1. gdb调试
(1)进入gdb调试:gdb + 可执行文件

(2)l 列出文件内容(默认从main函数开始列)

(3)l + 文件名:行号 列出该文件中该行号处的内容

(4)l + 文件名:函数名 列出该文件中该函数的内容

然后想继续往下看的话,输入 l, 如果接下来还想再往下看,就直接回车即可。

(5)什么都不输入,直接回车,那么就会执行上一次的操作。
(6)设置当前文件断点:break + 行号 或 b + 行号 (下面的实验进行之前已经用 l 查看main.c中的内容了,所以设置断点的行号就是main.c中的行号)

(7)设置指定文件断点:break/b + 文件名:行号
(8)设置条件断点:b + 行号 if i==15
![]()
(9)列出断点信息:i + b

(10)开始执行程序:start (上来只执行一步然后就停下来了,但如果没有设置断点,那么程序将会直接执行完)

(11)n 执行下一步(不进入函数内部)
![]()
(12)s 执行下一步(进入函数内部)

(13)c 继续执行到断点

(14)查看变量的值:p + 变量名

(15)查看变量类型:ptype + 变量名

(16)display + 变量名 追踪变量,之后会一直输出该变量的值。

(17)undisplay + 编号 不追踪该编号对应变量的值了。 (先用info + display 查看编号)

(18)u 跳出循环
![]()
(19)finish 跳出当前函数

如果当前函数中有断点,那么不能跳出,必须先删除当前函数中的断点。(用“d + 断点编号”删除断点)

然后就可以跳出当前函数了:

(20)set + var + i=10 改变程序变量取值,这里将 i 改为10。

(21)quit 退出调试

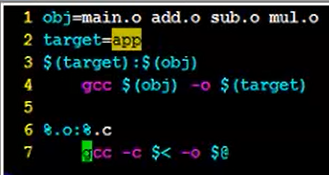
2. 编写一个最简单的makefile
文件的命名只有两种是允许的:makefile 和 Makefile。用vi makefile创建文件:

makefile文件就被创建出来了:
![]()
在makefile文件中写如下内容:

然后使用make命令,就生成了可执行文件app:

总结一下makefile基本原则中的三要素:

用上面写makefile的方式不是特别好:因为如果只改变其中一个.c文件,那么再生成可执行文件app还需要将所有.c文件重新编译,非常耗时,所以我们采用如下方式改写makefile:

然后接下来在make时,第一条规则的目标app的依赖条件没找到,那么会向下查找规则,找到下面的4条规则,他们的目标就是生成那4个依赖条件,于是先执行下面4个规则,最后再执行第一条规则。这样执行结束后就生成了app。
下面是第一次make,可以看到都进行了编译:

然后我们只修改其中一个文件add.c,然后再make:

可以看到只编译了有改动的那个.c文件,然后由于add.o也变了,所以要再链接生成一下app。
由于编译花费的时间长,链接花费的时间短,所以进行这种改进可以提高效率。
3. makefile的工作原理
生成终极目标的规则一定要写到最上面,即第一条规则。否则如果其他规则是第一条规则,那么当它执行完了就结束了,其他的规则就执行不到了。
工作原理如图所示:

只更改其中一个.c文件再make时,不用重新编译所有文件的原因:
更新目标时,检查makefile中的规则,如果某条规则的依赖比目标文件新,那么要执行命令来更新目标文件,比如add.c修改了,那么此条规则的依赖add.c就比目标add.o新了,所以要执行命令更新add.o,然后第一条规则的依赖中add.o也比app新了,所以要执行命令更新app。因此刚才更改add.c文件后再make时,不用重新编译所有的文件。

4. makefile中的变量
(1)普通变量1:自定义变量
例:

(2)自动变量


例:
(3)普通变量2:由Makefile维护的变量

例:

5. makefile中的函数
(1)wildcard:查找指定目录下某种类型的文件,返回值是查找到的所有符合要求的文件名。
(2)patsubst:从参数3里取出的文件中,将与参数1匹配的文件名替换成与参数2匹配的文件名,返回值是与参数2匹配的文件名。
例:

src为main.c add.c sub.c mul.c, obj为main.o add.o sub.o mul.o
在make后如果重新make的话,需要将之前生成的.o文件都删掉。否则会报如下信息:
![]()
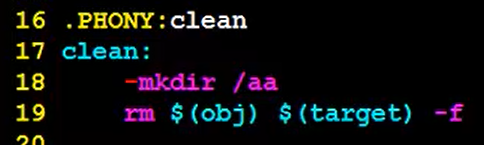
我们可以在makefile中加一条规则:

