一: Mysql参数优化
1.查看mysql参数最大连接
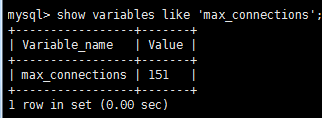
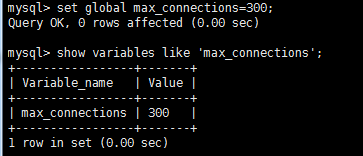
调大mysql参数连接(最大可设置12384)
2.查看所有进程,无用的kill掉
3.查看当前被使用的连接
show global status like 'max_connections';
二:使用查询缓存优化查询
1.大多数mysql服务器都开启了查询缓存,这是提高性能的有效方法之一,而且是被mysql引擎处理的,当有很多相同的查询被执行了多次的时候,这些查询结果会被放入一个缓存中,这样后续的相同查询就不用操作而直接访问缓存结果了。
所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
比如 select username from table where date='2018-04-25' 就要比select username from table where date =CURDATE(); 要好
2.使用explain关键字检测查询
使用EXPLAIN关键字可以使我们知道MySQL是如何处理SQL语句的,这样可以帮助我们分析我们的查询语句或是表结构的性能瓶颈;EXPLAIN的查询结果还会告诉我们索引主键是如何被利用的,数据表是如何被被搜索或排序的....等等。语法格式是:EXPLAIN +SELECT语句;
使用explain语句


创建普通索引/删除索引


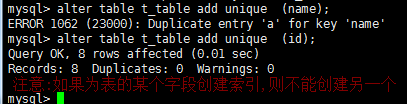
创建唯一索引/删除唯一索引(注意:删除唯一索引是要删除索引所在的字段)

创建主键索引/删除主键索引
mysql> alter table t_table add primary key(id);
mysql> alter table t_table drop primary key;
第二条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list) CREATE UNIQUE INDEX index_name ON table_name (column_list)
查看索引(也可以用show keys from 表名字);

Non_unique:如果索引不能包括重复词,则为0.如果可以,则为1.
Seq_in_index:索引中的序列号,从1开始.
collation:列以什么方式存储在索引中。在MySQL中,有值‘A'(升序)或NULL(无分类)。
Cardinality:索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
NUll:如果列含有NULL,则含有YES。如果没有,则该列含有NO.
Index_type:用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
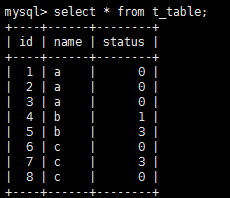
组合索引:组合索引又称多列索引,就是建立索引时指定多个字段属性。有点类似于字典目录,比如查询 'guo' 这个拼音的字时,首先查找g字母,然后在g的检索范围内查询第二个字母为u的列表,最后在u的范围内查找最后一个字母为o的字。比如组合索引(a,b,c),abc都是排好序的,在任意一段a的下面b都是排好序的,任何一段b下面c都是排好序的

下图中三个索引顺序中间没有断点,全部发挥作用,注意:即使是说顺序打乱也不影响,因为联合索引主要发挥作用的前提是在于是否全部用上,而非顺序.
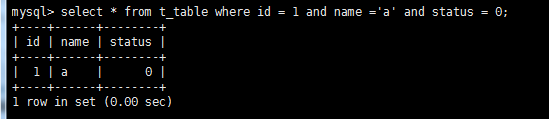
这种情况就是id发挥了作用 status没有发挥作用,此时name就是断点.
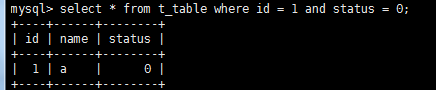
这种情况id就是断点 则name和status都没有发挥作用

此外:对于普通索引而言,在使用like进行通配符模糊查询时,如果首尾之间都使用了通配符,索引是无效的。
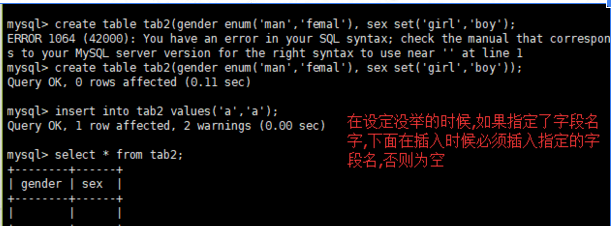
9.尽可能不要赋值为null,
10.设置固定长度的表,因为固定长度的表是很容易计算一个偏移量的,固定长度的字段会浪费一些空间,因为定长的字段无论我们用不用,他都是要分配那么多的空间。另外在取出值的时候要使用trim去除空格.
11.列类型设置的越小就越快,这样减少了对硬盘的访问,如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果我们不需要记录时间,使用 DATE 要比 DATETIME 好得多。
12.选择正确的存储引擎
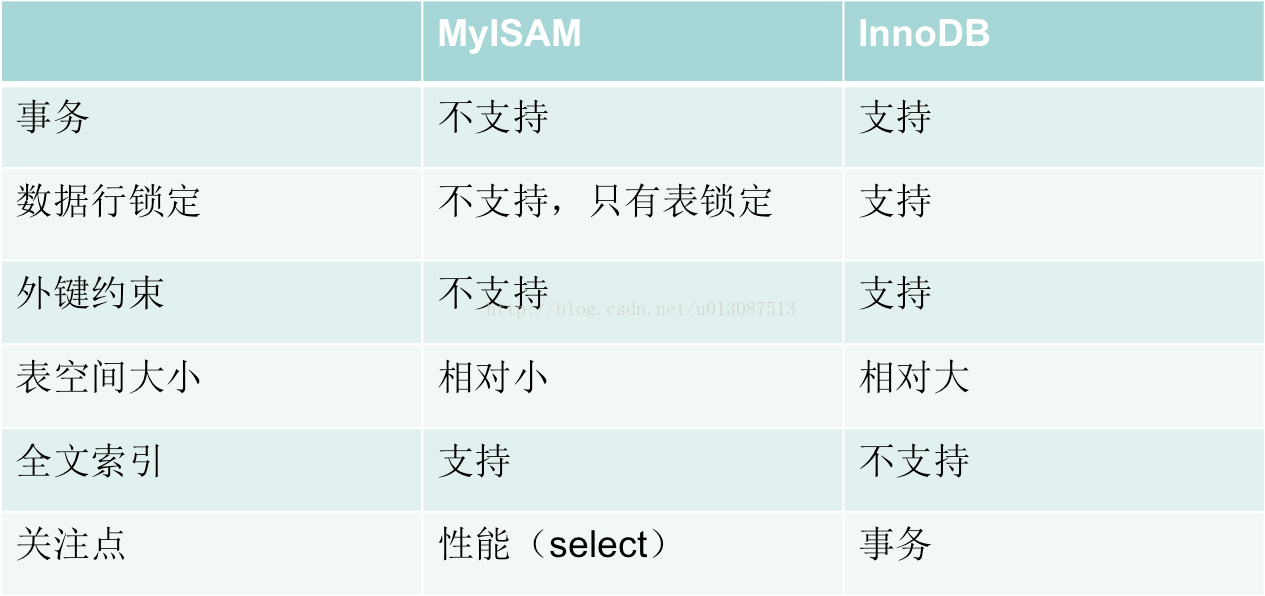
以上就是常用的Mysql优化,如大家有其他的优化方式,欢迎留言!