文本分类的应用
LSTM内部结构详解(tensorflow版之前写过Keras版)
LSTM的关键是细胞状态,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。
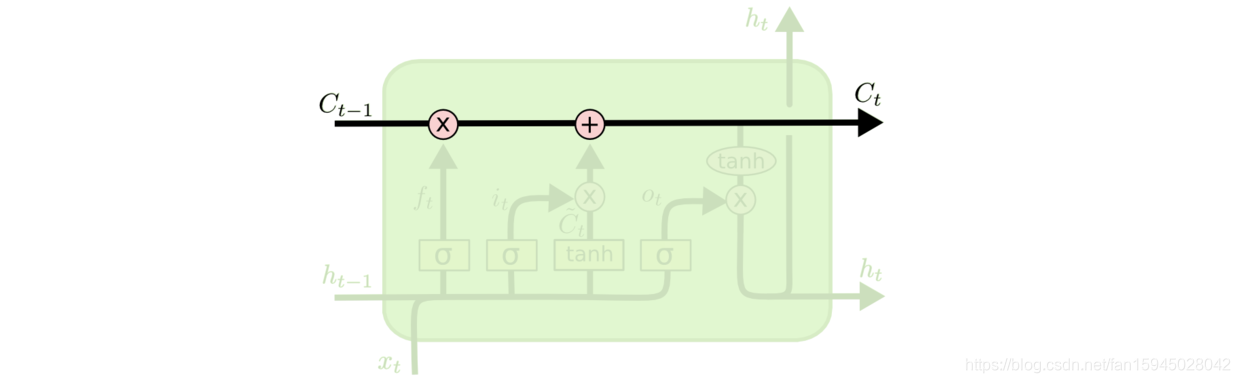
图1 细胞状态的传送带
第一层是个忘记层,决定细胞状态中丢弃什么信息。把和拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
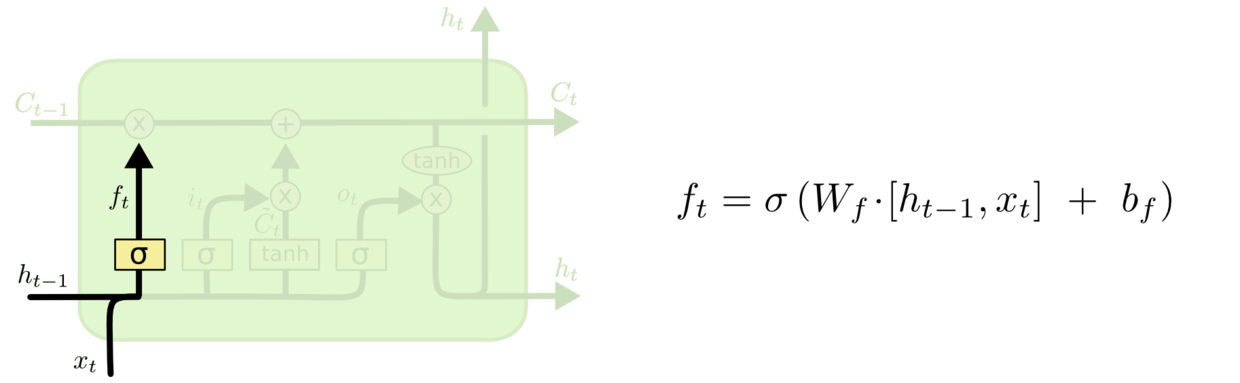
图2 细胞状态忘记一部分,保留一部分
上一步的细胞状态已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
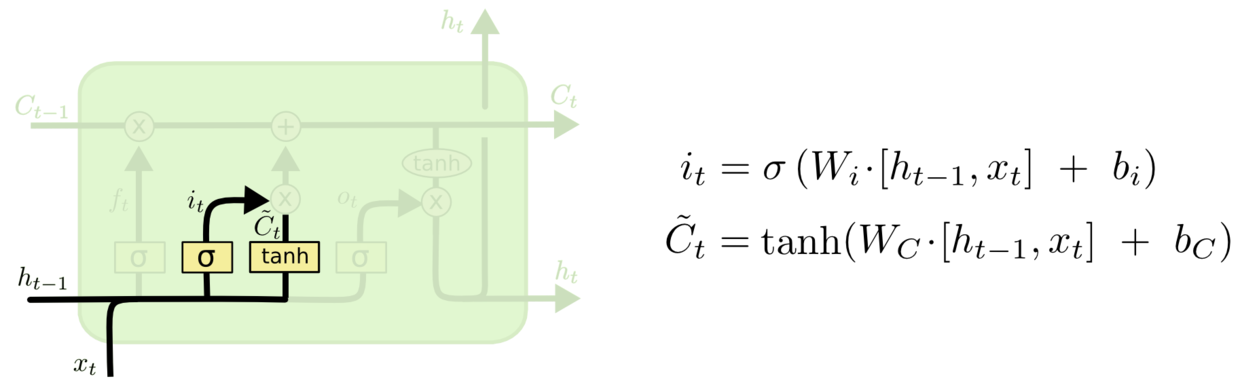
图3 更新细胞状态
现在可以让旧的细胞状态与(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分(i是input输入门的意思),这就生成了新的细胞状态。
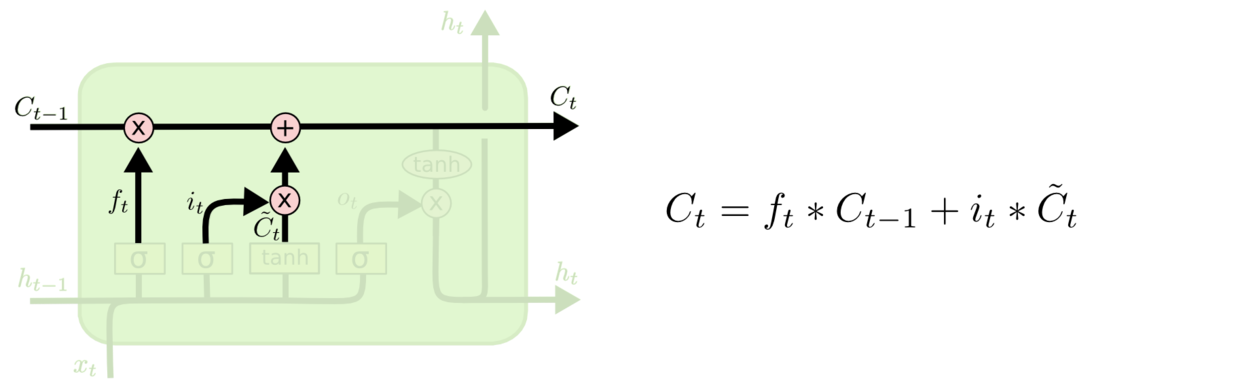
图4 生成新的细胞状态
最后该决定输出什么了。输出值跟细胞状态有关,把输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
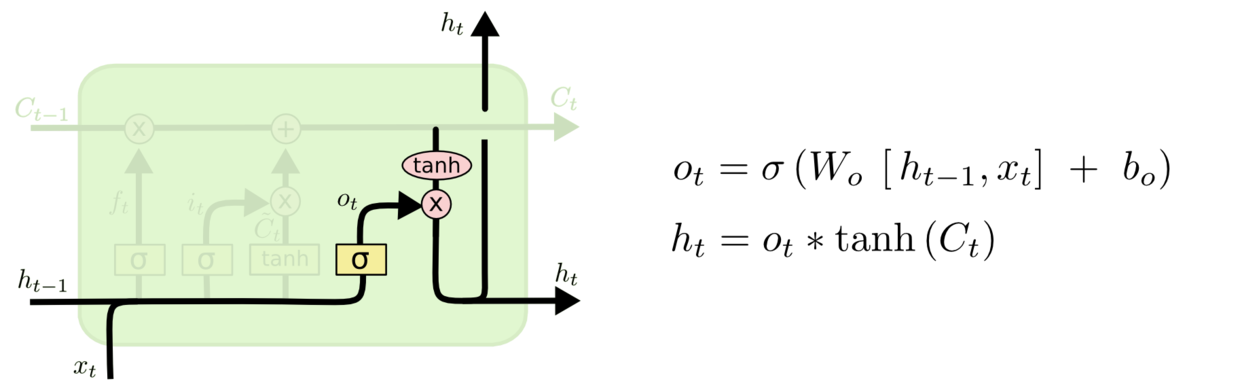
图5 循环模块的输出
下面是一份tensorflow代码
环境:python 3.5+tensorflow1.4+GTX1060+cuda8+cudnn6.0
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
# Hyper Parameters
learning_rate = 0.0001 # 学习率
n_steps = 1 # LSTM 展开步数(时序持续长度)
n_inputs = 4480 # 输入节点数
n_hiddens = 1024 # 隐层节点数
n_layers = 2 # LSTM layer 层数
n_classes = 1000 # 输出节点数(分类数目)
#导入数据
input_data=np.load('E:/VQA_data/inputguiyiwuxu.npy')
label=np.load('E:/VQA_data/Yguiyiwuxu.npy')
tx=np.load('E:/VQA_data/tx.npy')
ty=np.load('E:/VQA_data/ty.npy')
#batch
def n_batch(i,size):
batch_x=input_data[i*size:(i+1)*size,:]
batch_y=label[i*size:(i+1)*size,:]
return batch_x,batch_y
# tensor placeholder
with tf.name_scope('inputs'):
x = tf.placeholder(tf.float32, [None, n_steps * n_inputs], name='x_input') # 输入
y = tf.placeholder(tf.float32, [None, n_classes], name='y_input') # 输出
keep_prob = tf.placeholder(tf.float32, name='keep_prob_input') # 保持多少不被 dropout
batch_size = tf.placeholder(tf.int32, [], name='batch_size_input') # 批大小
# weights and biases
with tf.name_scope('weights'):