然后执行make clean,就会只执行在makefile中写的这个目标clean对应的操作:

这样再make就没问题了。
同理,如果在makefile中加一条规则:

然后执行make hello,就会只执行在makefile中写的这个目标hello对应的操作:

如果在make clean之后又make clean了,那么就会报错:

我们可以加参数-f来强制执行命令:

这样再重复make clean的话就不会报错了。
如果在目录中创建一个新文件命名为clean,那么在make clean时会出错:

这是由于clean文件比makefile中的目标clean时间上要新,所以在make clean时会执行不了。但是由于我们并不生成clean这个文件,所以它是个伪目标,但如果我们不声明的话,系统并不知道,把它当成真目标了,所以要检查时间谁更新。因此下面我们要声明它是伪目标:

声明之后系统就不检查时间谁更新了,所以再make clean就没问题了:

如果在命令前面加“-”,那么如果此命令执行失败了,就会忽略这条命令并向下执行。
例:比如加一条会执行失败的命令:

那么就会报错并停止向下执行:

如果在前面加上“-”,那么就会忽略这条命令并向下执行。

6. C库函数

使用fopen函数打开文件,返回值是FILE* fp,其中FILE是一个结构体,里面包含了文件描述符(整型值)、文件读写指针位置(地址)、I/O缓冲区内存地址。通过文件描述符可以索引到对应的磁盘文件;在进行读写文件时,文件读写指针位置用来指示当前实际读写到什么位置了,刚打开文件时,该指针在文件的开头,随着写入的进行,该指针也在向后移动;在读写文件时,我们并不是直接在磁盘上进行读写,而是有一个大小为8kb的I/O缓冲区,我们是将数据先写到这个缓冲区中,然后当发生以下3种情况之一时,数据从内存刷新到磁盘。

7. 虚拟地址空间
当一个程序执行起来之后,就会有一个进程。对于32位的电脑来说,每一个进程,操作系统都会为其分配一个0~4G的虚拟地址空间,该空间分为两部分:0~3G的用户区和3~4G的内核区,用户区就是给我们使用的,内核区我们是访问不到的,不允许我们用户去操作。内核区有一个PCB进程控制块,在PCB进程控制块里有一个大小为1024的文件描述符表,他是一个数组,0~1023的每一个位置都代表能打开一个文件。每打开一个文件,就在文件描述符表中占用一个位置。一个进程供我们用户能打开的最多只有1021个文件,因为默认0,1,2总是处于被打开的状态,分别是标准输入、标准输出、标准错误。当我们打开一个新文件时,则占用一个文件描述符,而且占用的是当前空闲的编号最小的一个文件描述符。每一个文件描述符都对应一个打开的文件。

Linux下可执行文件的格式为ELF。程序执行起来后,操作系统为其分配一个0~4G的虚拟地址空间。虚拟地址空间中包含有很多段,下面一个一个来说:
data段、bss段、text段和其他段是属于ELF的。全局变量为0说明其没有被初始化,所以data段保存的已初始化全局变量肯定都是不等于0的,bss段保存的未初始化的全局变量都是等于0的。text代码段保存的是执行的代码。此外ELF中还有其他段,包括只读数据段和符号段。
0~4k受保护的地址是不允许我们用户去访问的,当我们写程序时,初始化一个指针等于NULL,其实他是一个宏定义: #define NULL (void*) 0,该指针指向的地址就是这个受保护的地址。
局部变量保存在栈空间中。在栈空间上分配地址的时候,是向下增长的。局部变量从上面先开辟一块空间,然后如果再定义一个局部变量,那么就再往下开辟一块空间。所以是向下增长的。
堆空间上分配地址的时候,是向上增长的。malloc一块空间是先从下面开辟,然后如果再malloc一块空间,那么就再往上开辟一块空间。所以是向上增长的。
当我们调用一个C标准函数或linux系统函数,其实我们调用的是动态库。当我们调用一个C标准函数或linux系统函数时,就会加载动态库,把它放到共享区中,共享区中哪里空闲,就会把我们的库加载到什么位置。所以起始位置是不定的,所以我们生成动态库时,就要生成一个与位置无关的代码。也就是说这个代码放的是在库中的相对地址,找代码时是在共享区中加载共享库的位置偏移几个位置来找代码。把共享库加载到哪了,就从哪里往后读,比如读10个字节,就读到了我们要找的代码位置。通过这个相对地址,我们就能非常准确的找到对应的代码。比如偏移10个字节,就能找到加法运算的那个函数,偏移3个字节就能找到减法运算的函数。静态库就不一样了,它被打包到了可执行文件里面,那么这些函数的代码就被直接放到了代码段。因为每次程序启动都会分配一个0~4G,所以每次放的位置都是一样的,比如加法运算的函数这次被放到1000的位置,那么下次还是放到1000的位置,这是因为在打包的时候,用的就是绝对地址。通过这个绝对地址,每次往虚拟内存空间里放的时候,就会放到代码段对应的位置,是固定的。
有一块空间专门用来保存命令行参数,比如main函数传入的命令行参数。
还有一块用来保存当前进程所有的环境变量。
以上都是在0~3G的用户区中。


