器接收到了老师们提出的批量生成离线文档的要求以后,将请求拆分后再一一调用离线文档生成RPC服务,这个RPC服务在实现的时候有一个缓冲的机制,会将收到的请求进行缓存,然后迅速返回一个结果给调用者,告诉调用者已经收到了请求,这样WEB服务器也可以很快的对用户的请求进行应答。
所以我们有了第一次改进,参见com.chj.thread.capt10.RpcServiceWebV1。
public class RpcServiceWebV1 {
// 处理文档生成的线程池 IO密集型 故而大小设置为CPU核心数*2
private static ExecutorService docMakeService = Executors.newFixedThreadPool(Consts.THREAD_COUNT*2);
// 处理文档上传的线程池
private static ExecutorService docUploadService = Executors.newFixedThreadPool(Consts.THREAD_COUNT*2);
private static CompletionService<String> docCompletingServcie = new ExecutorCompletionService(docMakeService);
private static CompletionService<String> docUploadCompletingServcie = new ExecutorCompletionService<String>(docUploadService);
public static void main(String[] args) throws InterruptedException, ExecutionException {
int docCount = 60;
System.out.println("题库开始初始化...........");
SL_QuestionBank.initBank();
System.out.println("题库初始化完成。");
List<SrcDocVo> docList = CreatePendingDocs.makePendingDoc(docCount);
long startTotal = System.currentTimeMillis();
for(SrcDocVo doc : docList) {
docCompletingServcie.submit(new MakeDocTask(doc));
}
for(int i=0; i<docCount; i++) {
Future<String> future = docCompletingServcie.take();
docUploadCompletingServcie.submit(new UploadTask(future.get()));
}
// 展示时间
for(int i=0; i<docCount; i++) {
docUploadCompletingServcie.take().get();
}
System.out.println("共耗时:"+(System.currentTimeMillis()-startTotal)+"ms");
}
/**
* 生成文档的工作任务
*/
private static class MakeDocTask implements Callable<String>{
private SrcDocVo pendingDocVo;
public MakeDocTask(SrcDocVo pendingDocVo) {
this.pendingDocVo = pendingDocVo;
}
@Override
public String call() throws Exception {
long start = System.currentTimeMillis();
// 普通生成方式
String result1 = ProduceDocService.makeDoc(pendingDocVo);
// 题目并行化方式