Weights = tf.Variable(tf.truncated_normal([n_hiddens, n_classes],stddev=0.1), dtype=tf.float32, name='W')
tf.summary.histogram('output_layer_weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.random_normal([n_classes]), name='b')
tf.summary.histogram('output_layer_biases', biases)
# RNN structure
def RNN_LSTM(x, Weights, biases):
# RNN 输入 reshape
x = tf.reshape(x, [-1, n_steps, n_inputs])
# 定义 LSTM cell
# cell 中的 dropout
def attn_cell():
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hiddens)
with tf.name_scope('lstm_dropout'):
return tf.contrib.rnn.DropoutWrapper(lstm_cell, output_keep_prob=keep_prob)
# attn_cell = tf.contrib.rnn.DropoutWrapper(lstm_cell, output_keep_prob=keep_prob)
# 实现多层 LSTM
# [attn_cell() for _ in range(n_layers)]
enc_cells = []
for i in range(0, n_layers):
enc_cells.append(attn_cell())
with tf.name_scope('lstm_cells_layers'):
mlstm_cell = tf.contrib.rnn.MultiRNNCell(enc_cells, state_is_tuple=True)
# 全零初始化 state
_init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)
# dynamic_rnn 运行网络
outputs, states = tf.nn.dynamic_rnn(mlstm_cell, x, initial_state=_init_state, dtype=tf.float32, time_major=False)
# 输出
#return tf.matmul(outputs[:,-1,:], Weights) + biases
return tf.nn.softmax(tf.matmul(outputs[:,-1,:], Weights) + biases)
with tf.name_scope('output_layer'):
pred = RNN_LSTM(x, Weights, biases)
tf.summary.histogram('outputs', pred)
# cost
with tf.name_scope('loss'):
#cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred),reduction_indices=[1]))
tf.summary.scalar('loss', cost)
# optimizer
with tf.name_scope('train'):
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# accuarcy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.name_scope('accuracy'):
