第一周 卷积神经网络
1.计算视觉(Computer vision)
-
Deep learning在计算视觉的研究可以启发很多领域,包括语音识别等
-
计算视觉任务:
- 图片分类(Image classification)
- 目标检测(Object detection)
- 风格迁移(Neural style transfer)
-
计算机视觉面临输入数据大挑战带来两个问题,一是神经网络复杂,参数多,容易发生过拟合。二是计算量大需要内存大。所以使得卷积神经网络(CNN)应运而生。
2.边缘检测示例(Edge detection example)
-
卷积运算是卷积神经网络最基本的组成部分
-
卷积运算:实际就是用filter(过滤器)对原图区域每个值相乘求和,实现将原图保留边缘特征的降维。以垂直边缘检测为例,原始图片尺寸为
6x6,过滤器filter尺寸为3x3,卷积后的图片尺寸为4x4,得到结果如下:(注意这里的*表示卷积运算,跟乘法无关,python中,卷积用conv_forward()表示;tensorflow中,卷积用tf.nn.conv2d()表示;keras中,卷积用Conv2D()表示。)
-
为什么卷积可以检测边缘?
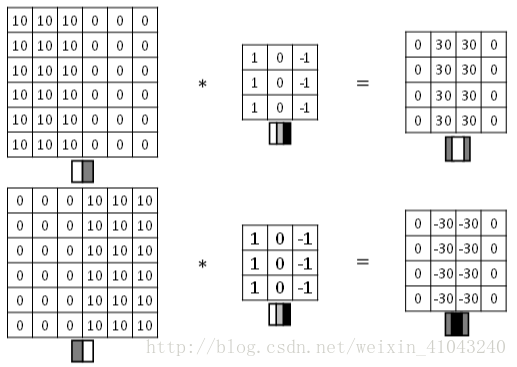
举一个简单的例子,下图最左是原图,可以看出中间有一个明显的竖线,经过卷积得到的图像中间就表示原图的边缘。这里看边缘有些粗,是因为我们的图像太小了,应用到正常图像会发现其检测的边缘相当不错。
-
下图展示了两种方式的区别,第一个称为正边,表示图片有亮到暗,第二个称为负边,表示图片由暗到亮。实际应用中,这两种渐变方式并不影响边缘检测结果,如果不在意这种区别的话,可以对输出图片取绝对值操作。
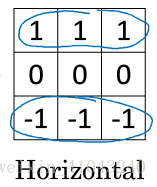
水平边缘检测的过滤器算子如下所示:
-
除了上面提到简单的Vertical、Horizontal滤波器之外,研究者提出的常见filter有 Soble,Schor等,这两种滤波器的特点是增加图片中心区域的权重。
但在深度学习里,复杂图像的边缘检测可以选择把filter中的值也当成神经网络的参数进行训练。学习获得的过滤器可能优于任何一个手写的过滤器,因为相对于水平垂直边缘,它可以检测任意倾斜角度的边缘。



4.Padding(填充)
-
如果有原图为
nxn,filter(过滤器大小为fxf,则一次卷积操作后的图大小为(n-f+1)*(n-f+1)。 -
但这样卷积方式会使得图片尺寸缩小很多,同时图像边缘特征被保留很少。于是加入
padding操作去填充边缘p个0,则最后原图大小为(n+2*p-f+1)*(n+2*p-f+1)。 -
如果卷积操作没有填充称为
Vaild卷积,如果卷积前后图像大小不变称为Same卷积, 满足p = (f-1)/2即可。 -
同时一般选择filter(过滤器)大小都是奇数维度。

5.卷积步长(Stride)
-
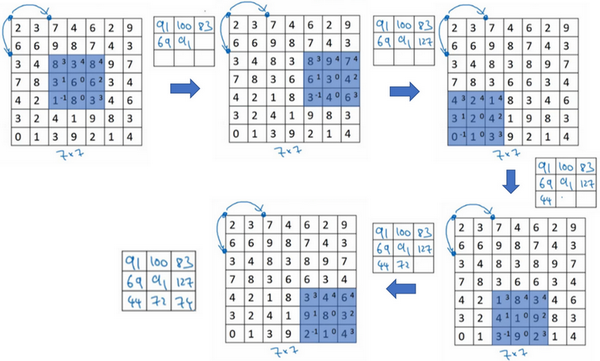
步长决定filter一次移动的距离:
-
如果原图大小为
nxn,padding大小为p,filter为fxf,步长stride为s,则卷积后图像大小为(n+2p-f)/s+1,如果结果不为整数向下取整。这个原则就是,只有当你的过滤器里全部都处于图像或者填充图像以内,才会进行卷积操作。
-
在矩阵上的卷积操作在部分论文和信号处理的书里,会先有将矩阵沿对角线的翻转操作。但对于深度学习来说,这一步不重要。
6.Convolutions Over Volume立体卷积
-
本节以RGB图像上的卷积为例讲述在三维立上的卷积,三维数据在二维数据上增加了通道,令第三维数为图片通道数目,对应的过滤器的通道数目必须和输入图像的通道数目一样,如输入图片是6x6x3,分别表示图片的高度(height)、宽度(weight)和通道(#channel),过滤器通道也必须为3,可以是3x3x3也可以是5x5x3,即尺寸可以按需定制,而通道必须一致。
-
卷积计算过程和二维类似,即用过滤器覆盖原图,对应元素相乘最后相加,然后按步长在图像上移动过滤器,过滤器中不同通道其设计可以一样也可以不一样,例如想检测红色通道的竖线,就设计通道R检测垂直边缘,而G和B通道的过滤器都设置为0。
-
同时卷积的filter选择是根据你的需要选择。有多少个特征需要被检测出来,就可以构建多少个filter,最后将多个结果合成一个多层矩阵。如下图,一个RGB图像经过两个filter卷积生成两个
4x4图像。

