Eureka
- SpringCloud Eureka使用NetFlix Eureka来实现的,它包括了服务端组件和客户端组件,并且都是用java 编写的。 Eureka服务端就是服务注册中心,
- Eureka客户端主要处理服务的注册发现,通过注解和参数配置的方式,客户端向注册中心注册,并且周期性的发送心跳维护一个可用列表。
- 服务注册中心,用户服务注册发现功能。
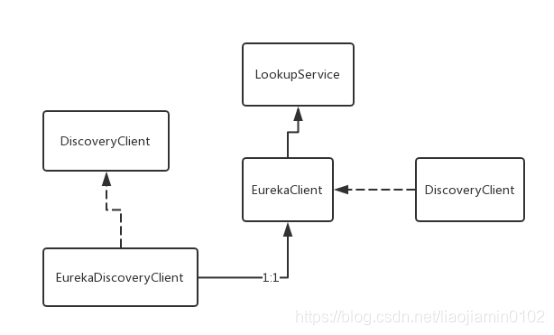
- SpringCloud的功能都是依赖NetFlixEureka中的方法完成的,下面就依次介绍对于的所有功能:
- 服务发现功能:
- 如上图所式,左边的DiscoveryClient是一个接口,是SPringCloud定义的一个服务发现所需要用到的常用抽象方法,其中EurekaDiscoveryClient是其中的一个实现类,该类关联了NetFlix Eurkea中的一个EurekaClient类,通过这个类来实现服务发现功能,
- 在netFlixEreka中有几个用来获取服务列表的方法:

- 这三个方法都是获取当前服务列表的方法:取其中一个getServiceUrlsFromConfig分析:
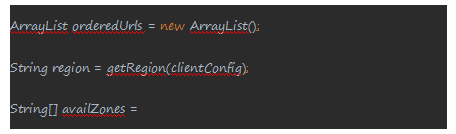
- 它先通过配置信息中获取对于的Region和Zone信息,然后通过对应的Zone和一定的算法来确认加载位于哪个Zone的配置ServiceUrl,由此处可以看出来Eureka是优先返回本服务所在Zone的Url列表信息。具体的算法是在EurekaClientConfigBean类中有一个getEurekaServiceServiceUrls方法完成。之后会通过一个简单的算法,将其他Zone中的url信息加入到URLs列表中,最后返回对应的列表信息,如果遍历所有zone之后都没有获取到对应的url则会抛出IllegalArguementException
- 服务注册:

- Eureka的注册也是在NetFlix的这个类中完成的,其中有一个很明显的方法叫做register方法,当时并不是直接调用这个方法进行服务的注册,是通过另外一种途径,其中在DiscoveryClient类中有一个构造方法,这个构造方法调用本类中的一个InitScheduleTasks()方法。该方法中有一个这样的判断
- 依据方法命名可以推断出,这个方法用来判断是否需要注册到eurka中,中个方法中创建了NetFlix 的InstanceInfoReplicator的一个实例,这个类继承了Runnable接口是一个线程,该线程中定义类一个线程池,实用的是ScheduleExecutorService,她会执行一个定时任务,这个定时任务的作用就是定时去执行本线程,
- 具体作用可以看到它的run()方法中来得知,其中有一个DiscoveryClient.register()方法,其中Registe方法中是通过发送rest的请求的方式进行注册操作。
- 因此整个注册过程是先通过定时任务定时去执行这个线程,然后通过判断现有状态来决定是否需要注册服务。
- 服务获取与服务续约
- 服务续约是和服务注册也是在这个方法中的另外两个定时任务执行的。其中TimeedSuPerVisorTask是和服务注册在同一个判断分支中,但是同服务获取的参数不同的是其中的配置信息,还有第一个参数,服务续约功能的第一个参数“hearbeat”从这个参数可以看出,是通过这个定时任务来定时发送心跳,来达到服务续约的目的,最终实也是通过rest请求的方式来达到续约的目的。而定时任务中其中另外一个参数:timeOut是从配置中读取过来的作为发送心跳的时间也就是这个定任务执行的时间,这个配置如下:

