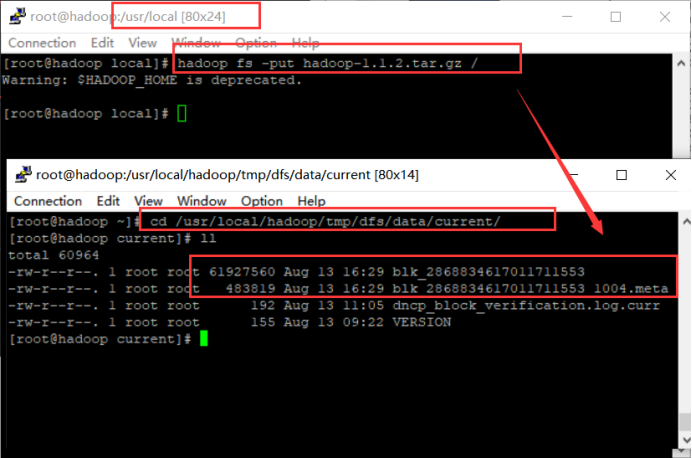
HDFS作为分布式文件管理系统,Hadoop的基础。HDFS体系机构包括:NameNode、DataNode、SecondaryNameNode。Hadoop shell上传的文件是存放在DataNode的block中,通过linux shell只能看到block,不能看到文件。
以下是本章的重点:
- 分布式文件系统与HDFS
- HDFS体系结构与基本概念
- HDFS的shell操作
- 搭建eclipse开发环境
- Java接口及常用api
- Hadoop的RPC机制
- Hadoop读写数据的过程分析
1.分布式文件系统与HDFS
DFS:Distributed File System
分布式文件管理系统:数据量越来越多,在一个操作系统管辖的范围存不下,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件。分布式文件管理系统就是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
HDFS只是DFS中的一种,适应于一次写、多次查询的情况,不支持并发写情况,小文件不合适。HDFS:把客户端的大文件存放在很多节点的数据块中,记住三个关键词:文件、节点、数据块。
更简单的一点来说:HDFS就是windows中存在的文件系统。
2.HDFS的shell操作
HDFS是存取数据的分布式文件系统,对HDFS的操作,就是文件系统的基本操作,比如文件的创建、修改、删除、修改权限等,文件夹的创建、删除、重命名等。对HDFS的操作命令类似于linux的sehll对文件的操作,如ls、mkdir、rm等。
对hdfs的操作方式:hadoop fs xxx
hadoop fs -ls / ----查看hdfs根目录下的内容的
hadoop fs -lsr / ----递归查看hdfs的根目录下的内容的
hadoop fs -mkdir /d1 ----在hdfs上创建文件夹d1
hadoop fs -put <linux source > <hdfs destination> ----把数据从linux上传到hadfs的特定路径中
hadoop fs -get <hdfs source> <linux destination>----把数据从hdfs下载到linux的特定路径下
hadoop fs -text <hdfs文件> ----查看hdfs文件
hadoop fs -rm 删除具体的文件 ----删除hdfs中文件
hadoop fs -rmr 删除具体的文件夹 ----删除hdfs中的文件夹
具体命令:
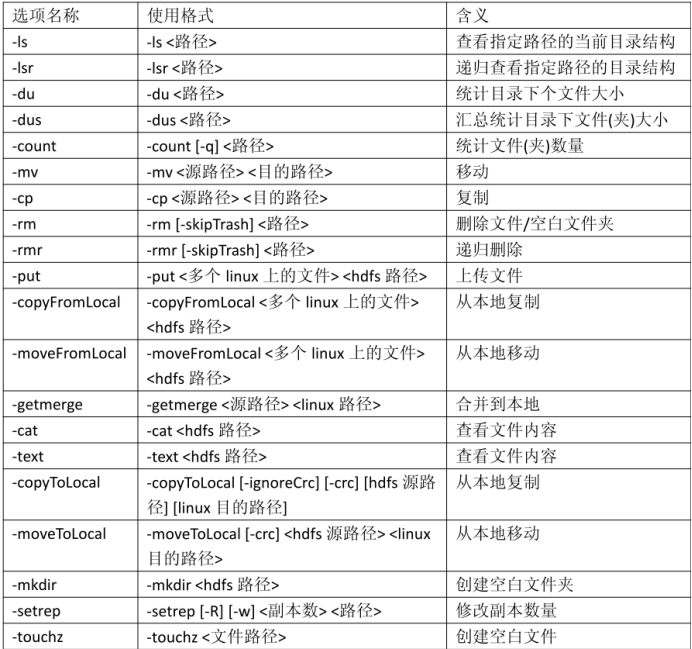
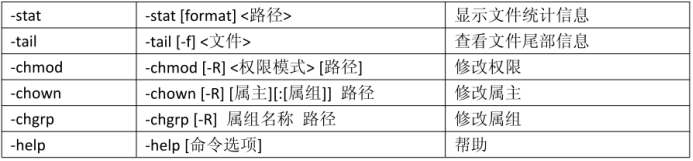
注意:以上表格中对于路径,包括 hdfs 中的路径和 linux 中的路径。对于容易产生歧义的地方,会特别指出“linux 路径”或者“hdfs 路径”。如果没有明确指出,意味着是 hdfs
路径。
比如:

红框内-内容格式如下:l
