1、阐述Hadoop与Spark的区别?
2、Spark的工作原理是什么?
3、Spark是多线程模式,怎么退化为多进程模式?
4、Hive的特点都有什么
5、Zookeeper的同步过程
6、Hbase存储原理和过程
7、HDFS的写入过程
8、讲解一下scala闭包
9、spark中的shuffle有哪些?
10、HBase的优势,为什么使用了HBase、设计rowkey?
11、spark中几种partitioner?
12、一个application提交运行的过程,画图
13、hdfs create一个文件的流程
14、Yarn架构及其流程
15、mapreduce 第一代架构及其通信
16、Hbase主键设计、hbase为啥比mysql快、为什么项目选用hbase
17、Hbase读写流程,数据compact流程
18、Hadoop mapreduce流程
19、Spark standalone模型、yarn架构模型(画出来架构图)
20、Spark算子(map、flatmap、reducebykey和reduce、groupbykey和reducebykey、join、distinct)原理
21、Spark stage的切分、task资源分配、任务调度、master计算资源分配
22、Sparksql自定义函数、怎么创建dateframe
23、Sparkstreaming项目多久一个批次数据
24、Kafka复制机制、分区多副本机制
25、Hdfs读写流程,数据checkpoint流程
26、Sparkshuffle和hadoopshuffle原理、对比
27、Hivesql怎么转化为MapReduce任务
28、Spark调优
29、Spark数据倾斜解决方案
30、Yarn工作流程、组成架构
31、Zookeeper首领选取、节点类型、zookeeper实现原理
32、hbase的ha,zookeeper在其中的作用
33、spark的内存管理机制,spark1.6前后对比分析
34、spark rdd、dataframe、dataset区别
35、spark里面有哪些参数可以设置,有什么用
36、hashpartitioner与rangePartitioner的实现
37、spark有哪几种join
38、spark jdbc(mysql)读取并发度优化
39、Spark join算子可以用什么替代
40、HBase region切分后数据是怎么分的
41、项目集群结构(spark和hadoop集群)
42、spark streaming是怎么跟kafka交互的,具体代码怎么写的,程序执行流程是怎样的,这个过程中怎么确保数据不丢(直连和receiver方式)
43、kafka如何保证高吞吐的,kafka零拷贝,具体怎么做的
44、hdfs的容错机制
45、zookeeper怎么保证原子性,怎么实现分布式锁
46、kafka存储模型与网络模型
47、Zookeeper脑裂问题
48、mapruduce优缺点?
答:
1、Spark是一种开源的分布式并行计算框架,Spark拥有Hadoop Mapreduce计算框架的优点。但是与Hadoop Mapreduce最大的不同就是:Hadoop Mapreduce分为两个阶段,map 和 reduce,两个阶段完了,就完了,在一个作业里能做的事情很少。而Spark是基于内存迭代计算的,可以分为N个阶段,一个阶段完了可以继续下一阶段的处理,而且Spark作业的中间结果可以保存到内存中,不用再频繁去HDFS或其它数据源读取数据。Spark可以流式的计算数据、而hadoop只能处理静态的数据。
https://www.jianshu.com/p/a78bbf312532
2、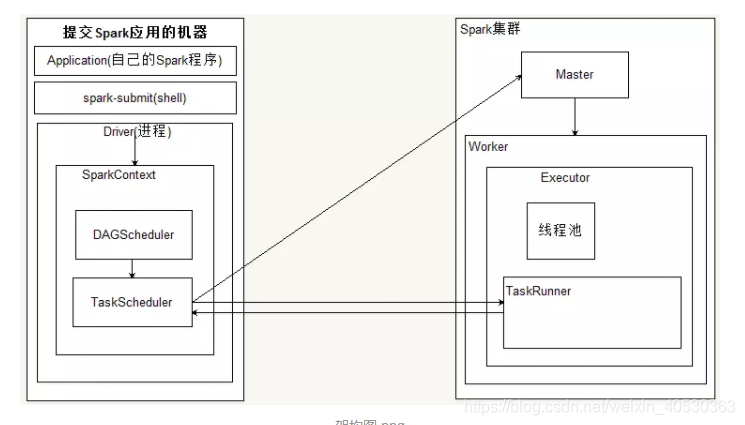
1)spark-submit 提交了应用程序的时候,提交spark应用的机器会通过反射的方式,创建和构造一个Driver进程,Driver进程执行Application程序,
2)Driver根据sparkConf中的配置初始化SparkContext,在SparkContext初始化的过程中会启动DAGScheduler和taskScheduler
3)taskSheduler通过后台进程,向Master注册Application,Master接到了Application的注册请求之后,会使用自己的资源调度算法,在spark集群的worker上,通知worker为application启动多个Executor。
Executor会向taskScheduler反向注册。
4)Driver完成SparkContext初始化
5)application程序执行到Action时,就会创建Job。并且由DAGScheduler将Job划分多个Stage,每个Stage 由TaskSet 组成
6)DAGScheduler(有向图)将TaskSet提交给taskScheduler
7)taskScheduler把TaskSet中的task依次提交给Executor
8)Executor在接收到task之后,会使用taskRunner来封装task(TaskRuner主要将我们编写程序,也就是我们编写的算子和函数进行拷贝和反序列化),然后,从Executor的线程池中取出一个线程来执行task。就这样Spark的每个Stage被作为TaskSet提交给Executor执行,每个Task对应一个RDD的partition,执行我们的定义的算子和函数。直到所有操作执行完为止。
4、
18、
26、https://www.jianshu.com/p/a4a49643c796
48、