- 服务获取还是在刚才的InitScheduledTasks方法中还有另外一个判断分支:
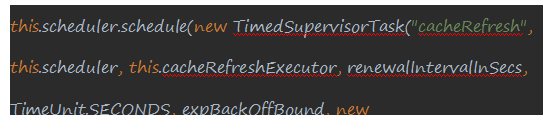
- 可以看到其中也有一个定时任务代码如下:
- 定时任务还是利用ScheduleExecutorService,来作为定时任务执行器,定义了一个线程池TimeedSuPerVisorTask, 定时执行的实践是从配置文件中获取得来的renewaLintervalInSecs,最后的参数是定时任务执行时间单位。 这个定时任务的具体任务是做了服务获取的工作,服务获取之所以放到另外一个if条件中是因为这个功能有一个参数配置来限制此IF条件是否执行:
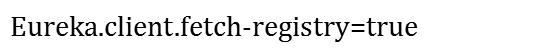
- 其实这个参数是默认True,所以一般不配置
- 有上面三个可以得出,Eureka的服务发现,注册,获取,续约都是通过rest请求的方式来获取的。
- 服务注册中心处理:
-
SpringCloud体系都是通过rest请求的方式交互,服务注册中心就是处理这些rest请求的作用,都在com.netflix.eureka.resources中
4.1.服务注册请求:
-
在ApplicationResource类中有一个addInstance方法,首先会判断配置是否正确,之后会调用InstanceRegistry类中的register方法来进行服务注册。它线会调用一个publishEvent函数,之后调用父类AbstractInstanceRegistry中的register方法进注册实现从源码中可以看到,服务列表是存储在一个双层Map中


- 第一层Map中的Key存储的AppName引用名称:

- 第二层Map中的可以存储的InstanceInfo中的id
4.2. 服务获取请求
- 从InstanceResource类中可以找到getInstanceInfo这个方法可以可以看到他是通过appName以及infoid来回去对于的节点列表信息:


- 最终是调用的AbstractInstanceResource类中的getApplicationByAppAndId,从双层数组中获取对应的信息:
- 总结eureka:
- 服务提供者:(也可能是消费者)
- 服务注册:通过rest请求并且带上元数据信息到server
- 服务同步:不同eureka在同一个集群中会相互复制可用的节点信息。
- 服务续约:定时任务发送心跳给eureka server
5.1 服务消费者(也可能是提供者):
- 获取服务:启动时候通过rest请求该注册中心获取服务清单,清单30跟新一次,可配置
- 服务调用:通过ribbon轮训配置中节点实现负载。
- 服务下线:服务正常关闭会发送一个下线的rest请求给service 通过并且状态变为DOWN
5.2服务注册中心:
- 失效剔除:没收到下线请求但是没有收到续约定时任务发出的请求回复,认定下线,时间可配
- 自我保护:当15分钟内心跳失败比利低于85% 那么就触发自我保护,也就是将现有注册列表中的信息保护起来不做30更新,这样就会有节点下线而不被剔除的情况而调用失败。测试环境可以加上eureka.server.enable-self-preservation=false
SpringCloud Ribbon
-
一般说的负载均衡都是服务器端的负载均衡,其实负载均衡分为硬件负载(F5)和软件负载(nginx),不管是那哪种,都需要维护一个可用的服务列表,然后请求过来之后用一定的算法去列表中选一台服务做转发。
-
而客户端的负载均衡和服务器负载均衡最大的不同是列表是维护在客户端这边。而这个清单来自于一个注册中心,比如Eureka就是一个服务注册中心,客户端负载均衡和服务器端类似也是通过心跳去维护服务清单的健康,只不是这个步骤需要和Eureka配合完成。
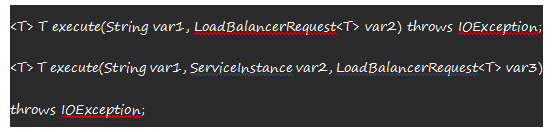
- 下面通过Ribbon的源码分析,Ribbon如何实现客户端负载均衡, 在使用Ribbon的时候会用一个@LoadBalanced,通过这个可以找到具体loadBalanced所在的包位置,之后查看对于包下类,可以看到有一个LoadBalancedClient接口,这个接口定义类负载均衡应该具备的一些功能:
- 方法Choose:根据传入的serviceId参数选择服务,两个execute使用从choose负载均衡器中选出来的服务执行请求内容,方法reconstructUrl:通过ServiceId以及对于的服务列表中的信息以及配置信息,将具体的ServiceInstance转为Host:port形式。
- 对主要的类进行整理:
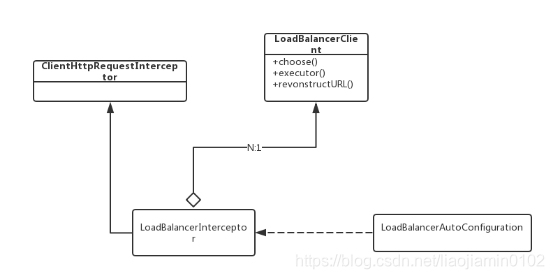
通过整理对应包中的类, 得到以上类图,从中可以看到LoadBalancerAutoConfiguration按类名称来猜测应该是和自动化配置相关,看其源码可以知道,Robbin实现负载均衡的先决条件:
- RestTemplate类必须加载到当前工程中。
- LoadBalancerClient Bean必须线加载到当前容器

