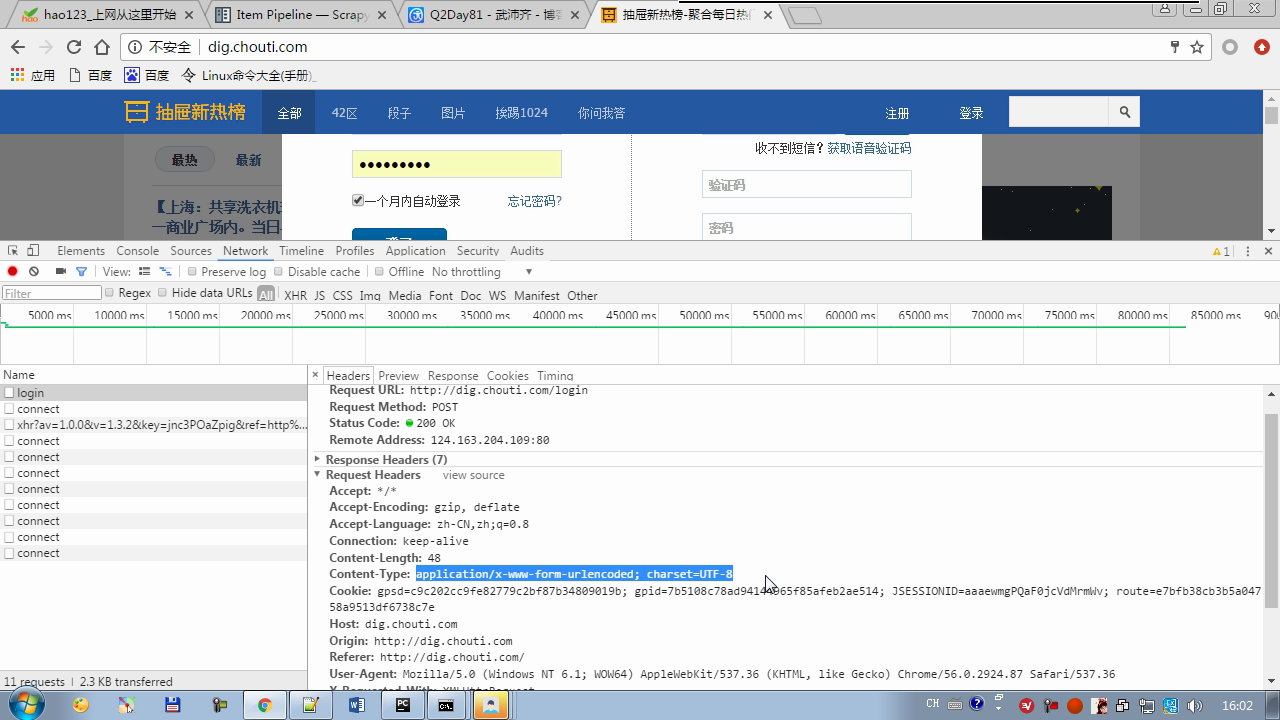
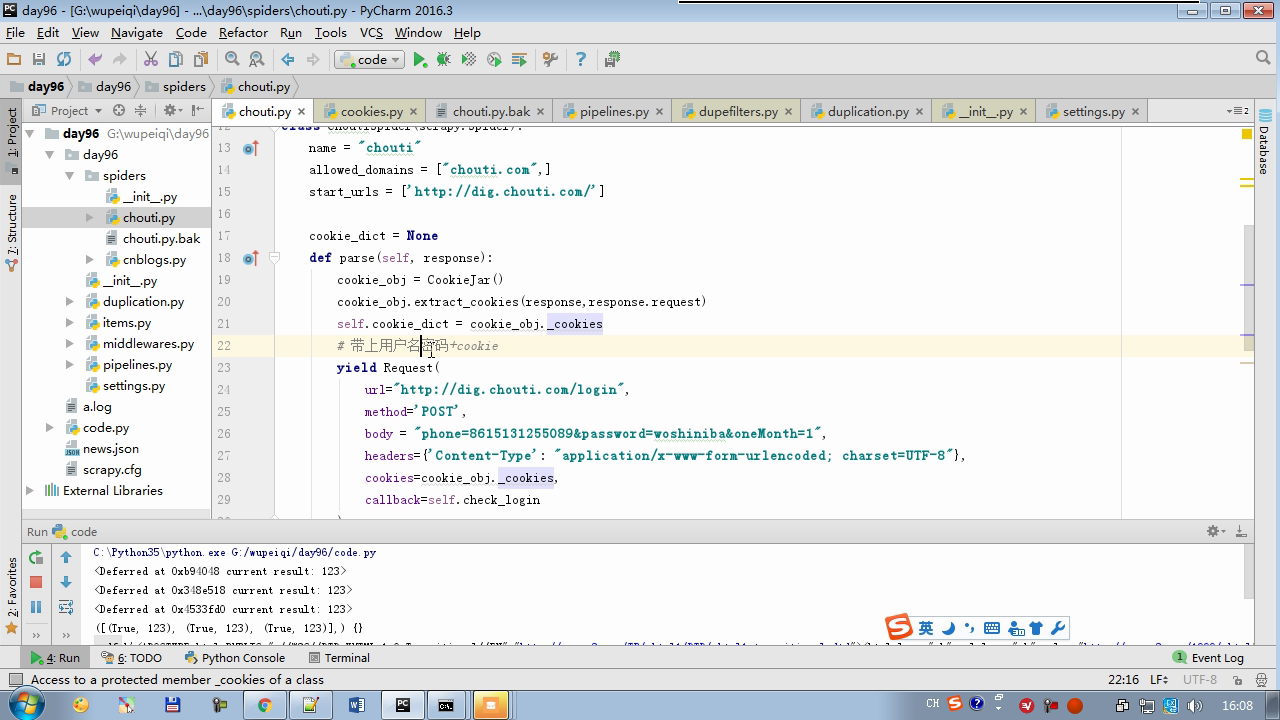