String result = ProduceDocService.makeDocAsyn(pendingDocVo);
System.out.println("文档"+result+"生成耗时:"+(System.currentTimeMillis()-start)+"ms");
return result;
}
}
/**
* 上传文档的工作任务
*/
private static class UploadTask implements Callable<String>{
private String fileName;
public UploadTask(String fileName) {
this.fileName = fileName;
}
@Override
public String call() throws Exception {
long start = System.currentTimeMillis();
String result = ProduceDocService.upLoadDoc(fileName);
System.out.println("已上传至[" + result + "]耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}
}
我们看这个离线文档,每份文档的生成独立性是很高的,天生就适用于多线程并发进行。所以在RPC服务实现的时候,使用了生产者消费者模式,RPC接口的实现收到了一个调用方的请求时,会把请求打包放入一个容器,然后会有多个线程进行消费处理,也就是生成每个具体文档。
当文档生成后,再使用一次生产者消费者模式,投入另一个阻塞队列,由另外的一组线程负责进行上传。当上传成功完成后,由上传线程返回文档的下载地址,表示当前文档已经成功完成。
文档具体的下载地址则由WEB服务器单独去数据库或者缓存中去查询。
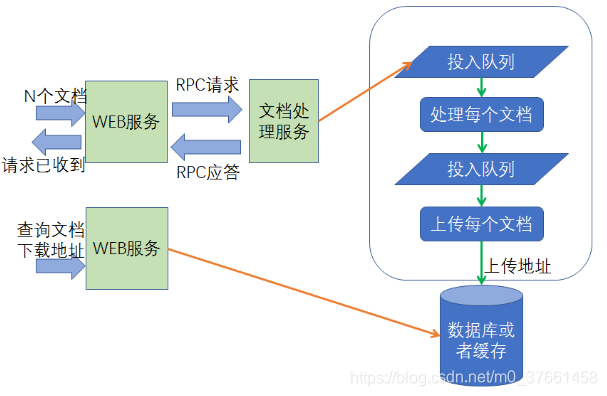
对于每个离线文档生成本身,我们来看看它的业务:
- 1)从容量为10万左右的题库中为每个学生抽取适合他的题目。
- 2)每道题目都含有大量的图片需要下载到本地,和文字部分一起渲染。
但是我们仔细考察整个系统的业务就会发现,我们是在一次考试后为学员生成自适应的练习册,换句话说,不管考试考察的内容如何,学生的成绩如何,每次考试的知识点是有限的,而从这些知识点中可以抽取的相关联的题目数也总是有限的,不同的学生之间所需要的题目会有很大的重复性。
举个例子我们为甲学生因为他考卷上的错误部分抽取了80个题目,有很大的概率其他学生跟甲学生错误的地方会有重复,相对应的题目也会有重复。对于这部分题目,我们是完全没有必要重复处理的,包括从数据库中重新获取题目、解析和下载图片。这也是我们可供优化的一大突破点。
其次,一篇练习册是由很多的题目组成的,每个题目相互之间是独立的,我们也可以完全并行的、异步的处理每个题目。
具体怎么做?要避免重复工作肯定是使用缓存机制,对已处理过的题目进行缓存。我们看看怎么使用缓存机制进行优化。这个业务,毋庸置疑,map肯定是最适合的,因为我们要根据题目的id来找题目的详情,用哪个map?我们现在是在多线程下使用,考虑的是并发安全的concurrentHashMap。
当我们的服务接收到处理一个题目的请求,首先会在缓存中get一次,没有找到,可以认为这是个新题目,准备向数据库请求题目数据并进行题目的解析,图片的下载。
这里有一个并发安全的点需要注意,因为是多线程的应用,会发生多个线程在处理多个文档时有同时进行处理相同题目的情况,这种情况下不做控制,一是会造成数据冲突和混乱,比如同时读写同一个磁盘文件,二是会造成计算资源的浪费,同时为了防止文档的生成阻塞在当前题目上,因此每个新题目的处理过程会包装成一个Callable投入一个线程池中 而把处理结果作为一个Future返回,等到线程在实际生成文档时再从Future中get出结果进行处理。因此在每个新题目实际处理前,还会检查当前是否有这个题目的处理任务正在进行。
如果题目在缓存中被找到,并不是直接引用就可以了,因为题库中的题目因为种种关系存在被修改的可能,比如存在错误,比如可能内容被替换,这个时候缓存中数据其实是失效过期的,所以需要先行检查一次。如何检查?
