requests请求库
首先需要安装requests请求库
安装requests请求库有两种方法,一种是使用终端cmd的方法去安装requests请求库
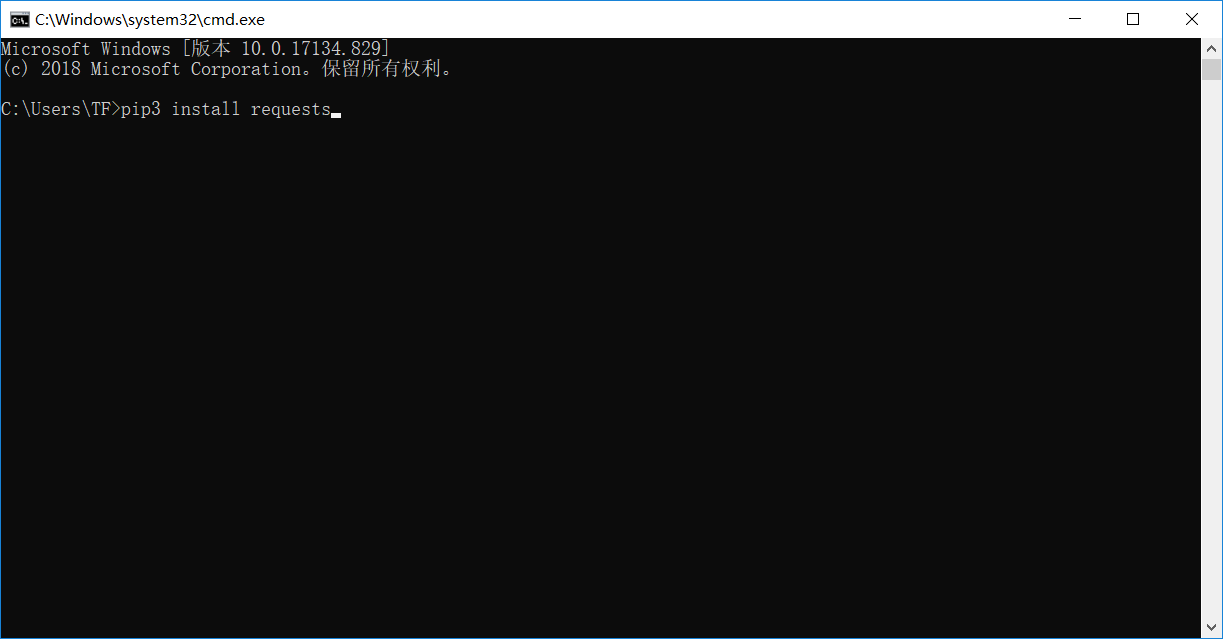
使用pip3 install requests 命令去安装
第二种就是再Pycharm中安装requests请求库
找到File-->setting
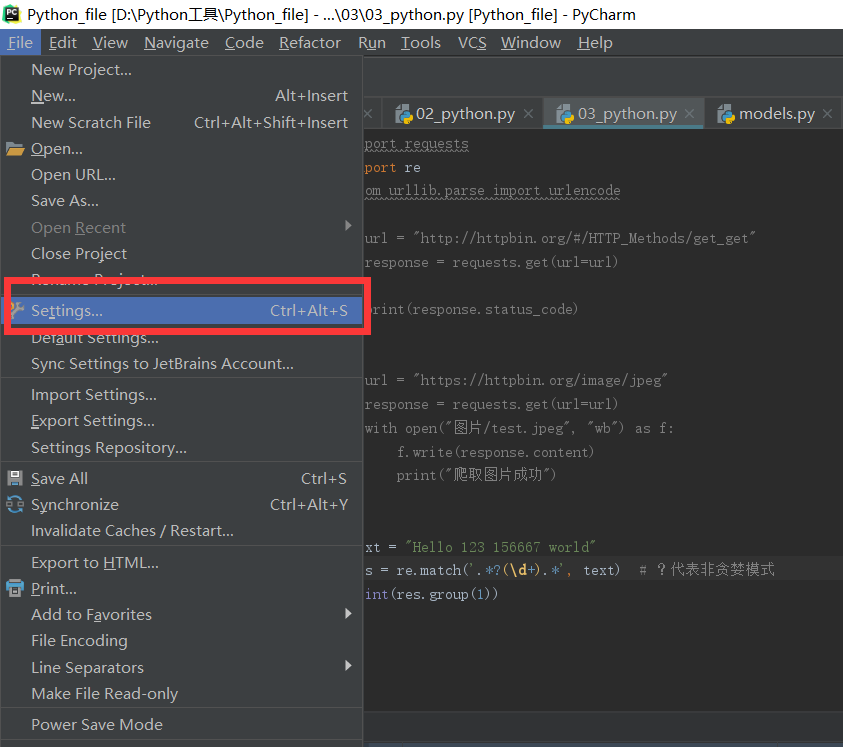
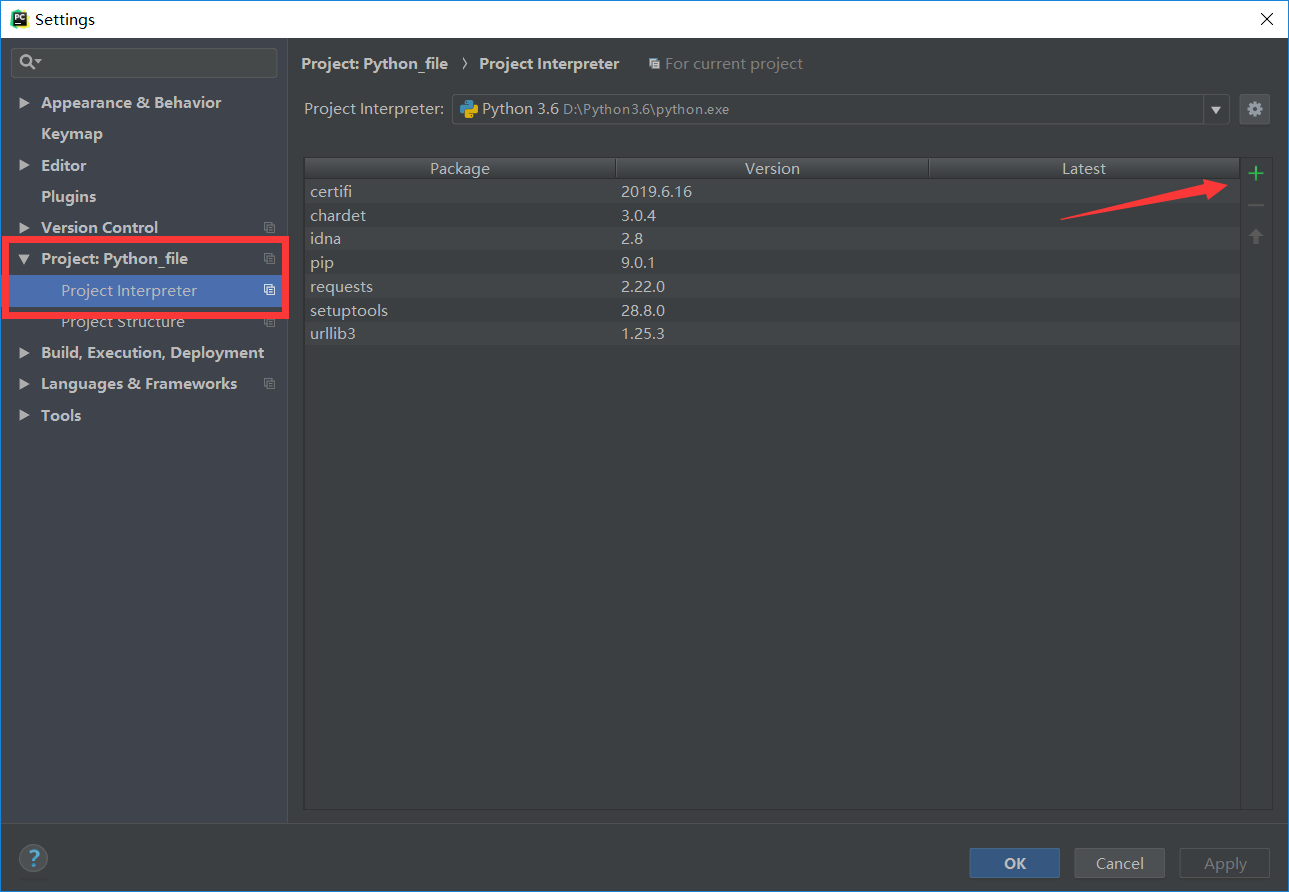
接着安装下图的操作,点击右边的绿色+号,因为我是安装过了,所以已经看到了requests请求库
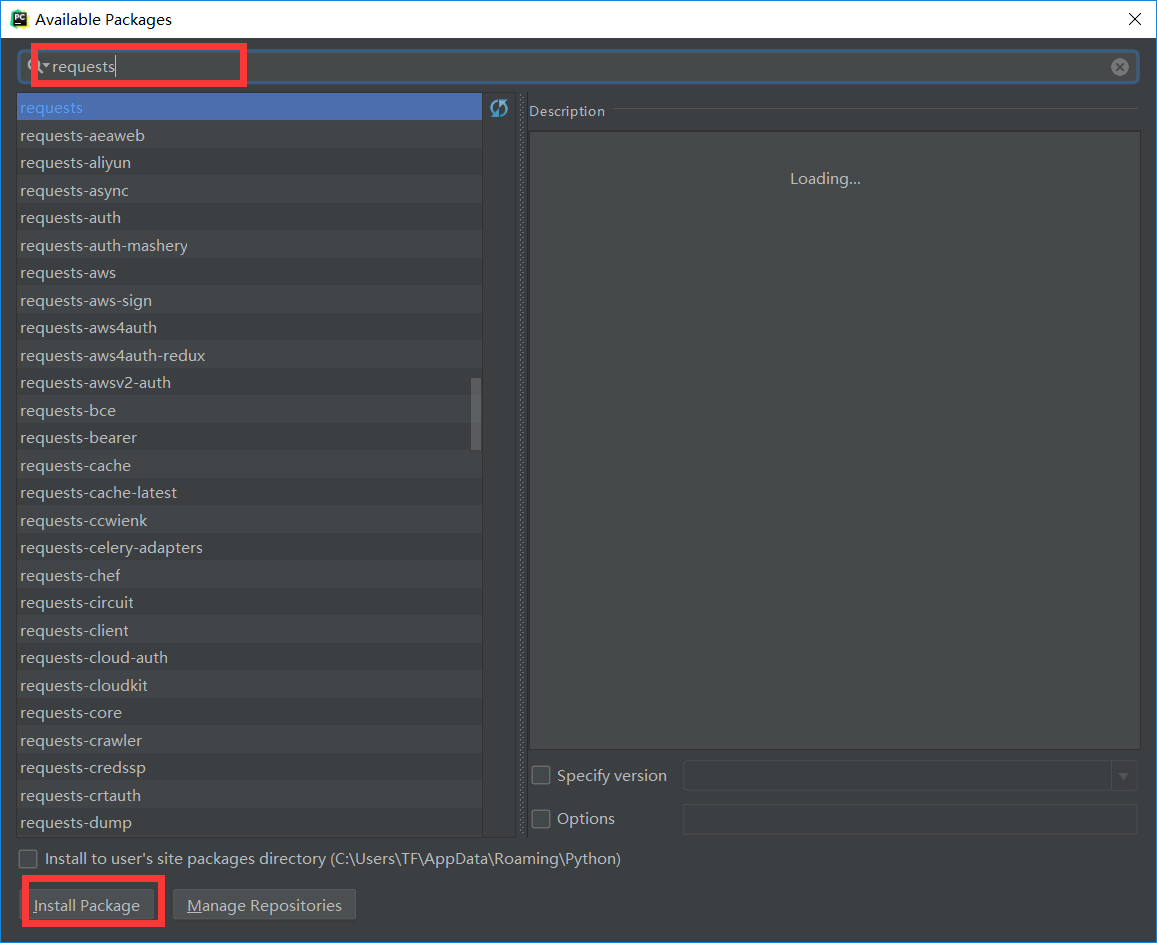
点击+号之后,会出现一个窗口,然后再窗口的搜索栏中搜索“requests”,结果如下图所示。接着点击install就可以完成requests请求库的安装,安装成功之后会有一些信息提示。
安装requests方法如上。
接着就是requests的使用,再python中如果想要使用requests请求库的话,首先要导入requests请求库
import requests
