前言
当前的存储技术虽然已经取得了巨大的发展,一块小小的U盘就已经能够存储128G,但是随着智能设备的发展,ipv4都已经不够用了.存储技术也已经越来越显得捉襟见肘.
需求上来了,硬件跟不上也要解决呀
硬件上需要有突破,软件上也需要有相应的跟进,目前的面对大数据的解决方案是通过分布式的存储技术来破除硬件上的限制,当然这样做也有助于对提升对数据计算能力
本文将从现在存储技术解决方案进行讲解
数据获取
Google一天产生的数据都是按照PB计算的
特点
现代的数据具有4v的特点
1 volumn //体量大
2 variaty //样式多
3 Velocity //速度快
4 Valueless //价值密度低
不管数据有多大 数据采取什么结构 来源如何
只要能够带来价值,都会想办法进行处理
好比一块一块小石头也能筑起长城一样
数据采集方法
▷系统日志采集方法
很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如Hadoop的Chukwa,Cloudera的Flume,Facebook的Scribe等,这些工具均采用分布式架构,能满足每秒数百MB的日志数据采集和传输需求。
▷网络数据采集方法
网络数据采集是指通过网络爬虫或网站公开API等方式从网站上获取数据信息。
该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。
它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联
▷数据库采集系统
对于企业生产经营数据或学科研究数据等保密性要求较高的数据,可以通过与企业或研究机构合作,使用特定系统接口等相关方式采集数据
数据清洗
数据获取之后还需要进行数据清洗工作,也即是剔除"脏数据"
构建业务模型,在确定特征向量以后,都需要准备特征数据在线下进行训练、验证和测试。同样,部署发布离线场景模型,也需要每天定时跑 P 加工模型特征表。
而这一切要做的事,都离不开数据清洗,业内话来说,也就是ETL 处理(抽取 Extract、转换 Transform、加载 Load),三大法宝。
大数据挖掘更多时间都在于清洗数据
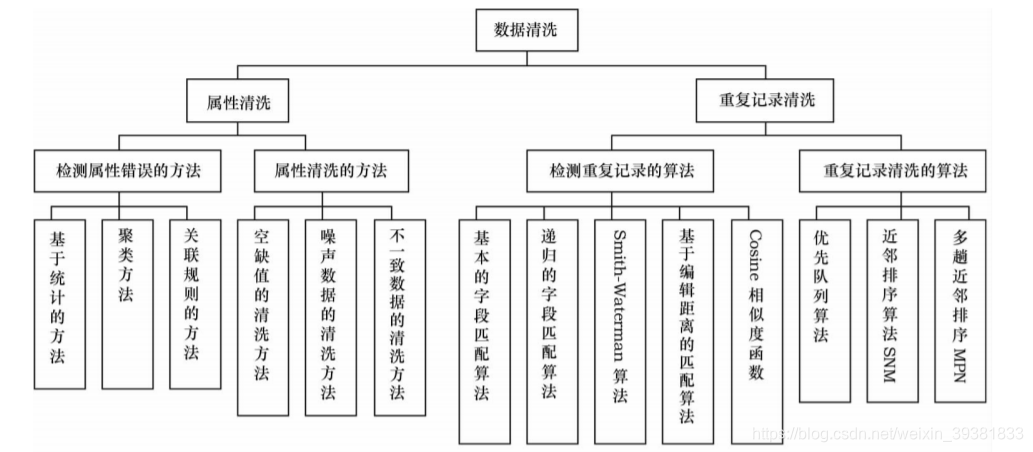
清洗对象
现在所做的数据清洗主要集中在以下四个方面:
(1)检测并消除数据异常
消除异常的数据
(2)检测并消除近似的记录
对重复的数据清洗
(3)数据的集成
将数据源中的结构和数据映射到目标结构与域中
(4)特定领域的数据清洗
针对问题进行特定的数据清洗
清洗方法
(1)手工实现
(2)编程实现
(3)针对特定领域问题
(4)无关数据剔除
数据清洗方法具体分体:
数据存储
数据经过清洗后就需要进行存储
但是当前除了少数互联网科技公司有内部自定义的数据库存储外
在数据存储领域传统的关系型数据库(RDBMS)还是占据了主流
RDBMS设计的主要思想还是30年前形成的,主导思想是OLAP,现在市场基本被Orcale垄断
联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
对比如下:
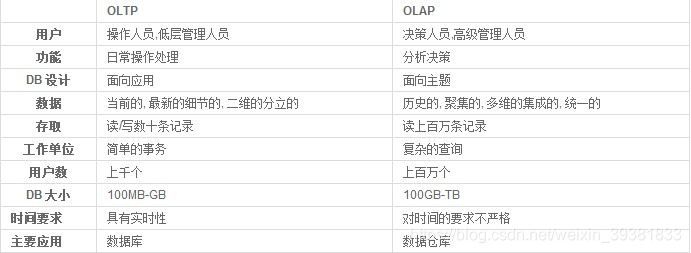
可以看出 OLAP已经越来越不能满足当代数据存储的要求了
