场景->需求->解决方案->应用->原理
我该如何去设计消息中间件--借鉴/完善
场景
跨进程通信(进程间生产消费模型)
需求
-
实现消息的发送和接收。
NIO通信 (序列化/反序列化)--dubbo、avro、protobuf、zk(jute)
-
实现消息的存储(持久化/非持久化)
数据库存储、文件存储(磁盘:顺序读写、页缓存、持久化的时机(落盘策略)、零拷贝)、内存
-
是否支持跨语言(多语言生态)
-
消息的确认(确认机制)--在跨进程通信中 ->业务逻辑需求
-
是否支持集群
自己实现选举、第三方的实现(zk)
高级需求
-
是否支持有序(业务逻辑)
-
是否支持事务消息(业务逻辑)->最终一致性
-
是否支持高并发和大数据的存储
-
是否支持可靠性存储
-
是否支持多协议
-
是否收费
发展
pub/sub--金融领域--TIB(规则)
非个性化需求, 而是共性化需求
IBM websphere mq(商业)
JMS协议->Java api->AMQP(通用性)
kafka
-
起源:LinkedIn 活动流 运营数据 诞生之初就是为了解决大数据量的问题
-
简介
实现语言:scala
-
架构图
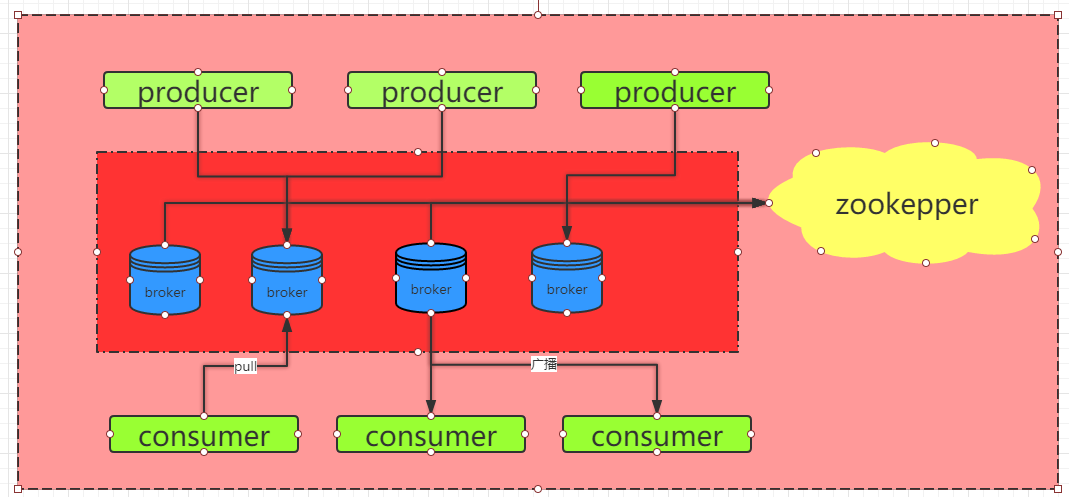
-
下载及安装及启动
单节点安装:
sudo wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz注意點:
-
必须安装zk(启动时必须先启动zk),详情请参考
-
远程安装 必须修改一下两个属性
#本机ip
listeners=PLAINTEXT://‘本机ip’:9092
#zk地址
zookeeper.connect=localhost:2181启动命令:(server.properties文件自行拷贝)
[root@k8s-master bin]# sh kafka-server-start.sh server.properties -
-
集群安装:
-
多机器部署
-
伪集群部署
-
-
基本操作