OCR技术
OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗,亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,及针对印刷字体,采用光学的方式将纸质文档中的文字装换成黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
在python中,支持ORC的模块有pytesser3和pyocr,其原理主要是通过模块功能调用OCR引擎识别图片,OCR引擎再将识别的结果返回到程序中,以pyocr为例介绍。在windows中安装pyocr可以在CMD下使用pip安装:
pip install pyocr
安装pyocr模块之后,还需要安装PIL模块,这是专门用于处理图片的模块,pyocr依赖该模块才能完成识别,pip安装如下:
pip install Pillow
完成pyocr和PIL模块的安装后,最后是OCR引擎的安装,图像识别主要由OCR引擎完成,pyocr只起到一个调用引擎的作用。
Tesseract-OCR是一个免费,开源的OCR引擎,读者可从网上自行搜索下载安装,在window系统中,OCR引擎(Tesseract-OCR)可通过.exe安装包安装。值得注意的是,在安装过程中有附加功能选项:
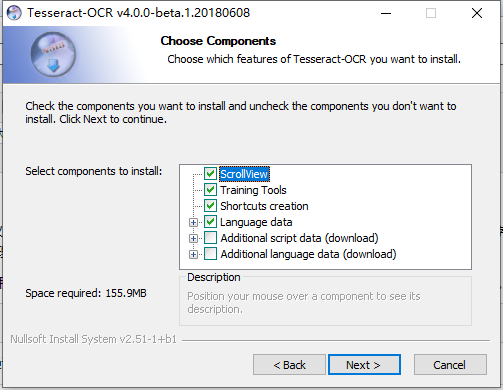
图1-1 OCR安装选项
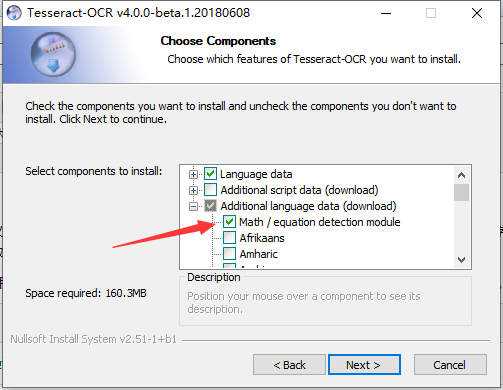
图1-2 勾选数学公式常用包以及选择语言Chinese(simplified)
完成上述安装后,就能在Python中使用pyocr实现OCR识别了,方法如下:

图1-3 待识别的图片test.png
代码如下:
from PIL import Image
from pyocr import tesseract
# 使用PIL打开图片
import os
os.chdir("C://User//yao//Desktop")
# 改变当前工作目录
im=Image.open("test.png")
#OCR识别
code=tesseract.image_to_string(im)
print(code)
运行结果如下图所示:

图1-4 识别结果
在实际使用时,验证码图片不会是一张白底黑字的图片,往往会掺入很多干扰因素,这样会导致识别出来的结果与实际相差甚大,为了提高准确率,可以使用PIL模块对图片进行简单的处理。
不同的图片有不同的处理方法,其目的是提高OCR识别的准确率。除此之外,提高OCR准确率还可以对OCR引擎进行训练和学习。但两者已经属于人工智能的领域。