我们前面说过题库中的题目平均长度在800个字节左右,直接equals来检查题目正文是否变动过,明显效率比较低,所以我们这里又做了一番处理,什么处理?对题目正文事先做了一次SHA的摘要并保存在数据库,并且要求题库开发小组在处理题目数据入库的时候进行SHA摘要。
在本机缓存中同样保存了这个摘要信息,在比较题目是否变动过时,首先检查摘要是否一致,摘要一致说明题目不需要更新,摘要不一致时,才需要更新题目文本,将这个题目视为新题目,进入新题目的处理流程,这样的话就减少了数据的传输量,也降低了数据库的压力。
题目处理的流程就变为:
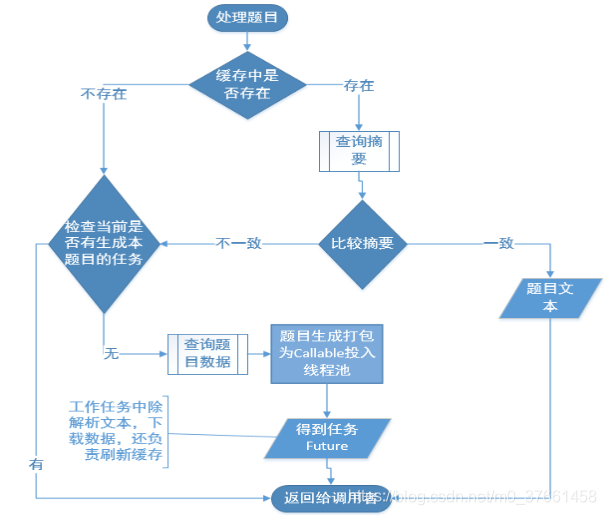
所以我们有了第二次改进,
1)在题目实体类QuestionInDBVo中增加一个
// 题目sha摘要
private final String sha;
2)增加一个题目保存在缓存中的实体类QuestionInCacheVo
public class QuestionInCacheVo {
private final String questionDetail;
private final String questionSha;
3)增加一个并发处理时返回的题目结果实体类TaskResultVo
public class TaskResultVo {
private final String questionDetail;
private final Future<QuestionInCacheVo> questionFuture;
按照我们前面的描述,我们可以得知,题目要么已经处理完成,要么正在处理,所以在获取题目结果时,先从questionDetail获取一次,获取为null,则从questionFuture获取。那么这个类的构造方法需要单独处理一下。
public TaskResultVo(String questionDetail) {
this.questionDetail = questionDetail;
this.questionFuture = null;
}
2.1、在处理文档的服务的类ProduceDocService中增加一个处理文档的新方法makeDocAsyn
public static String makeDocAsyn(SrcDocVo pendingDocVo) throws InterruptedException, ExecutionException {
System.out.println("开始处理文档:"+ pendingDocVo.getDocName());
// 每个题目的处理结果
Map<Integer, TaskResultVo> questionResultMap = new HashMap<>();
for(Integer questionId : pendingDocVo.getQuestionList()) {
questionResultMap.put(questionId, ParalleQstService.makeQuestion(questionId));
}
StringBuffer sb = new StringBuffer();
for(Integer questionId : pendingDocVo.getQuestionList()) {
TaskResultVo taskResultVo = questionResultMap.get(questionId);
sb.append(taskResultVo.getQuestionDetail() == null ?
taskResultVo.getQuestionFuture().get().getQuestionDetail() : taskResultVo.getQuestionDetail());
}
return "complete_"+System.currentTimeMillis()+"_"+ pendingDocVo.getDocName()+".pdf";
}
在这个方法中,会调用一个并发处理题目的方法。
