我选择tensorFlow作为我学习的第一个神经网络框架,恰巧最近Tensorflow支持了windows,所以让我的学习变得更加便捷。
一、TensorFlow的运行流程
TensorFlow运行流程分为两步,分别是构造模型和训练。
在构造阶段,我们需要去构建一个图(Graph)来描述我们的模型,然后在session中启动它。所谓图,可以理解为流程图,就是将数据的输入输出的过程表示出来
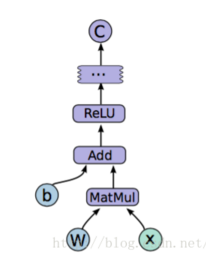
但是此时是不会发生实际运算的,因为TensorFlow是【延迟执行(deferred execution)】模型,它必须知道你要计算什么,你的执行图,然后才开始发送计算任务到各种计算机。所以你首先使用TensorFlow函数在内存中创造一个计算图,然后启动一个执行session并且使用session.run执行实际训练任务,如梯度计算等操作,在此时,图无法被改变。
1.1基本概念
1.1.1 Tensor
Tensor的意思就是张量,我的理解就是一个维数不定的矩阵,也可以理解为tensorflow中矩阵的表示形式,tensor的生成方式有很多种,之后再详细总结,举个例子
-
import tensorflow
as tf
-
a=tf.zeros(shape=[
1,
2])
- 1
注意:在session.run之前,所有数据都是抽象的概念,也就是说,a此时只是表示这应该是一个1*2的零矩阵,但却没有实际赋值,所以如果此时print(a),就会出现如下情况:
-
print(a)
-
#==>Tensor("zeros:0", shape=(1, 2), dtype=float32)
- 1
只有启动session后,才能得到a的值
-
sess=tf.Session()
-
print(sess.run(a))
-
[[
0.
0.]]
- 1
如果你想要系统地学习人工智能,那么推荐你去看床长人工智能教程。非常棒的大神之作,教程不仅通俗易懂,而且很风趣幽默。点击这里可以查看教程。
1.1.2. Variable
当训练模型的时候,要用变量来存储和更新参数,变量包含张量(Tensor)存放于内存的缓存区,建模时它们需要被明确地初始化,模型训练后它们b必须被存储到磁盘。这些变量的值可在之后模型训练和分析时被加载。
如我要计算 y=ReLU(Wx+b)
那么W,b就是我要用来训练的参数,那么这两个值就可以用Variable来表示,Variable初始函数有很多选项,这里先不提,只输入一个tensor也是可以的
W=tf.Variable(tf.zeros((1,2)))
- 1
如果
-
v=tf.Variable(tf.zeros((
1,
2)))
-
sess=tf.Session()
-
#print(sess.run(v)) #会报错,因为没对变量初始化
-
sess.run(tf.initialize_all_variables())
#对所有变量初始化
-
print(sess.run(v))
- 1
就会输出[[0. 0.]]
有时,还可以用另一个变量的初始化值给当前变量初始化。由于 tf.initialize_all_variables() 是并行地初始化所有变量,所以在有这种需求的情况下需要小心。
-
# Create a variable with a random value.
-
weights = tf.Variable(tf.random_normal([
784,
200], stddev=
0.35),
-
name=
"weights")