-
创建LoadBalancerInterceptor Bean用来做为请求的拦截器
-
创建一个RestTemplateCustomizer Bean用来给RestTemplate类型的请求加上拦截器

- 维护了一个被@LoadBalanced修饰过的Bean的列表并且在这里给这个列表中每一个Bean加上拦截器

- 接下来看LoadBalancerInterceptor源码看具体实现:
- 以上拦截器的作用在于当一个被@LoadBalanced注解修饰的RestTemplate对象向外发起Http请求的时候会被该类中的intercept函数拦截,因为我门使用RestTemplate时候都是用服务名字作为Host所有可以直接从URI中得到,之后调用executor。
- Executor:

- 最终调用的executor方法首先通过getServer方法获取到对象实例server, 此处的getServer的实现并不是调用的LoacBalancerClient中的choose方法,而是调用NetFlix Ribbon自生的ILoadBalancer接口中定义的ChooseServer函数,这个接口有几个实现类,此处Ribbon调用的是ZoneAwareLoadBalancer类中的实现,在获取到server之后,会利用serverId以及server对象来生成RibbonServer对象,接着生成ServerInstance(服务实例的抽象,此处等同RibbonServer)类调用最终的apply方法
- 此方法实现向一个具体服务实例发起请求,从而实现一开始以服务名为Host的URI到Host:port形式的实际访问地址的转换。
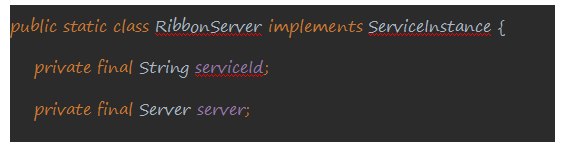
- 负载均衡的最终实现方式:
- Ribbon的核心接口还是在ILoadBalancer接口,上面以及说过其中定义的接口信息。一下将分析其所有实现,来解析他如何做到客户端负载均衡:
- AbstractLoadBalancer他是以上接口的一个抽象类,其中定义了一个枚举类型定义了服务的三种状态(All:所有, STATUS_UP存活的实例, STATUS_NOT_UP:停止服务的实例),实现了一个ChooseServer()方法,通过调用接口中的ChooseServer方法实现的
- BaseLoadBalancer继承了以上抽象类,可以明显看到该类中定义并且维护了两个服务列表,可见一个是所有服务,一个是可用服务。
- 定义了各种和服务相关的内容,比如IPing检查服务是否正常,定义负载均衡的处理规则IRule对象,其中有一个关键方法chooseServer()方法,底层实现是交给IRule来完成对象的选择。如下代码
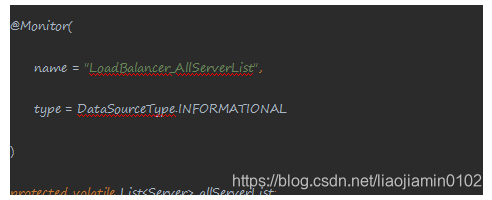

