三个月没看QQ群了。
群里有同学分享的近期答辩注意事项,于是乎想把近期QQ聊天记录从头到尾过一遍。
导出聊天记录文本,发觉上万行的文本,这么读效率有点低,所以用python整理了一下。
这个是整理前的(手机端QQ聊天记录导出后的txt文件):

这个是整理后的:
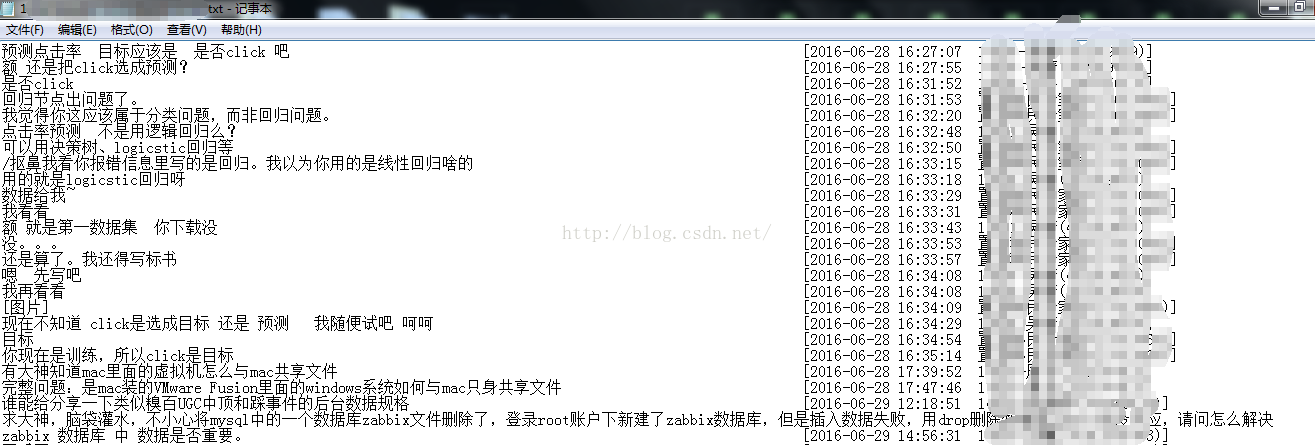
附上代码:
2016.12.2 加了个自动换行的代码,避免单行过长。
2018.1.30 根据lch1251680944、qq_20408711反馈,修正正则表达式
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import codecs
script_name = "QQ聊天记录整理"
# 1、通过正则语句,提取出所有的记录头和记录内容两个数组。一条记录头对应一条记录内容,所以两个数组长度应该相等。
# 2、处理记录内容
# 2.1、windows的换行为'\r\n',单'\n'体现不出换行效果。手机端导出的记录有的换行是\n,需要替换一下。
# 2.2、记录头放在了每条记录末行后面,为了记录头整齐美观,需要计算一下记录头前补多少空格。windows记事本显示中文字符占两格,英文占1格,而python中文字符长度是却是1,如果想要显示整齐,还需要计算一下,然后补齐空格数。补齐后记录头距离行首位置为100的整数倍。
# 3、读和写文件的时候注意编码转换
def length_w(text):
'''计算字符串在windows记事本中的实际显示长度'''
# 取文本长度,中文按2格计算。
length = len(text) # 取其长度(中文字符长度为1,英文1)
utf8_length = len(text.encode('utf-8')) # 取其长度(中文长3,英文1)
length = int((utf8_length-length)/2)+length # 按(中文2英文1)计算长度
# 这个写法实际上还是有问题的,有些特殊字符会导致计算长度和实际显示长度不一致。所以下面计算换行问题的代码中换了另一种写法,避免因特殊字符导致每行实际显示长度超出限定值,虽然还是不精确,但是不会超出限定值。
# 比如:
# '°'在记事本中显示占2格,b'\xc2\xb0'utf-8编码长度为2。
# '�'在记事本中显示占1格,b'\xef\xbf\xbd'utf-8编码长度为3。
# ''在记事本中显示占2格,b'\x01'utf-8编码长度为1。(特殊字符无法显示)
# 至于特殊'\t'制表符最好最开始就用四个空格替换掉,避免其自动缩进带来的影响
return length
def chinese_linefeed(text,limit):
'''中英文混合排版,限制单行长度,超出长度换行'''
text_format= '' # 结果变量,初始化
text = text.replace('\t',' ')
text = text.replace('\r\n','\n')
text_arr = text.split('\n') # 按行分割文本
for line in text_arr:
# 逐行处理
text_format+='\r\n'
num = 0 # 长度计数变量,初始化
for i in line:
# 从该行第一个字符起计算长度
# 中文长度为2
# asc2码(英文及其字符等)长度为1
# 其他长度为2(一些特殊)
if i >= u'\u4e00' and i <= u'\u9fa5':
char_len=2
elif i >= u'\u001c' and i <= u'\u00ff':
char_len=1
else:
char_len=2
# 累计长度小于limit,直接保存至结果变量,计数变量累加
# 累计长度大于limit,换行后再保存,计数变量重置
if num+char_len<=limit:
text_format+=i
num+=char_len
else:
text_format+='\r\n'+i
num=char_len
return text_format.strip()
# QQ聊天记录手机端导出文本
filepath = r'C:\Users\waterd\Desktop\QQ群聊天记录.txt'
# 读取文件
fp = codecs.open(filepath,'r','utf-8')
txt = fp.read()
fp.close()
re_pat = r'20[\d-]{8}\s[\d:]{7,8}\s+[^\n]+(?:\d{5,11}|@\w+\.[comnet]{2,3})\)' # 正则语句,匹配记录头
log_title_arr = re.findall(re_pat, txt) # 记录头数组['2016-06-24 15:42:52 张某(40**21)',…]
log_content_arr = re.split(re_pat, txt) # 记录内容数组['\n', '\n选修的\n\n', '\n就怕这次…]
log_content_arr.pop(0) # 剔除掉第一个(分割造成的冗余部分)
# 数组长度
l1 = len(log_title_arr)
l2 = len(log_content_arr)
print('记录头数: %d\n记录内容: %d'%(l1,l2))
if l1==l2:
# 整理后的记录
log_format = ''
# 开始整理
for i in range(0,l1):
title = log_title_arr[i] # 记录头
content = log_content_arr[i].strip() # 删记录内容首尾空白字符
content = content.replace('\r\n','\n') # 记录中的'\n',替换为'\r\n'
content = content.replace('\n','\r\n')
content = chinese_linefeed(content,100) # 每行过长自动换行
lastline = content.split('\r\n')[-1] # 取记录内容最后一行
length = length_w(lastline) # 取其长度
space = (100-(length%100))*' ' if length%100!=0 else ''# 该行记录头前补空格,变整齐为100整数倍;余数为0则不用补空格
log_format += content + space + '['+title+']\r\n'# 拼接合成记录
# 写到文件
fp = codecs.open(filepath+'format.txt','w','utf-8')
fp.write(log_format)
fp.close()
print("整理完毕~^_^~")
else:
print('记录头和记录内容条数不匹配,请修正代码')