2.2、增加一个优化题目处理的类ParallelQstService,其中提供了并发处理题目的方法,还包括了主程序:
public class ParalleQstService {
// 题目在本地的缓存
private static ConcurrentHashMap<Integer,QuestionInCacheVo> questionCache = new ConcurrentHashMap<>();
// 正在处理的题目的缓存
private static ConcurrentHashMap<Integer,Future<QuestionInCacheVo>> processingQestionCache = new ConcurrentHashMap<>();
// 处理题目的线程池
private static ExecutorService makeQuestionExector = Executors.newCachedThreadPool();
public static TaskResultVo makeQuestion(Integer questionId) {
QuestionInCacheVo questionInCacheVo = questionCache.get(questionId);
if(null == questionInCacheVo) {
System.out.println("题目["+questionId+"]不存在,准备启动");
return new TaskResultVo(getQuestionFuture(questionId));
}else {
String questionSha = SL_QuestionBank.getQuestionSha(questionId);
if(questionInCacheVo.getQuestionSha().equals(questionSha)) {
System.out.println("题目["+questionId+"]在缓存已存在,可以使用");
return new TaskResultVo(questionInCacheVo.getQuestionDetail());
}else {
System.out.println("题目["+questionId+"]在缓存已过期,准备更新");
return new TaskResultVo(getQuestionFuture(questionId));
}
}
}
/**
* 获取题目任务
*/
private static Future<QuestionInCacheVo> getQuestionFuture(Integer questionId) {
Future<QuestionInCacheVo> questionFuture = processingQestionCache.get(questionId);
try {
if(null == questionFuture) {
QuestionInDBVo questionInDBVo = SL_QuestionBank.getQuetion(questionId);
//
QuestionTask questionTask = new QuestionTask(questionInDBVo,questionId);
//不靠谱的做法,无法避免两个线程对同一个题目进行处理
// questionFuture = makeQuestionExecutor.submit(questionTask);
// processingQuestionCache.putIfAbsent(questionId,questionFuture);
// 如果直接改成
// processingQuestionCache.putIfAbsent(questionId,questionFuture);
// questionFuture = makeQuestionExecutor.submit(questionTask);