- 并且在初始化Ping任务的时候,该类会创建一个定时任务,来检查Server是否可用,10秒执行一次。用的Timer定时器

- DynamicServerListLoadBalancer中的服务筛选拦截器

- 类中有一个属性ServerListFilter其中ServerListFilter是用作筛选的拦截器,有多个实现,如下
- AbstractServerListFilter基础的抽象过滤器,定义必要的一些信息
- ZoneAffinityServerListFilter通过区域Zone的设置,筛选出和自己同一个区的实例,但是他并不是直接使用这些同一个Zone中的列表,单满足一定条件时候可能不用同一个Zone中的server,如下源码:
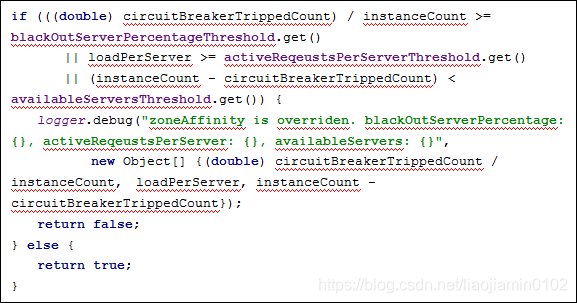
- 如上,三种情况下不使用:
-
blackOutServerPerCentage: 故障实例百分比(断路器断开数量/实例数量)>=0.8
-
activeReqerStsPerServer: 实例平均负载 >=0.6
-
availableServers: 可用的实例数量(实例总数-断路器断开数量)< 2
-
ServerListSubsetFilter:完全继承ZoneAffinityServerLIstFilter,适合大型集群服务的情况,他是在zone的方式筛选下在一层的筛选,通过固定的方式来做健康检查,检查之后的服务列表是最后的列表信息
-
ZonePreferenceServerListFilter:通过配置的区域Zone或者Eureka实例元数据所属的区域来筛选指定服务列表,先通过ZoneAffinityServerListFilter拦截器来过滤得到区域感知的结果,然后在更具配置来筛选
-
ZoneAwareLoadBalancer是对DynamixServerListLoadBalancer的扩展可以从ChooseServer源码可以看到,当Zone的可用个数小于1 的时候,直接调用父类BaseLoadBalancer中的chooseServer方法,此方法逐个轮询每一个server,当zone个数大于1 的时候,执行选择策略,会调用ZoneAvoidanceRule中静态方法getAvailableZones来获取到可用的Zone区域的集合,当这个zone结合不为空的时随机选育个zone区域,在确定某一个zone的时候在获取对应zone的服务均衡器,并且调用IRule接口chooseServer来选择具体的服务实例,具体实现是在ZoneAvoidanceRule
-
以上的负载均衡策略都是针对Zone级别的,也就是先选择Zone,之后在选择具体zone中的server,Ribbon实现的服务选择策略源头都在IRule 接口,
以下分别介绍每个负载均衡规则:
- RandomRule:
- 可以看到接口中有一个Choose接口