accuracy = tf.metrics.accuracy(labels=tf.argmax(y, axis=1), predictions=tf.argmax(pred, axis=1))[1]
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
train_writer = tf.summary.FileWriter("E://logs//train",sess.graph)
test_writer = tf.summary.FileWriter("E://logs//test",sess.graph)
# training
for step in range(220):
for i in range(200):
_batch_size = 1000
batch_x, batch_y = n_batch(i,_batch_size)
sess.run(train_op, feed_dict={x:batch_x, y:batch_y, keep_prob:0.5, batch_size:_batch_size})
if i % 1000 == 0:
loss = sess.run(cost, feed_dict={x:batch_x, y:batch_y, keep_prob:1.0, batch_size:_batch_size})
acc = sess.run(accuracy, feed_dict={x:batch_x, y:batch_y, keep_prob:1.0, batch_size:_batch_size})
print('step: ',step,'| i:',i,'Iter: %d' % ((i+1) * _batch_size), '| train loss: %.6f' % loss, '| train accuracy: %.6f' % acc)
test_loss = sess.run(cost, feed_dict={x:tx[5000:6000], y:ty[5000:6000], keep_prob:1.0, batch_size:_batch_size})
test_acc = sess.run(accuracy, feed_dict={x:tx[5000:6000], y:ty[5000:6000], keep_prob:1.0, batch_size:_batch_size})
print('step: ',step,'| i:',i,'Iter: %d' % ((i+1) * _batch_size), '| test loss: %.6f' % test_loss, '| test accuracy: %.6f' % test_acc)
#train_result = sess.run(merged, feed_dict={x:batch_x, y:batch_y, keep_prob:1.0, batch_size:_batch_size})
#test_result = sess.run(merged, feed_dict={x:test_x, y:test_y, keep_prob:1.0, batch_size:test_x.shape[0]})
#train_writer.add_summary(train_result,i+1)
#test_writer.add_summary(test_result,i+1)
if step==219:
saver.save(sess, 'E:/mymodel/model.ckpt', global_step=149)
print("save Finished!")
print("Optimization Finished!")
# prediction
print("Testing Accuracy:", sess.run(accuracy, feed_dict={x:tx, y:ty, keep_prob:1.0, batch_size:tx.shape[0]}))