// 也不行,因为ConcurrentHashMap的value是不允许为null的,那么就需要另做处理
FutureTask<QuestionInCacheVo> ftask = new FutureTask<>(questionTask);
questionFuture = processingQestionCache.putIfAbsent(questionId, ftask);
if(null == questionFuture) {
//当前线程成功了占位了
questionFuture = ftask;
makeQuestionExector.execute(ftask);
System.out.println("当前任务已启动,请等待完成后");
}else {
System.out.println("有其他线程开启了题目的计算任务,本任务无需开启");
}
}else {
System.out.println("当前已经有了题目的计算任务,不必重复开启");
}
return questionFuture;
}catch(Exception e) {
processingQestionCache.remove(questionId);
e.printStackTrace();
throw e;
}
}
/**
* 解析题目的任务类,调用最基础的题目生成服务即可
*/
private static class QuestionTask implements Callable<QuestionInCacheVo> {
QuestionInDBVo questionDBVo;
Integer questionId;
public QuestionTask(QuestionInDBVo questionDBVo, Integer questionId) {
this.questionDBVo = questionDBVo;
this.questionId = questionId;
}
@Override
public QuestionInCacheVo call() throws Exception {
try {
String questionDetail = QstService.makeQuestion(questionId, questionDBVo.getDetail());
String questionSha = questionDBVo.getSha();
QuestionInCacheVo questionInCacheVo = new QuestionInCacheVo(questionDetail,questionSha);
return questionInCacheVo;
}finally {
//无论正常还是异常,均要将生成题目的任务从缓存中移除
processingQestionCache.remove(questionId);
}
}
}
}
3、继续改进
3.1 数据结构的改进
但是我们仔细分析就会发现,作为一个长期运行的服务,如果我们使用concurrentHashMap,意味着随着时间的推进,缓存对内存的占用会不断的增长。最极端的情况,十万个题目全部被加载到内存,这种情况下会占据多少内存呢?我们做了统计,题库中题目的平均长度在800个字节左右,十万个题目大约会使用75M左右的空间。
看起来还好,但是有几点,第一,我们除了题目本身还会有其他的一些附属信息需要缓存,比如题目图片在本地磁盘的存储位置等等,那就说,实际缓存的数据内容会远远超过800个字节。第二,map类型的的内存使用效率是比较低的,以hashmap为例,内存利用率一般只有20%到40%左右,而concurrentHashMap只会更低,有时候只有hashmap的十分之一到4分之一,这也就是说十万个题目放在concurrentHashMap中会实际占据几百兆的内存空间,是很容易造成内存溢出的,也就是大家常见的OOM。
