本周主要是熟悉HDFS的操作。
在虚拟机安装好Hadoop后,我需要先熟悉下其自带的HDFS文件系统以及MapReduce的一系列操作,为接下来HBase的学习做好铺垫。因为HBase的文件存储系统是HDFS、数据处理方式是MapReduce,在很多操作上面有很多需要操作HDFS来进行的,所以我需要在实机上面配置好eclipse的插件和配置。
首先是启动Hadoop。
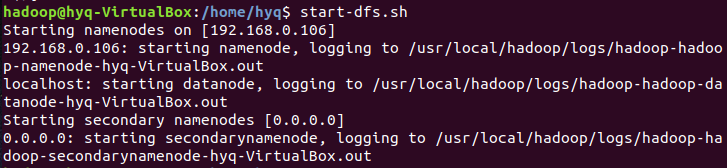
之前配置Hadoop时把core-site.xml中我用来测试的localhost改成虚机ip,并且之前就把Ubuntu的防火墙关闭,保证实机上的eclipse能够访问,否则会出现
java.lang.IllegalArgumentException: Wrong FS: hdfs://192.168.0.107:9000/user/hadoop/test.txt, expected: hdfs://192.168.0.106:9000
的情况。
然后在eclipse上就可以创建一个java项目,导入hadoop-common-2.7.7.jar和hadoop-hdfs-2.7.7.jar(同时也必须导入这两个jar包所依赖的lib,所幸俩依赖的差不多一样),然后编写一个测试用例。
package Chapter3; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class test { public static void main(String[] args) { try { String filename = "hdfs://192.168.0.106:9000/user/hadoop/test.txt"; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); if(fs.exists(new Path(filename))){ System.out.println("文件存在"); }else{ System.out.println("文件不存在"); } } catch (Exception e) { e.printStackTrace();} } }
同时需要把Hadoop两个核心配置文件加入bin文件夹中——
然后就可以顺利运行了。

这次主要测试实机访问虚机Hadoop、eclipse的MapReduce插件以及几个HDFS的基本操作方式,之后HBASE里也会用到hdfs的操作,之后会加深学习。