- 实际上委托给了另外一个choose方法,其中有一个getLoadBalancer负载均衡对象的参数,次,可以通过这个对象得到可用实例列表,已经所有实例列表,之后通过rand.nextInt(ServerCount)方法从可用列表中选取一个实例
- RoundRobinRule:
- 这个策略的实现和之前的实现类似,只是随机的时候曾加了一个算法,首先设置了一个线程安全的AtomicInteger,初始化为0 ,之后循环去获取,如果获取十次都没有得到择提示bug,其中循环算法也有不同如下:

- 可以看到,并不是通过所有列表数量来随机,
- RetryRule:
- 这个策略是实现了一个具有重试机制的选择功能,具体的选择是交给了RundRobinRule来完成的,如果得到的具体实例就返回,否则,判断是否在重试许可范围内,如果在,的话就再次轮训调用choose方法。
- WeightedResponseTimeRule
- 这个策略是继承了RoundRobinRule,但是曾加了一个权重列表的判断,当权重列表中最后一个小于0.001的时候,直接使用父类中的类筛选策略,如果权重大于0.001会通过权重来筛选,如下:
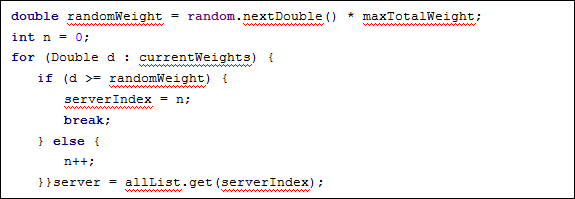
- 权重维护:
- 这个策略在初始化的时候会调用一个Init方法,这个方法的作用是设置了一个定时器,每30s执行一次,具体执行的内容在内部类ServerWeight类中:他会根据loadBalancerStatus中来获取实例的响应时间来计算权重信息。
- ClientConfigEnabledRoundRobinRule
- 直接定义了一个RoundRobinRule,调用了choose方法,用来给其他高级策略做最后的备份。
- BestAvailableRule
- 这个策略注入了负载均衡统计对象LoadBalancerStatus,他通过遍历负载均衡中维护的所有服务,首先过滤掉故障的实例,然后找出并发请求数量最小的一个,也就是选出最空闲的一个实例,如果负载均衡对象为空或者,过滤之后实例为空,择默认用父类中的choose方法。
- PreDicateBasedRule
- 利用google Guava Collection 中的apply方法对服务进行过滤,过滤apply是一个抽象类,由各个子类实现。之后在对过滤之后的服务列表进行轮询
- AvailabilityFilteringRule
- 继承以上的类,但是过滤逻辑不同主要判断两个内容:是否故障,也就是断路器是否打开,实例并发数量是否大于阀值2^32-1,可以通过配置..ActiveConnectionsLimit来修改
- 参数配置:rebbon可以全局配置也可以正对某个实例配置
- 和Eureka结合之后:会触发Eureka 中实现的对Ribbon的自动化配置,ServerList和Iping(服务检测)都会交给Eureka中的服务治理框架来维护。这时候的配置将更简单。因为Eureka帮我们维护来服务列表,而且Ribbon默认实现区域亲和策略,所有在Eureka上做分区的集群,指定eureka的zone就可以实现阔区域的容错。
CAP
C: 一致性 A:可用性 P:可靠性
Eureka是AP
Zookeeper是CP
SpringCloud Feign
- Feign帮我们整合来SpringCloud Ribbon和SpringCloud Hystrix,我们不用每一个需要调用的接口都封装一个REstTemplate的配置,只需要定义一个接口并且加上Feign的配置,Feign会自动帮我们完成这些配置的。
- 优点:在开发当中,我们调用哪个实例的接口,只需要封装一个Feign修饰的接口,但是如果每个项目都自己定义Feign的调用,十个项目可能就定义十次,因此我门实际开发中为了减少编码量,我门都是服务提供方提供服务的同时也定义好一个额外的项目API接口,这样所有服务消费者都可以用引入这个jar的形式来得到对于的API信息。
- 缺点:接口提供者修改来API,调用者可能项目都会报错,所有开发要遵循开笔原则。
SpringClud Zuul
- Zuul在默认情况下是会过滤请求头中的敏感信息,比如Cookie,Authorization,但是如果我们需要Zuul和Shiro或者SpringSecurity一起使用的话需要配置:
- zuul.sensitiveHeaders= 设置全局参数为空来覆盖默认
- zuul.routes..customSensitiveHeaders=true
- 指定路由开启自定义敏感头zuul.routes..sensitiveHeaders=将指定路由的敏感头设置为空。
推荐后两者
Zuul包含来对Ribbon和Hystroy的依赖,三个时间配置:
Hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds //-----断路器断开超时配置
Ribbon.ConnectionTimeout//---ribbon连接超时配置可重试
Ribbon.ReadTimeout//—ribbon请求超时配置可重试
- Zuul过滤器详解:

- ZuulFilter是一个抽象类,其中有4个抽象方法,我们可以在Zuul的包目录下看到很大Zuul自定义的一些过滤器:org.springframework.cloud.netflix.zuul.filters
- ServerDetectionFilter:是最先执行的,执行顺序是-3,可以看到没有更小的类,这个过滤器的作用是用来检测请求是通过Spring的DispatcherServlet还是ZuulServlet来处理运行。(一般通过网关的外部请求都会被Spring的处理,除了通过zuul/* 路径访问的请求会绕过Spring的dispatcherServlet的处理,大文件上传,可以通过zuul.servletPath参数修改)
- 还有其他pre包下的一些过滤器都会依次执行
- Route过滤器:
- RibbonRoutingFilter 它是执行在route阶段,执行顺序是10,作用是通过使用Ribbon和hystrix来向服务发起请求。但是只在请求上下文中存在serverId的请求生效。
- SimpltHostRoutingFilter:route第二阶段执行,但是只有在上下文中有RouteHost才执行,也就是配置具体服务路径的形式,作用是直接向routeHost发起http并没有用刀hystrix
- SendForwardFilter: route第三阶段对请求上下文中有forward.to参数的请求生效,执行本地跳转
- Post过滤器:
- SendResponseFilter:
- SendErrorFilter: 当发上面几个拦截器中发生异常的时候会被他捕获,并且封装成异常的格式返回。
- Zuul动态加载:
- 可以通过配置完成让zuul可以在不重启的情况下动态加载配置信息。这个需要SpringCloud config配置中心配合使用,需要在ZuulProperties的bean对象上面加上@RefreshScope标签,并且将配置文件写到git中。
- SpringCloud zuul源码:
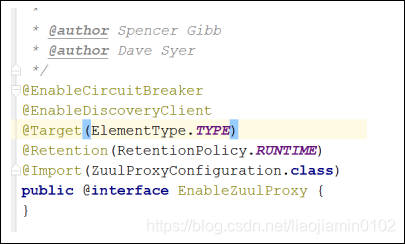
- 要使用zuul我们用到了一个标签,@EnableZuulProxy,可以从这个标签中看到ZuulProxyConfigurateion这个类的注入,从这个类的源码可以看到:该类中加载了一系列bean对象,首先如果容器中没有RouteLocator bean的情况下会加载DiscoveryClientRouteLocator,roteLocator是一个接口,其中定义了三个方法:

- 可以从具体的实现中可以看出,改接口定义是为了获取具体的配置路由,其中getRoutes是获取所有路由信息,getMatchIngRoute是通过请求中的path信息来获取对应的配置中的路由信息,这个方法可以自定义实现,只需要实现RouteLocator接口就可以实现自定义的路由获取,以及具体路径路由的寻找方案。
- 接下来注入了一系列的Filter,PreDecorationFilter, RibbonRoutingFilter, SimpleHostRoutingFilter,这三个拦截器都是在pre阶段生效的。在来看看本类(ZuulProxyConfigurateion)的父类ZuulConfiguration:
- 注入了Pre阶段和一些Post阶段的 的拦截器:
- 其中最重要的是如果在容器中没有ZuulServlet bean类的话他会注入ZuulServlet类,这个是Zuul的核心类,
- ZuulServlet:是最核心的类,其中有一个service方法,调用inite方法中可以看到,他为每一个请求生成了一个RequestContext,requestContext继承了ConcurrentHashMap
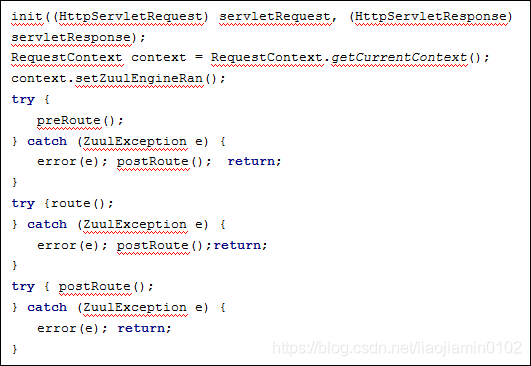
- 之后调用preroute来调用对应的filter其中的之中实现是

- 程序设定首先执行pre类型的拦截器,以上方法是用来获取这一类的所有拦截器,更具之后的实现可以知道,他最终执行的是ZuulFilter拦截器
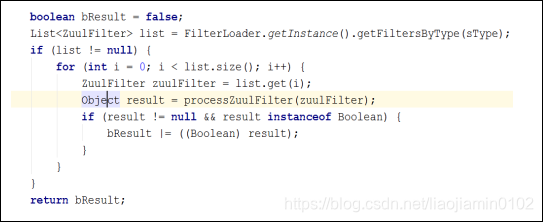
- 其他的两个route和postRoute的实现方式也是同样的道理,在所有Filter的执行过程中他们可以共享同一个RequestContext,就是在Init方法中为每个请求生产的哪个对象,该对象的生命周期贯穿与整个请求,执行一个过滤器之后,他会把结果放到这个对象中,提供给后续的filter使用,以达到后续filter可以更具前面filter的结果来决定是否执行。最后Errorfilter是除了postFilter之外的所有filter异常的时候都会执行。同时也初始化了 ZuulFilterInitializer bean类:
- 该类的中定义了一个Zuufilter的Map类型的数据,会将所有的filter向filterRegistry注册,FilterRegistry定义了一个ConcurrentHashMap用来存储所有的过滤器。并且在这个bean类中定义了一些针对filter的CURD操作SpringCloudZuul中自己定义了一部分Filter去做一些信息的处理,ZuulServer处理请求默认是用的”IOS-8859-1”所以在文件上传的时候会有乱码问题。
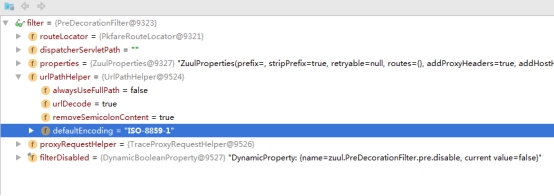
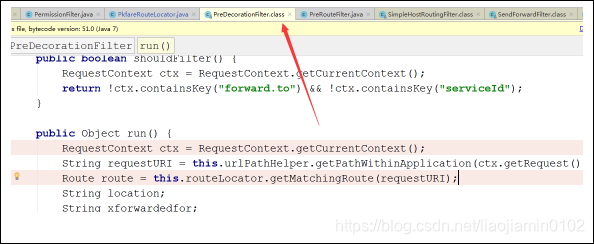
- 当请求过来,ZuulFilter会先执行Pre 类型的拦截器,其中最后一个SpringCloud Zuul定义的Filter是 PreDecorationFilter,这个拦截器会去判断请求上下文中是否存在forward.to和ServiceId如果都不存在他在回去执行具体过滤器的操作,当然在判断之前他必须拿到所有的路由规则,他是通过调用routeLocation中的getMatchingRoute方法来获取当前的路由规则,并且初始化到系统properties中