一方面是单个服务器存储容量的进步远远小于数据的增长
另外一方面是CPU等硬件对数据的运算能力也已经赶不上数据的增长速度
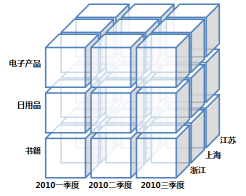
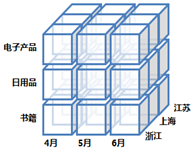
我们以商业智能FineBI来分析。其提供了常见的OLAP多维分析操作,对于用户,可以对已有的表样切换维度来进行数据钻取分析。同时支持对数据的排序与过滤功能,按照自身需求对数据分析处理。
数据钻取分析包括:向上钻取,向下钻取,切片,切块以及旋转
向上钻取是指在莫一卫队上将底层次的细节数据概括到高层次的汇总,向下钻取则是增加维度
举例说明:

采用OLAP的多为数据源有数据方提供,数据仓库也是一种比较昂贵的解决方案,现在主流的多是采取基于Hadoop技术构建的海量数据处理平台, 核心还是基于Hadoop来构建数据方.
HDFS存储原理
庞大的数据进去到HDFS系统前需要先进行切块(block)操作
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS的块比磁盘的块大(磁盘的块一般为512字节),其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。但是很多情况下HDFS使用128MB的块设置。块的大小:10ms100100M/s = 100M,然而真正实际开发中要把block设置的远大于128MB,比如存储文件是1TB时,一般把Block大小设置成512MB.但是也不能任意设置的太大,比如200GB一个,因为在MapReduce的map任务中通常一次只处理一个块中数据(切片大小默认等于block大小),如果设置太大,因为任务数太少(少于集群中的节点数量),那么作业的运行速度就会慢很多,此外比如故障等原因也会拖慢速度。
虽然HDFS以block块存储,对于大文件会被切分成很多以块大小的分块进行存储,但是如果文件小于HDFS的块大小,那么该文件的存储不会占用整个块的空间。比如一个10MB的文件,存储虽然在一个128MB的块上,但是该文件实际只用了10MB的空间,而不是128MB的空间
通常datanode从磁盘上读取块,但是对于频繁访问的数据块,datanode会将其缓存到dataNode节点的内存中,以堆外块缓存的形式(off-heap block cache )存在。默认情况下,一个块只缓存到一个datanode内存中(加入复本是3个,但是也只在一个datanode内存中缓存块)。这样的话,计算框架,比如MR或者Spark就可以在缓存块的节点上运行计算任务,可以大大提高读操作的性能,进而提高任务的效率。
块缓存机制
用户也可以通过在缓存池(cache pool) 中增加一个cache directive 来告诉namenode需要缓存哪些文件,以及文件缓存多久,所谓缓存池就是一个用于管理缓存权限和资源使用的管理分组
HDFS写入到硬盘中的过程
首先在内存中打开一个DFSOutputStream流,Client会写一个块数据到流内部的一个缓冲区中,然后块被分解成多个Packet,每个Packet大小为64k字节,每个Packet又分成chunk 和对应的校验数据checksum,默认chunk大小512字节.