-
# Create another variable with the same value as 'weights'.
-
w2 = tf.Variable(weights.initialized_value(), name=
"w2")
-
# Create another variable with twice the value of 'weights'
-
w_twice = tf.Variable(weights.initialized_value() *
0.2, name=
"w_twice")
- 1
1.1.3.placeholder 占位符
同样也是一个抽象的概念,用于表示输入输出数据的格式,告诉系统:这里有一个值/向量/矩阵,现在我没发给你具体数值,不过我正式运行的时候会补上,一般都是要从外部输入的值,例如例子中的x和y,因为没有具体数值,只要指定尺寸就可以
-
x=tf.placeholder(tf.float32,[
1,
5],name=
'input')
-
y=tf.placeholder(tf.float32,[
None,
5],name=
'input')
- 1
y表示一个输入为【?,5】的矩阵,None就代表输入的批数,当需要输入一批为5个时,那么就是【5,5】的矩阵,tensorflow会自动进行批处理。
注意:设计placeholder节点的唯一意图就是为了提供数据供给(feeding)的方法。placeholder节点被声明的时候是未初始化的,也不包含数据,如果有为它供给数据,则Tensorflow运算的时候会产生错误
1.1.4.Session 会话
Session就是抽象模型的实现者,具体的参数训练,预测,甚至是变量的实际值查询,都要用到session
1.2模型构建
这里先说官方最基础的MNIST数据集单层网络例子
(1)读入数据
-
from tensorflow.examples.tutorials.mnist
import input_data
-
import cv2
-
import numpy
as np
-
-
#mnist = input_data.read_data_sets("mnist_data/", one_hot=True)
-
mnist = input_data.read_data_sets(
"C:\\Users\\1\\AppData\\Local\\Programs\\Python\Python35\\Lib\\site-packages\\tensorflow\\examples\\tutorials\\mnist", one_hot=
True)
-
import tensorflow
as tf
- 1
此处我是直接从官网 下的mnist数据集,因为官网指导上那个代码我用不了
(2) 建立抽象模型
-
x = tf.placeholder(tf.float32, [
None,
784])
-
#W = tf.Variable(tf.random_normal([784, 10], stddev=0.1))
-
W = tf.Variable(tf.zeros([
784,
10]))
-
b = tf.Variable(tf.zeros([
10]))
-
-
y = tf.nn.softmax(tf.matmul(x, W) + b)
-
y_ = tf.placeholder(
"float", [
None,
10])
-
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
-
train_step = tf.train.GradientDescentOptimizer(
0.01).minimize(cross_entropy)
-
init = tf.global_variables_initializer()
- 1
对输入x,label y_创建一个占位符,以及声明W,b变量,通过softmax得到预测结果y
定义损失函数cross_entropy,训练方法(梯度下降)train_step
(3)实际训练
-
sess = tf.InteractiveSession()
-
sess.run(init)
-
for i
in range(
10000):
-
batch_xs, batch_ys = mnist.train.next_batch(
100)
-
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
-
-
if i %
500==
0:
-
correct_prediction = tf.equal(tf.argmax(y,
1), tf.argmax(y_,
1))
-
accuracy = tf.reduce_mean(tf.cast(correct_prediction,
"float"))
-
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}, session=sess))
- 1
在模型搭建完成以后,我们只要为模型提供输入和输出,模型就能够自己进行训练和测试,中间的求导,求梯度,反向传播等等,TensorFlow都会帮你自动完成。结果最终为0.92
二、5层全连接神经网络
1.首先定义每层的神经元个数
K=400
L=100
M=60
N=30
2.搭建模型
-
W1=tf.Variable(tf.truncated_normal([
28*
28,K],stddev=
0.1))
-
B1=tf.Variable(tf.zeros([K]))
-
W2=tf.Variable(tf.truncated_normal([K,L],stddev=
0.1))
-
B2=tf.Variable(tf.zeros([L]))
-
W3=tf.Variable(tf.truncated_normal([L,M],stddev=
0.1))
-
B3=tf.Variable(tf.zeros([M]))
-
W4=tf.Variable(tf.truncated_normal([M,N],stddev=
0.1))
-
B4=tf.Variable(tf.zeros([N]))
-
W5=tf.Variable(tf.truncated_normal([N,
10],stddev=
0.1))
-
B5=tf.Variable(tf.zeros([
10]))
-
-
X=tf.placeholder(tf.float32,[
None,
28,
28,
1])
-
y_=tf.placeholder(tf.float32,[
None,
10])
#hot-vector的形式
-
X=tf.reshape(X,[
-1,
28*
28])
-
Y1=tf.nn.relu(tf.matmul(X,W1)+B1)
-
Y2=tf.nn.relu(tf.matmul(Y1,W2)+B2)
-
Y3=tf.nn.relu(tf.matmul(Y2,W3)+B3)
-
Y4=tf.nn.relu(tf.matmul(Y3,W4)+B4)
-
pred=tf.nn.softmax(tf.matmul(Y4,W5)+B5)
-
-
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y_))
-
train_step=tf.train.GradientDescentOptimizer(
0.03).minimize(loss)
-
corr=tf.equal(tf.argmax(pred,
1),tf.argmax(y_,
1))
#找到每行最大的作为输出结果
-
accu=tf.reduce_mean(tf.cast(corr,tf.float32))
-
init=tf.global_variables_initializer()
- 1
3.训练
-
sess=tf.InteractiveSession()
-
sess.run(init)
-
for i
in range(
10000):
-
batch_xs, batch_ys = mnist.train.next_batch(
100)
-
sess.run(train_step, feed_dict={X: batch_xs, y_: batch_ys})
-
if i %
100 ==
0:
-
print(
"测试集正确率:%f" %accu.eval(feed_dict={X:mnist.test.images,y_:mnist.test.labels},session=sess))
- 1
最终得到的测试集准确率为:0.884
该结果还没有单层softmax效果好,目前还不知道为什么····