1、Vue是如何实现数据双向绑定的
1.1、实现双向绑定的基本原理
vue实现数据双向绑定主要是采用数据劫持结合发布者-订阅者模式的方式。
数据劫持是通过Object.defineProperty()实现的,该函数为每个属性添加setter,getter 的方法,在数据发生改变时 setter 方法会被触发,然后发布消息给订阅者,触发相应监听回调。当把一个普通 Javascript 对象传给 Vue 实例来作为它的 data 选项时,Vue 将遍历它的属性,用 Object.defineProperty 为每个属性添加 setter,getter 的方法。
vue的数据双向绑定主要通过三个模块完成:观察者Observer、订阅者Watcher、Compile解析模板指令。
(1)Observer监听 model 的数据变化,如果有变动的,就通知订阅者
(2)初始渲染页面、为节点绑定函数:通过 Compile 扫描和解析每个节点的相关指令,将模板中的变量替换成数据,并根据初始数据渲染页面视图。并且将每个指令对应的节点绑定函数,一旦视图交互,绑定的函数被触发,然后触发setter 方法,订阅者就会收到通知。
(3)watcher 搭起了 observer 和 Compile 之间的通信桥梁,达到数据变化 —>视图更新,视图交互变化(input)—>数据 model 发生变更的双向绑定效果。
var vm = new Vue({ data: { obj: { a: 1 } }, created: function () { console.log(this.obj); } });
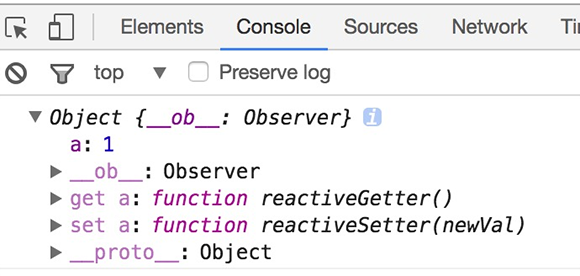
打印Vue实例的data里的某个数据的某个属性,可以看到该属性含有 setter、getter 方法,由此可以得知,每个属性都被添加了setter、getter 方法。
实现mvvm主要包含两个方面,数据变化更新视图,视图变化更新数据:


view更新data通过事件监听即,比如 input 标签监听 'input' 事件就可以实现。关键点在于 data 如何更新view,当数据改变,如何更新视图的。重点是如何知道数据变了,而这可以由Observer实现,通过Object.defineProperty( )对属性设置一个set函数,当数据改变了就会来触发这个函数,然后只要将一些需要更新视图的方法放在这里面就可以实现data更新view了。
1.2、observe 的实现
利用Obeject.defineProperty()来为每个属性添加setter,getter 的方法实现监听属性变动。将需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter和getter,这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化。示例代码:
var data = { name: 'kindeng' }; observe(data); data.name = 'dmq'; // 哈哈哈,监听到值变化了 kindeng --> dmq function observe(data) { if (!data || typeof data !== 'object') { return; } // 取出所有属性遍历 Object.keys(data).forEach(function (key) { defineReactive(data, key, data[key]); }); }; function defineReactive(data, key, val) { observe(val); // 监听子属性 Object.defineProperty(data, key, { enumerable: true, // 可枚举 configurable: false, // 不能再define get: function () { return val; }, set: function (newVal) { console.log('哈哈哈,监听到值变化了 ', val, ' --> ', newVal); val = newVal; } }); }
通过上面代码就可以实现对每个属性进行监听。
1.3、通过JS实现简单的双向绑定
<body>
<div id="app">
<input type="text" id="txt">
<p id="show"></p>
</div>
</body>
<script type="text/javascript">
var obj = {}
Object.defineProperty(obj, 'txt', {
get: function () {
return obj
},
set: function (newValue) {
document.getElementById('txt').value = newValue
document.getElementById('show').innerHTML = newValue
}
})
document.addEventListener('keyup', function (e) {
obj.txt = e.target.value
})
</script>
上面代码中,首先 defineProperty 为每个属性添加 getter、setter 方法,当数据发生改变, setter 方法被触发,视图也发生改变。setter 里面的执行命令可以看做是一个订阅者 Watcher,将视图和数据连接起来了。最下面的代码为节点绑定方法可以看做是Compile的作用,为指令节点绑定方法,当发生视图交互时,函数被触发,数据被改变,Watcher 收到通知,视图也将发生改变。
2、浏览器渲染页面过程

(浏览器渲染引擎的渲染流程)
2.1、关键渲染路径
关键渲染路径是指浏览器从最初接收请求来的HTML、CSS、javascript等资源,然后解析、构建树、渲染布局、绘制,最后呈现给客户能看到的界面这整个过程。
所以浏览器的渲染过程主要包括以下几步:
- 解析HTML生成DOM树。
- 解析CSS生成CSSOM规则树。
- 将DOM树与CSSOM规则树合并在一起生成渲染树。
- 遍历渲染树开始布局,计算每个节点的位置大小信息。
- 将渲染树每个节点绘制到屏幕。
3、JS操作真实DOM的代价!