当Client写入的字节流数据达到一个Packet的长度,Packet便会创建出来,然后放入队列dataQueue中,DataStreamer线程会不断冲dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将Packet从dataQueue队列中移动到ackQueue队列中.ResponseProcessor线程接受从Datanode发送过来的ack,成功接受ack后,复制PipeLine中的所有Datanode都已经接受到这个Packet,ResponseProcessor线程将packet从队列ackQueue中剔除.数据成功写入到Datanode的硬盘中
如果在发送过程中发生错误,所有未完成的Packet都会从ackQueue队列中剔除,重新建立一个新的Pipeline,
HDFS写文件过程分析
数据写入到SSD(固态硬盘)中的过程
近些年来,SSD固态硬盘开始大规模商用,效果确实不错,尤其对于PC系统盘而言,
对电脑系统的提升十分明显
虽然现在服务器大多还是采用的传统的机械硬盘
但是出于对为未来的考虑,机械硬盘的存储过程不再简述了
这里主要讲解SSD存储原理
NAND Flash作为存储介质
SSD内部一般使用NAND Flash来作为存储介质,其逻辑结构如下:

一个SSD有多个NAND Flash,每个NAND包含多个Block,每个Block又包含多个Page.
由于NAND的特性,每次读写必须是一个page,通常每个Page大小为4k或者8k
另外,NAND还有一个特征,只能读写单个page,不能做到覆盖写入某个page,必须要先清空里面的内容,再写入.清空内容的电压较高,必须以block为单位,因此,没有空闲的page时,只能找到无效的block,先清理block再写入
SSD写入过程
写入由于受到NAND的限制,分为新写入和更新两种,处理流程不同
先来看新写入:
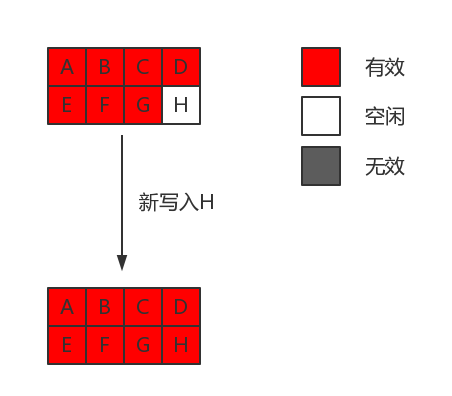
流程:
- 找到一个新的page
- 把数据写入到空闲的page中
- 更新mappping table
更新流程:
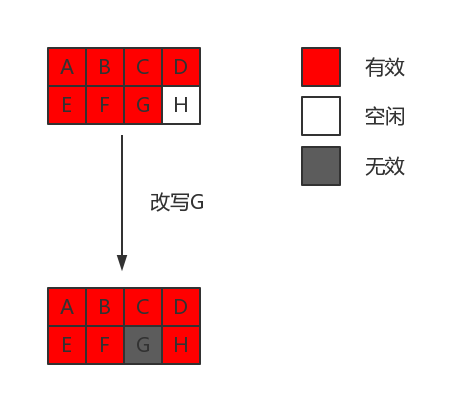
假设更新page G中的某些字节,流程:
- SSD不能覆盖写入,因此先找到一个空闲页H
- 读取page G的数据到SSD内部buffer中,把更新的字节更新到buffer
- 把buffer中的数据写入到H
- 更新mapping table中的G页,置为无效页
- 更新mapping table中的H页面,添加映射关系
数据处理计算
海量的数据经过HDFS得到了存储,如何处理这些数据又成了一道难题
以目前的CPU的运算能力,面对如此巨大的数据也显得无能为力
目前较为成熟的采用的是MapReduce原理进行海量数据处理
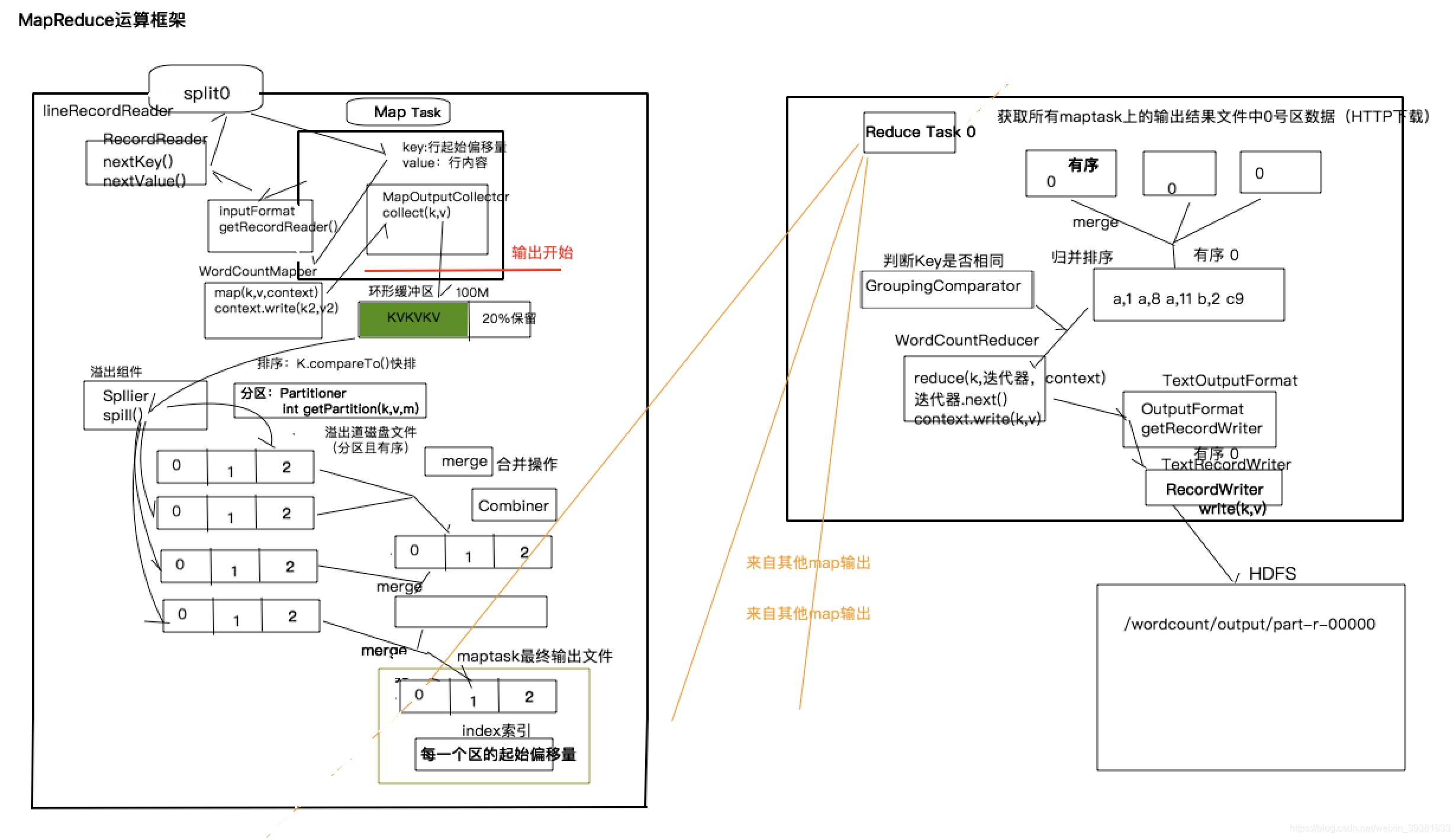
详细流程如下:
1.maptask读取切片中数据,将数据传递给map方法处理
2.maptask收集 map()方法输出的KV对,放到环形缓冲区中
3.当环形缓冲区到达溢出临界值时将会溢出到本地磁盘文件,这个过程有可能会产生多个溢出文件
4.溢出文件通过合并(merge)过程会合并成大的溢出文件
5.在溢出与合并的过程中,会调用Partitioner进行分组和对Key的排序
6.reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,0号reducetask去0号分区的数据
7.reducetask将是同一个分区但来自不同maptask的文件进行合并排序
9.reduce将最终结果输出
MapReduce中的shuffle
shuffle具体是指maptask的输出处理结果数据作为Reducetask输入的过程.
