# -*- coding:utf-8 -*-
"""获取时光影评电影"""
import requests
from bs4 import BeautifulSoup
from datetime import datetime,timedelta
import pymysql
#xlwt-1.3.0
#from xlwt.xlwt import *
from xlwt import *
#获取指定开始排行的电影url
def get_url(root_url,start):
return root_url+"?start="+str(start)+"&"
def get_review(page_url):
"""获取电影相关的信息"""
movies_list = []
reponse = requests.get(page_url)
soup =BeautifulSoup(reponse.text,'lxml')
soup = soup.find("ol","grid_view")
dict ={}
for tag_li in soup.find_all("li"):
dict = {}
dict['rank'] = tag_li.find("em").string
dict['title'] = tag_li.find_all("span","title")[0].string
dict['score'] = tag_li.find("span","rating_num").string
if tag_li.find("span","inq"):
dict['desc'] =tag_li.find("span","inq").string
else:
dict['desc'] = '无评词'
movies_list.append(dict)
return movies_list
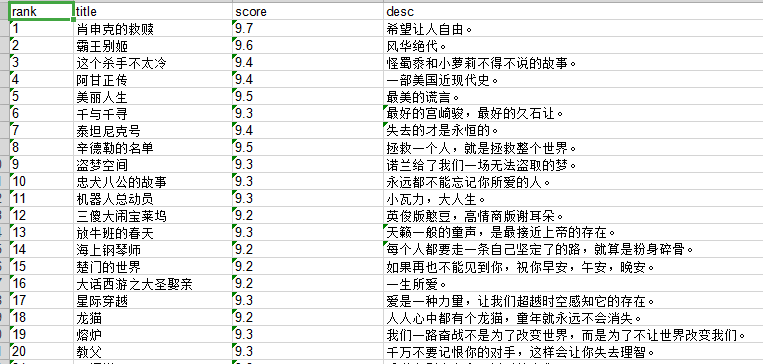
def save_excel(movies_list):
keys =""
w = Workbook()
ws = w.add_sheet("movies")
for i in movies_list:
keys = list(i.keys())
for i in range(len(keys)):
ws.write(0,i,keys[i])
for movies in range(len(movies_list)):
for key,value in movies_list[movies].items():
keys = list(movies_list[movies].keys())
#找到key的index
ws.write(movies+1,keys.index(key),value)
w.save("movies.xls")
if __name__ == '__main__':
root_url = "https://movie.douban.com/top250"
start =0
movies_list =get_review(get_url(root_url,start))
save_excel(movies_list)