7.One Layer of a Convolutional Network单层卷积网络
卷积神经网络的单层结构如下所示:(两个过滤器)
权重W就是过滤器,例中过滤器有27个元素,那么W中就有27个数值待更新,在加上b,参数就是28个,若一层有10个过滤器那么该层总参数就是280个,不论输入图像尺寸为多少,参数都是280个,即参数数目只和过滤器有关,这是CNN特点之一,参数较少有效防止过拟合。


8.Simple Convolutional Network Example简单卷积神经网络
本节通过一个例子介绍简单卷积神经网络的实现流程:

CNN中的隐藏层有三种类型:
- Convolution (CONV) 卷积层
- Pooling (POOL) 池化层
- Fully Connected (FC) 全连接层
9. Pooling Layers 池化层
池化层的作用是减小模型大小,提高计算速度,并提高提取特征的鲁棒性。所以在pooling中一般不用padding填充。它也是通过移动一个类似过滤器的结果完成,不过池化层中的计算不是节点的加权和,而是采用更简单的最大值(max pooling)或者平均值运算(average pooling),前者比后者运用更广泛。
(1) max pooling
pooling跟卷积类似,但是要简单的多,max pooling就是用一个取最大值得滤波器过滤图像。

average pooling就是用一个取均值得滤波器过滤图像,其应用不如max pooling广。
值得注意的是:池化过程中的超参数有滤波器尺寸f和滤波器步进长度s,没有需要学习的参数,也就是反向传播的时候没有参数需要更新。它是一个静态属性。
最常用的池化过滤器超参有两组:f=2 s=2和f=3 s=2

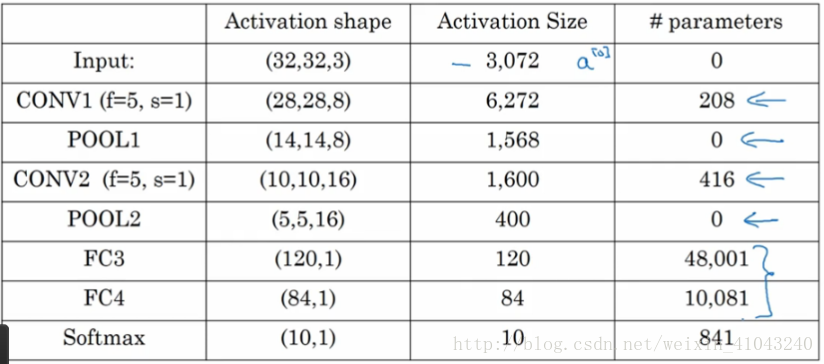
10. CNN Example
图中,CON层后面紧接一个POOL层,共同构成第一层(因为POOL没有需要学习的参数),CONV2和POOL2构成第二层。
特别注意的是FC3和FC4为全连接层FC,它跟标准的神经网络结构一致。最后的输出层(softmax)由10个神经元构成。
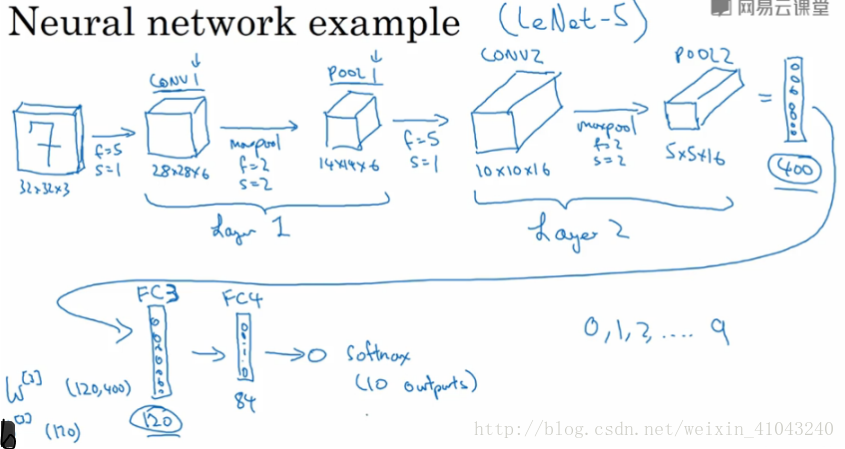
关于超参选择的建议,尽量不要自己设置超参数,而是参考别人文献里面的超参数值。
CNN常用的架构模式是一个或多个CONV后面跟一个POOL,然后继续一个或多个CONV后面跟一个POOL……最后跟几个全连接层,softmax输出。
网络中参数如下图:
11. Why Convolutions?
相对于标准神经网络来说,处理图像的话,卷积网络的参数大大减少,使得我们可以用更小的训练集来训练模型,同时也有效的防止过拟合
为什么要用卷积可以减少参数?
原因有二:参数共享和稀疏连接。
- 参数共享(parameter sharing):一个特征检测器(例如垂直边缘检测)对图片某块区域有用,同时也可能对图片其它区域有用,即不需要添加特征检测器,就可以检测整幅图像的某个特征或者多个相似特征。
- 稀疏连接(sparsity of connection):因为滤波器算子尺寸限制,每个输出仅依赖于滤波器覆盖的那几个特征。
另外CNN比较擅长捕捉平移不变特征。也就是说CNN进行物体检测时,不太受物体所处图片位置的影响。
