stress施压命令分析
一、stress --cpu 1 --timeout 600 分析现象?负载为啥这么高?top命令查看用户进程消耗的cpu过高(stress进程消耗的)
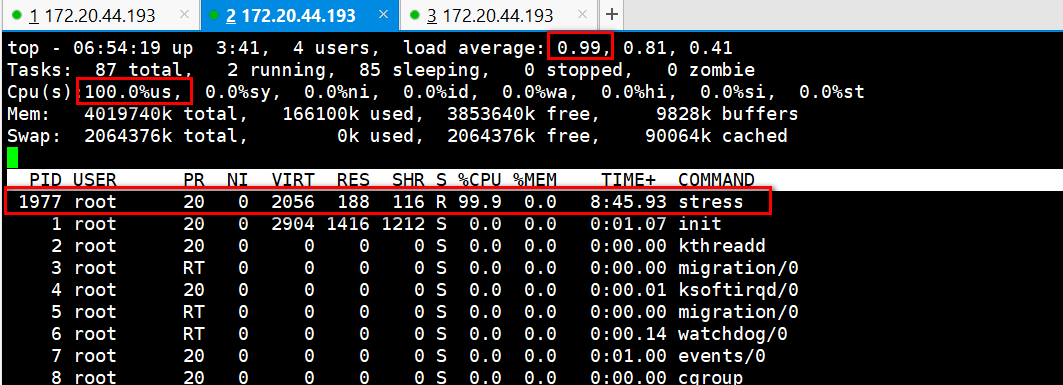
分析现象,可以看出负载很高,用户态的cpu的使用率是100%,stress进程使用的cpu也接近100%。
问题:负载为什么接近于1??
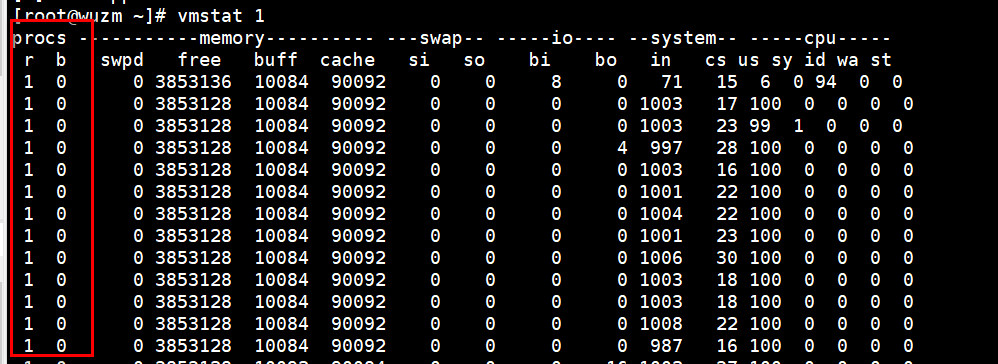
# vmstat 1 查看监控信息
负载=r+b,这是一个瞬时值。

下图可以看出r+b为1,所以这里的负载为1。
这里负载不为2的原因,这里只有一核cpu在干活,也只有一个进程在消耗cpu,所以这里负载是1,不会是2。
二、stress -i 1 --timeout 600 分析现象?top看负载升高,内核cpu过高? iostat -x 3 stress消耗cpu多,iowait 等待 pidstat -d
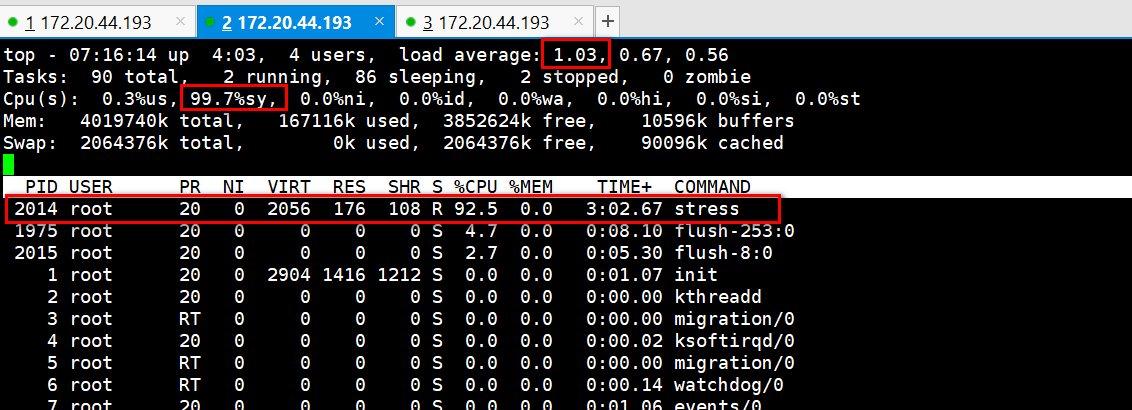
正常情况下,这里的iowait也是有数据的,不是0,应该会涨,可能是操作系统版本的原因,或者用stress-ng版本这个加强版
下载地址:https://kernel.ubuntu.com/~cking/tarballs/stress-ng/
安装步骤和stress一样的,需要编译安装。
高版本的stress-ng编译需要高版本的gcc,我这里以前是4.4.7版本的
gcc下载地址:http://www.gnu.org/prep/ftp.html
分析步骤:
top可以看到有iowait ,所以这里可能是io等待导致的。
1、 iostat -x 3
通过iostat 看磁盘的繁忙程度,这里的数据应该是达到20%以上,可以看出磁盘繁忙,还有进程读和写,我这里的操作系统版本太低,所以数据很小。
这里写操作也比较多,怀疑应该每秒写600多,所以磁盘繁忙是大量的写导致的,所以下面使用pidstat再分析。