4、虚拟DOM的作用
虚拟DOM就是为了解决浏览器性能问题而被设计出来的。假如像上面所说的,若一次操作中有10次更新DOM的动作,会生成一个新的虚拟DOM,将新的虚拟DOM和旧的进行比较,然后将10次更新的 diff 内容保存到一个JS对象中,最终通过这个JS对象来更新真实DOM,由此只进行了一次操作真实DOM,避免大量无谓的计算量。所以,虚拟DOM的作用是将多个DOM操作合并成一个,并且将DOM操作先全部反映在JS对象中(操作内存中的JS对象比操作DOM的速度要更快),再将最终的JS对象映射成真实的DOM,交由浏览器去绘制。
5、实现虚拟DOM
虚拟DOM就是是用JS对象来代表节点,每次渲染都会生成一个VNode。当数据发生改变时,生成一个新的的VNode,通过 diff 算法和上一次渲染时用的VNode进行对比,生成一个对象记录差异,然后根据该对象来更新真实的DOM。原本要操作的DOM在vue这边还是要操作的,不过是统一计算出所有变化后统一更新一次DOM,进行浏览器DOM的一次性更新。
参考:https://baijiahao.baidu.com/s?id=1593097105869520145&wfr=spider&for=pc、https://www.jianshu.com/p/af0b398602bc
6、Vue 中路由的hash模式和history模式
Vue 中路由有 hash 模式和 history 模式,hash 模式带 # 号,history 没有这个 # 号,就是普通的 url 。可以通过在 router 中配置 mode 选项来切换模式。
Vue 中的路由是怎么实现的可以参考:https://segmentfault.com/a/1190000011967786
Vue 中路由的实现是通过监听 url 的改变,然后通过解析 url ,匹配上对应的组件进行渲染实现的。
在 hash 模式下,跳转路由导致后面 hash 值的变化,但这并不会导致浏览器向服务器发出请求。另外每次 hash 值的变化,还会触发 hashchange 这个事件,通过监听这个事件就能知道 hash 值的改变,并能解析出 url。在 hash 模式下,刷新页面和直接输入链接都不会导致浏览器发出请求。
history 模式的实现原理是通过HTML5中的两个方法:pushState 和 replaceState,这两个方法可以改变 url 地址且不会发送请求,由此可以跳转路由而不刷新页面,不发出请求。但是在 history 模式下,用户如果直接输入链接或者手动刷新时,浏览器还是会发出请求,而会导致服务器寻找该 url 路径下的对应的文件,而该路径下的文件往往不存在,所以会返回 404。为了避免这种情况,在使用 history 模式时,需要后端进行配合使用,配置在URL 匹配不到任何静态资源返回什么东西,比如可以配置在找不到文件时返回项目的主页面。
参考:https://segmentfault.com/a/1190000011967786、https://www.cnblogs.com/xufeimei/p/10745353.html