传统ELK图示:
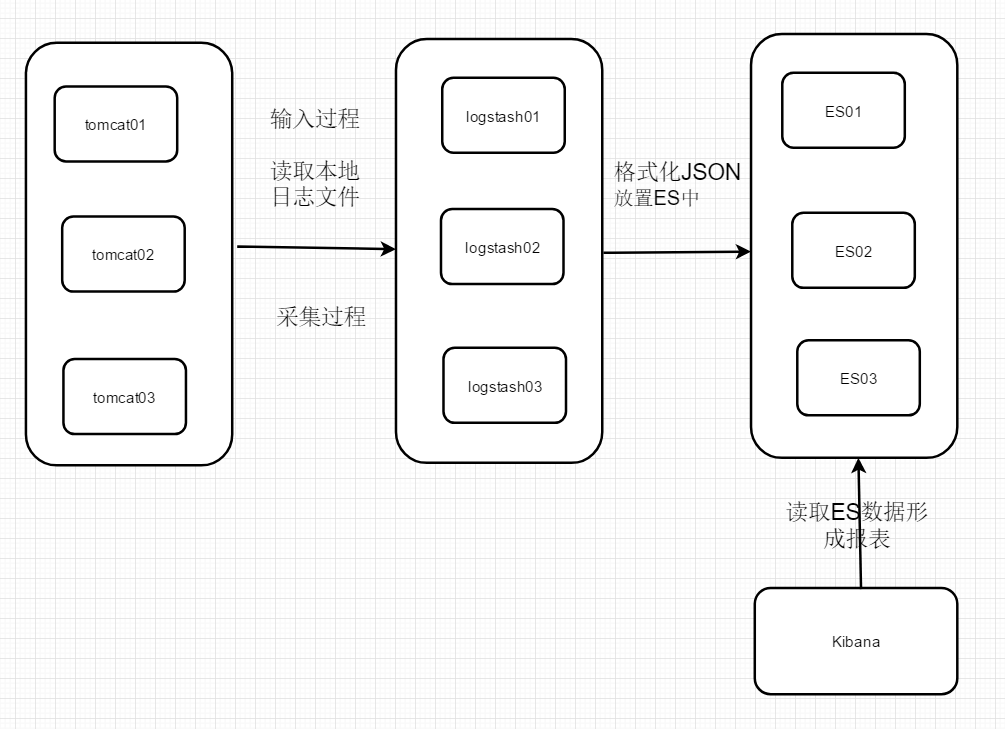
单纯使用ElK实现分布式日志收集缺点?
1、logstash太多了,扩展不好。
如上图这种形式就是一个 tomcat 对应一个 logstash,新增一个节点就得同样的拥有 logstash,可以说很浪费了。
2、读取IO文件,可能会产生日志丢失。
3、不是实时性
比如logstash,底层通过定时器发现数据库发生变化后才去同步,由于是定时则必然出现延迟。
那么既然出现了这些问题,有什么解决方案呢?
安装kafka
kafka是基于发布订阅模式的,类似于生产者与消费者。
一张图搞懂 kafka 的作用:

思考问题:
1. Logstash输入来源有那些?
本地文件、kafka、数据库、mongdb、redis等
2. 那些日志信息需要输入logstash
error级别
3. AOP 异常通知 服务与服务之间如何区分日志索引文件
服务名称
4. 在分布式日志收集中,相同的服务集群的话是不需要区分日志索引文件。
5. 目的为了 统一管理相同节点日志我信息。
6. 相同的服务集群的话,是是不需要区分日志索引文件 搜索日志的时候,如何定位服务器节点信息呢?
未完待续。