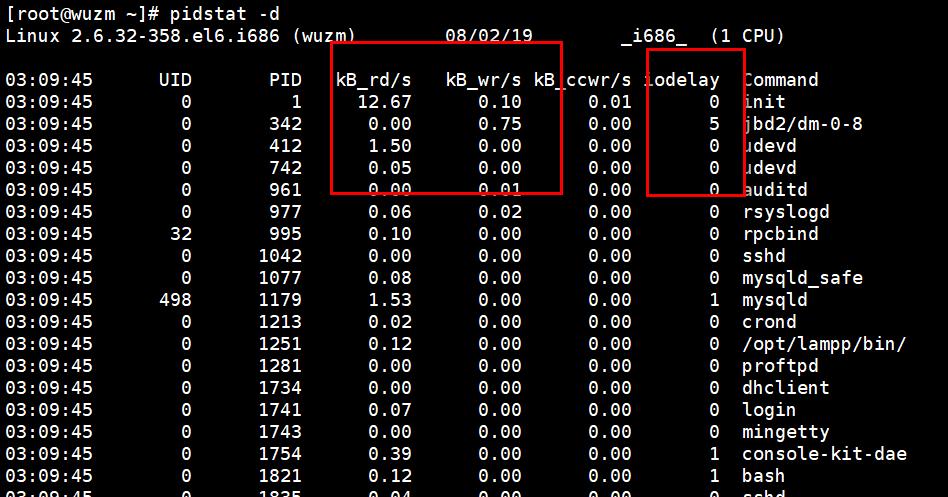
2、pidstat -d 3 查看进程读、进程写、和进程延迟
这里iodelay,这里每次都有java(tomcat)和stress。
这里的写操作比较多,
三、stress -c 8 --timeout 600
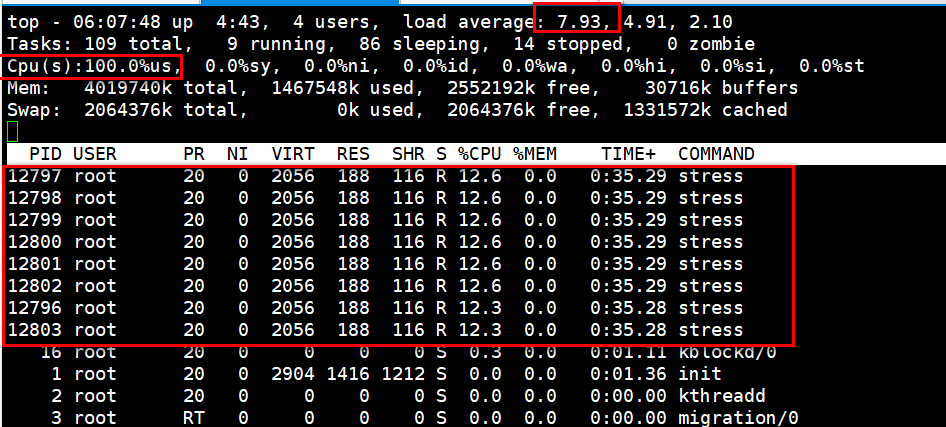
现象:用户cpu已经打满了,负载上升很快,并且很快就到8了,每个进程所占的cpu资源是12%多,就是这8个stress把cpu打满了。
vmstat 1
负载=r+b =8
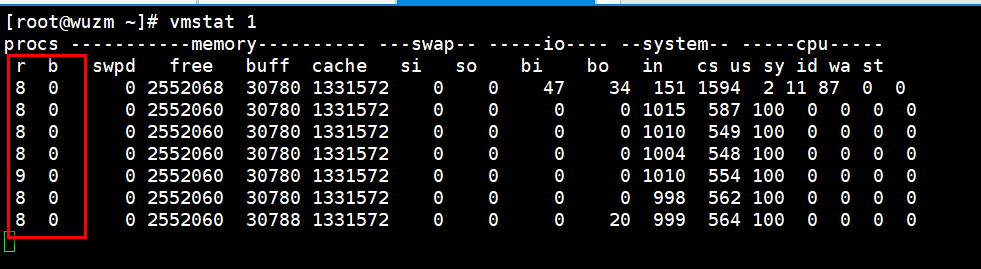
pidstat 3
这里的%wait是等待cpu临幸它所消耗的一个百分比,百分比越高,等待排队的时间越长,和iowait不同。
这里8个进程在抢占cpu,中断和上下文切换会高些。