-首字母表示文件夹(如果是“d”)还是文件(如果是“-”);
-后面的 9 位字符表示权限;
-后面的数字或者“-”表示副本数。如果是文件,使用数字表示副本数;文件夹没有副本;
-后面的“root”表示属主;
-后面的“supergroup”表示属组;
-后面的“0”、“6176”、“37645”表示文件大小,单位是字节;
-后面的时间表示修改时间,格式是年月日时分;
-最后一项表示文件路径。
hdfs帮助文档:hadoop fs -help +具体的命令


3.NameNode(管理节点)
NameNode作用是管理文件目录结构,是管理数据节点。名字节点维护两套数据,一套是文件目录与数据块之间的关系,另一套是数据块与节点之间的关系。前一套数据是静态的,是存放在磁盘上得,通过fsimage和edits文件来维护;后一套数据是动态的,不持久化到磁盘的,每当集群启动的时候,会自动建立这些信息。
NameNode包含整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。core-default.xml中的dfs.name.dir属性、dfs.name.edits.dir属性,配置的是NameNode的核心文件fsimage、edits的存放位置。
文件包括:
- fsimage:元数据镜像文件,存储某一时段NameNode内存元数据信息。
- edits:操作日志文件
- fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
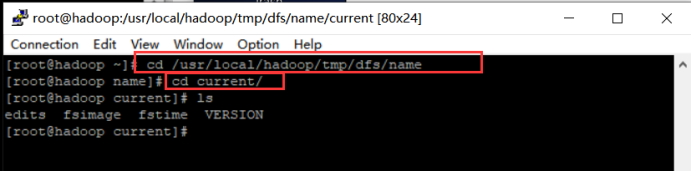
具体路径:/usr/local/hadoop/tmp、/usr/local/hadoop/tmp/dfs/name目录下。
4.SecondaryNameNode
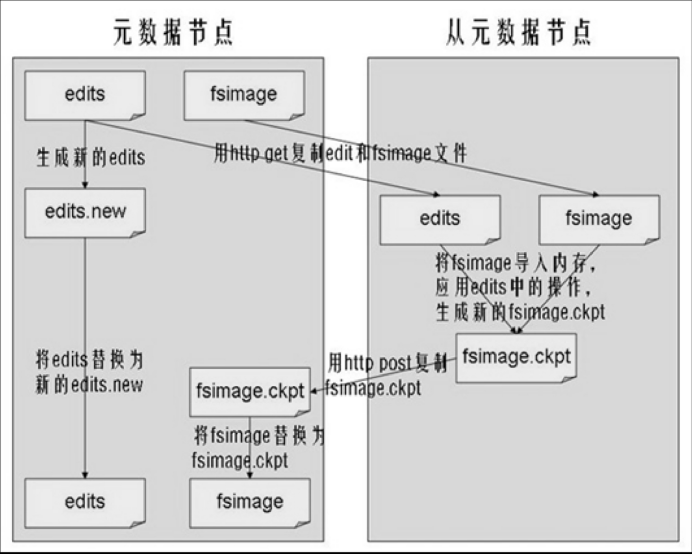
SecondaryNameNode作用:合并NameNode中的edits到fsimage中。
执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.
默认在安装在NameNode节点上。
合并原理:
5.Datanode(存储数据)
DataNode作用:HDFS中真正存储数据的。
提供真实文件数据的存储服务:
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block.HDFS默认Block大小是64MB,以一个256MB文件,共有256/64=4个Block。core-default.xml中找到参数ds.block.name去修改block的大小。
- 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
- replication,多复本。默认是三个。hdfs-site.xml的dfs.replication属性。
DataNode存放的目录:core-default.xml中参数dfs.data.dir的值就是block存放在linux文件系统中的位置。