对照流程中的第2步到第7步:
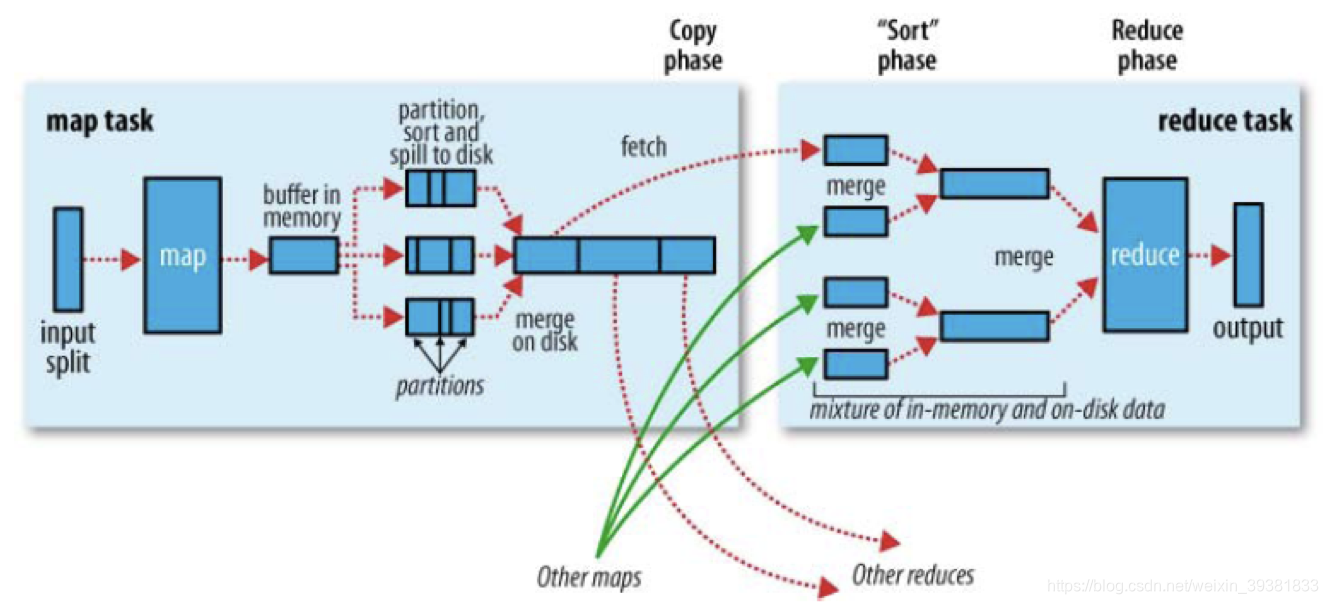
map端:
每个map任务都有一个环形缓冲区用于存储任务的输出.默认大小为100M(io.sort.mb),一旦缓冲区达到阀值,后台的线程就会把内容溢出(spill)到磁盘,过程中map会继续向缓冲区写数据,如果这个期间缓冲区被填满,map输出会被阻塞一直到溢出磁盘过程完成.
reduce端:
通过HTTP方式去获取数据,reduce不会等到说有的map结束之后再去取数据,而是只有map输出了数据就去获取数据.
切片Split过程详解
一个切片就是单个map操作来处理的输入块.每一个map只处理一个输入切片.每个切片被划分成若干个记录,每个记录是一个键值对,然后map一个接一个处理记录
切片的信息是由InputSplit来表示
public abstract class InputSplit
//获取切片长度
public abstract long getLength() throws IOException, InterruptedException;
//获取切片的存储位置
public abstract
String[] getLocations() throws IOException, InterruptedException;
public SplitLocationInfo[] getLocationInfo() throws IOException {
return null;
}
}
而切片的是由InputFormat产生并负责将其切分成记录
public abstract class InputFormat<K, V> {
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
客户端通过调用InputFormat的getSplit()来计算切片,然后将他们发送到资源管理器(RM),资源管理器根据其存储的位置信息来决定任务分配到什么地方运行。理想的情况是调度器想任务分配到数据本地化的节点,不能这么做的情况下,调度器会相对于非本地化的分配优先使用机架本地化分配。
在nodemanager中,map任务把输入分片传递给InputFormat的createRecordReader来获得此切片的RecordReader。RecordReader是一个记录上的迭代器,map任务用一个RecordReader来生成记录的键值对,然后在传递给map函数
MapReduce详解
对未来的展望
以上经过软件算法层面的分析
完成了对海量数据的存储与处理
未来是否还要依靠这种方式
就要看下一代量子计算机的性能如何了
可能我们现在每天朝思暮想地进行调优
对量子计算机来说只是那万分之一秒的事
论文完成了 7658子写了一天 ,日后闲日再来更新量子计算机的理论