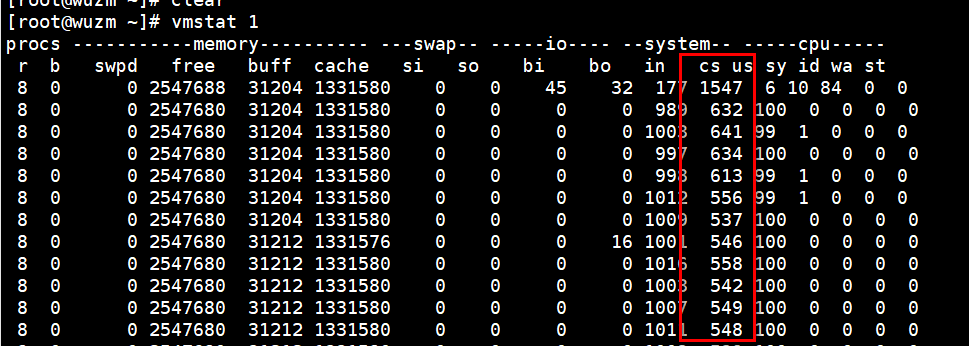
vmstat 3 查看中断和上下文切换
这里cs应该达到几十万以上,我这里数据不对,

案例:有次压测用的是4核的一个cpu,用20个线程去压,cpu就打满了,到100%
一个tomcat写的java进程,20个并发的是tps大概是90多,30个并发tps是80多,80个并发的时候tps就是70多。
cpu都是打满的,随着并发数的时候,响应时间不断增加,tps不断减小。
什么原因???
响应时间增加怀疑cpu上下文切换导致的线程等待时间比较长,
tomcat打印tomcat整理处理时间,再打印一个接口的一个处理时间,接口处理时间从100ms增加到200ms,但是tomcat的处理时间从1s增加到8s。
随着并发数的增加,tomcat线程池的排队时间从1s增加到8s多,时间耗在哪里了呢,时间耗在了线程的上下文切换上了。
四、sysbench --threads=10 --max-time=300 threads run
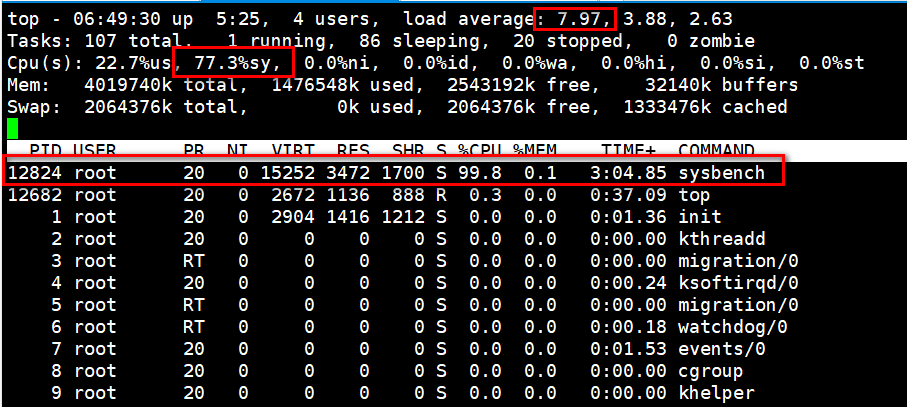
现象:负载很高,大部分还在内核态cpu,看看谁在用内核态cpu?iowait没有,中断没有,也不是虚拟化??那是谁把内核cpu打满了??
最有可能是上下文切换,进程之间上下文切换导致的内核态cpu比较高。
# vmstat 1
可以看到图中cs上下文切换真他妈好高,达到百万级别了。

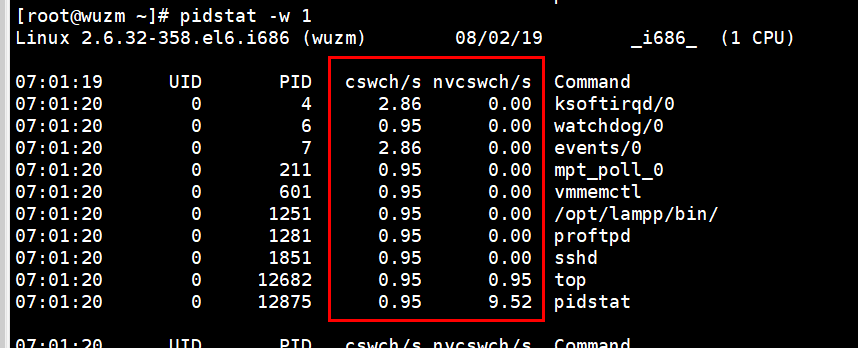
#pidstat -w 看上下文切换,但是这里啥也看不出来。为啥看不出来呢???
因为???
cswch自愿上下文切换:进程无法获取资源导致的上下文切换,比如;I/O,内存资源等系统资源不足,就会发生自愿上下文切换。
nvcswch非自愿上下文切换:进程由于时间片已到,被系统强制调度,进而发生的上下文切换 ,比如大量进程抢占cpu。
python脚本运行分析
五、app.py
六、iolatency.py