考虑到这种情况,我们需要一种数据结构有map的方便但同时可以限制内存的占用大小或者可以根据需要按照某种策略刷新缓存。最后,在实际的工作中,我们选择了ConcurrentLinkedHashMap,这是由Google开源一个线程安全的hashmap,它本身是对ConcurrentHashMap的封装,可以限定最大容量,并实现一个了基于LRU也就是最近最少使用算法策略的进行更新的缓存。很完美的契合了我们的要求,对于已经缓冲的题目,越少使用的就可以认为这个题目离当前考试考察的章节越远,被再次选中的概率就越小,在容量已满,需要腾出空间给新缓冲的题目时,越少使用就会优先被清除。
3.2 线程数的设置
原来我们设置的线程数按照我们通用的IO密集型任务,两个线程池设置的都是机器的CPU核心数2,但是这个就是最佳的吗?不一定,通过反复试验我们发现,处理文档的线程池线程数设置为CPU核心数4,继续提高线程数并不能带来性能上的提升。而因为我们改进后处理文档的时间和上传文档的时间基本在1:4到1:3的样子,所以处理文档的线程池线程数设置为CPU核心数43。
这时我们有了第三次改进:
public class RpcServiceWebV2 {
// 处理文档生成的线程池 IO密集型 故而大小设置为CPU核心数*2
private static ExecutorService docMakeService = Executors.newFixedThreadPool(Consts.THREAD_COUNT*4);
// 处理文档上传的线程池
private static ExecutorService docUploadService = Executors.newFixedThreadPool(Consts.THREAD_COUNT*4*3);
private static CompletionService<String> docCompletingServcie = new ExecutorCompletionService(docMakeService);
private static CompletionService<String> docUploadCompletingServcie = new ExecutorCompletionService<String>(docUploadService);
3.3 缓存的改进
在这里我们除了本地内存缓存还使用了本地文件存储,启用了一个二级缓存机制。为什么要使用本地文件存储?因为考虑到服务器会升级、会宕机,已经在内存中缓存的数据会丢失,为了避免这一点,我们将相关的数据在本地进行了一个持久化的操作,保存在了本地磁盘。
4、改进后的效果
1)原单WEB串行处理,3个文档耗时
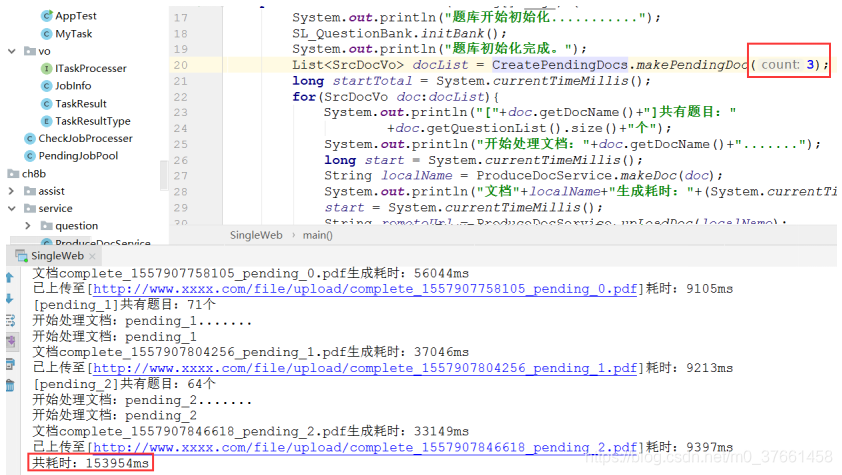
平均一个文档耗时51秒。
2)服务化,文档生成并行化后,60个文档耗时
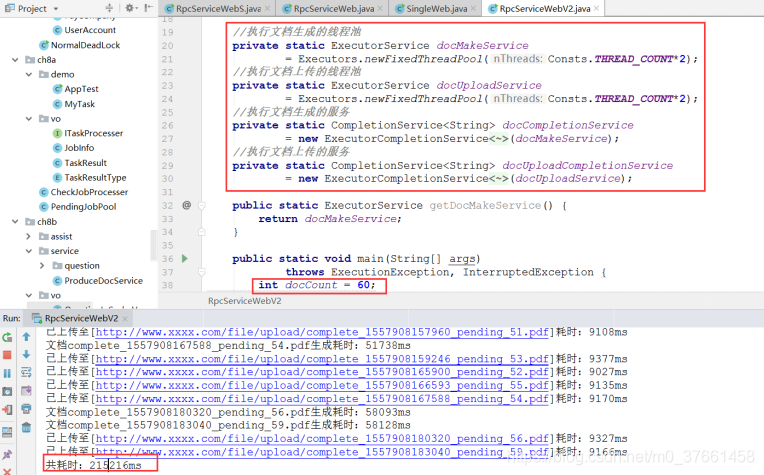
平均一个文档耗时3.5秒,已经比单WEB串行版的实现有了数量级上的提高。
3)引入缓存避免重复工作、题目处理并行和异步化后,60个文档耗时
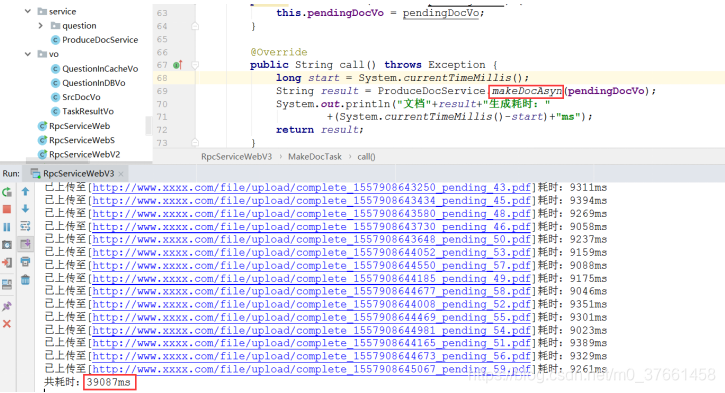
平均一个文档耗时0.65秒,再次有了数量级上的提高。
4)调整线程数后,60个文档耗时
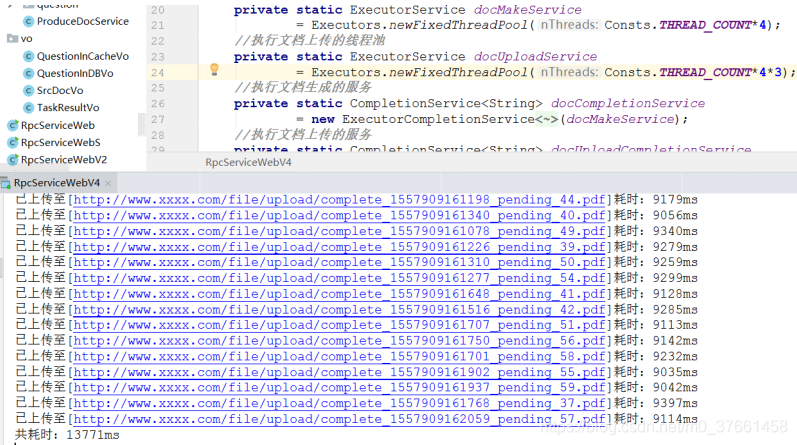
平均一个文档耗时0.23秒,再次提升了3倍的速度,而相对我们第一版的性能而言,平均一个文档处理性能提升了51/0.23=221倍,这就是善用并发编程后威力!
- 用户体验的改进:还可以和我们前面实战的并发任务执行框架中的思想相结合,在前端显示处理进度,給用户带来更好的使用体验。
- 启示:这次项目的优化给我们带来了什么样的启示呢?
性能优化一定要建立在对业务的深入分析上,比如我们在性能优化的切入点,在缓存数据结构的选择就建立在对业务的深入理解上。
性能优化要善于利用语言的高并发特性,性能优化多多利用缓存,异步任务等机制,正是因为我们使用这些特性和机制,才让我们的应用在性能上有个了质的飞跃;引入各种机制的同时要注意避免带来新的不安全因素和瓶颈,比如说缓存数据过期的问题,并发时的线程安全问题,都是需要我们去克服和解决的。