接着如果发送请求的话,我们需要用到requests的get或者post方法,get方法用于get方式访问,post访问用于post访问。
再访问某个页面的时候,会有一些响应数据返回,我们需要使用response去接收这些返回的数据
接下来我们访问百度,并且输出响应体的文档。
# 发送请求并且接收响应的数据打印出响应体 url = "http://www.baidu.com" response = requests.get(url=url) print(response.text)
输出的是百度首先的html文档。
这就完成了一个接单的发送请求并且接收响应数据的过程。
get和post方法的参数比较多,可以根据自己的实际要求去传入某些参数。这里就不一一介绍了。
下面直接去演示一下获取梨视频页面视频的python代码
import requests import re # 获取到梨视频页面所有的video源地址 URL = "https://www.pearvideo.com" response = requests.get(url=URL) # 使用正则表达式去筛选出video的id video_id = re.findall('<a href="video_(.*?)" ', response.text, re.S) # re.S目的是为了去逐行匹配 # 根据video_id去访问每个视频的源地址,再去获取每个视频的真正URL地址 for v_id in video_id: detail_url = "https://www.pearvideo.com/video_" + v_id # 访问每个视频的源地址,获取视频真正地址并获取到每个视频的标题。 response = requests.get(url=detail_url) video_url = re.findall('srcUrl="(.*?)"', response.text, re.S) video_name = re.findall('<h1 class="video-tt">(.*?)</h1>', response.text, re.S) print(video_url) # 访问每个video_url,获取二进制流保存到本地 response = requests.get(url=video_url[0]) with open("图片/%s.mp4" % video_name, "wb") as f: print("开始爬取!") f.write(response.content) print("%s.mp4,爬取完成" % video_name)