注:给进程分配的0~4G的虚拟地址空间只是说提供4个G的空间供进程使用。实际上物理内存被占用了多少取决于在虚拟地址空间中实际用了多少。并不是说每有一个进程产生,物理内存就少了4个G。必须是在虚拟地址空间中存满了4个G的数据,物理内存才会少4个G。
8. C库函数与系统函数的关系
当执行printf时,是要调用linux系统的API的。首先要调用应用层的函数write,这些应用层的函数操作的是0~3G用户空间,write函数会做一个空间的转换,从用户空间到内核空间的转换。在内核空间有系统调用sys_write(),这个函数就可以对内核区3~4G的空间做操作了。该函数会调用设备驱动函数,从而通过设备驱动操作硬件。

9. open函数介绍

open函数有两个,对应着不同的应用场景。
第一个有2个参数的是只能打开已经存在的文件。第一个参数是文件的路径,第二个参数是我们指定的打开方式。
第二个有3个参数的是可以打开并不存在的文件,第一个参数是文件的路径,第二个参数是我们指定的打开方式,第三个参数是指定文件的权限。
open函数的返回值是文件描述符。如果发生错误时返回-1,并且全局变量errno会设置为相应的值以示错误信息。

10. open函数中的errno


(上面两张图片组合为一张)
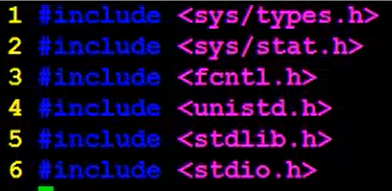
11. open函数的使用
下面头文件中的前3个是我们在使用open函数的时候要加的。第4个头文件是使用close函数要加的。第5个头文件是使用exit函数要加的。最后一个头文件是使用perror函数要加的。
close函数的使用:
![]()
解释:fd是文件描述符,函数的返回值如果是0,说明关闭成功,如果是-1,说明关闭失败。
例1:有2个参数的open函数,其中bucunz文件是不存在的,打开方式是读写。

执行结果:
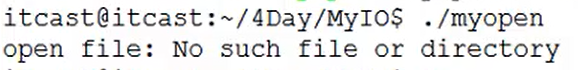
然后我们将bucunz改为一个已存在的文件,然后执行结果如下:
![]()
例2:有3个参数的open函数,其中myhello文件是不存在的,打开方式是读写+创建,权限设为777。

执行结果:
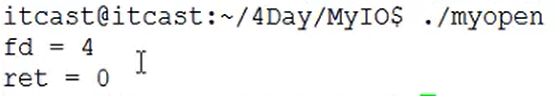
然后我们查看myhello文件的权限:
![]()
发现并不是我们设的777,而是775。这是由于本地有一个掩码,我们用umask命令查看掩码:

myhello文件的权限实际为:将掩码取反,然后和我们设定的权限参数进行按位与,得到的就是实际的权限,所以实际的权限是775。
我们可以对掩码进行临时的修改:

open函数还可以用来判断文件是不是已经存在了,只需再或上O_EXCL:

执行结果:

open函数还可以将文件截断为0,也就是将文件清空,用O_RDWR | O_TRUNC:

执行结果:
![]()
执行程序之前,myhello文件中是有内容的,执行程序后,可以看到myhello文件被清空了。
12. read和write函数
(1)read函数:
![]()
ssize_t其实就是有符号整型。fd是文件描述符,buf是用户提供的缓冲区的首地址,count是缓冲区的大小。
read函数的返回值:

(2)write函数:
![]()
ssize_t其实就是有符号整型。fd是文件描述符,buf是用户提供的缓冲区的首地址,count是缓冲区的大小。
write函数的返回值:如果返回>0表示已经写入的字节数,如果返回0说明没有写入,如果返回-1说明出现了错误。