Content-type 要放在请求头里
yield Request中body格式注意不是字典形式


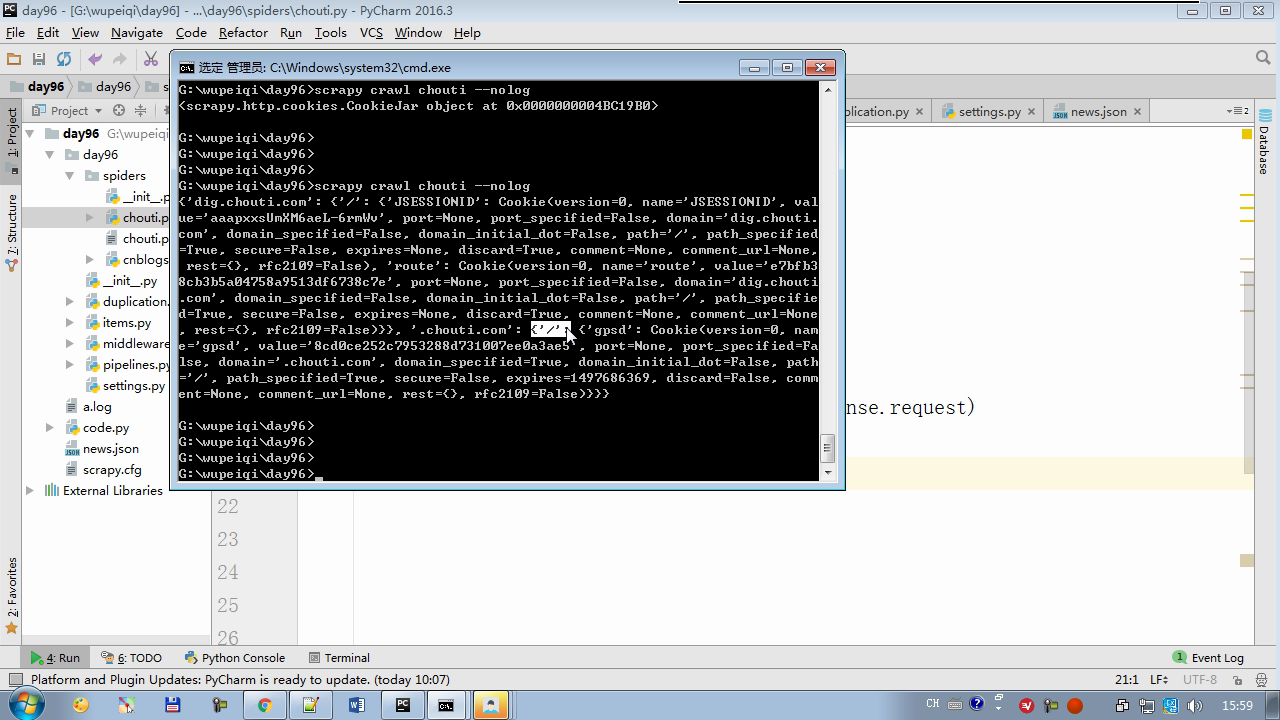
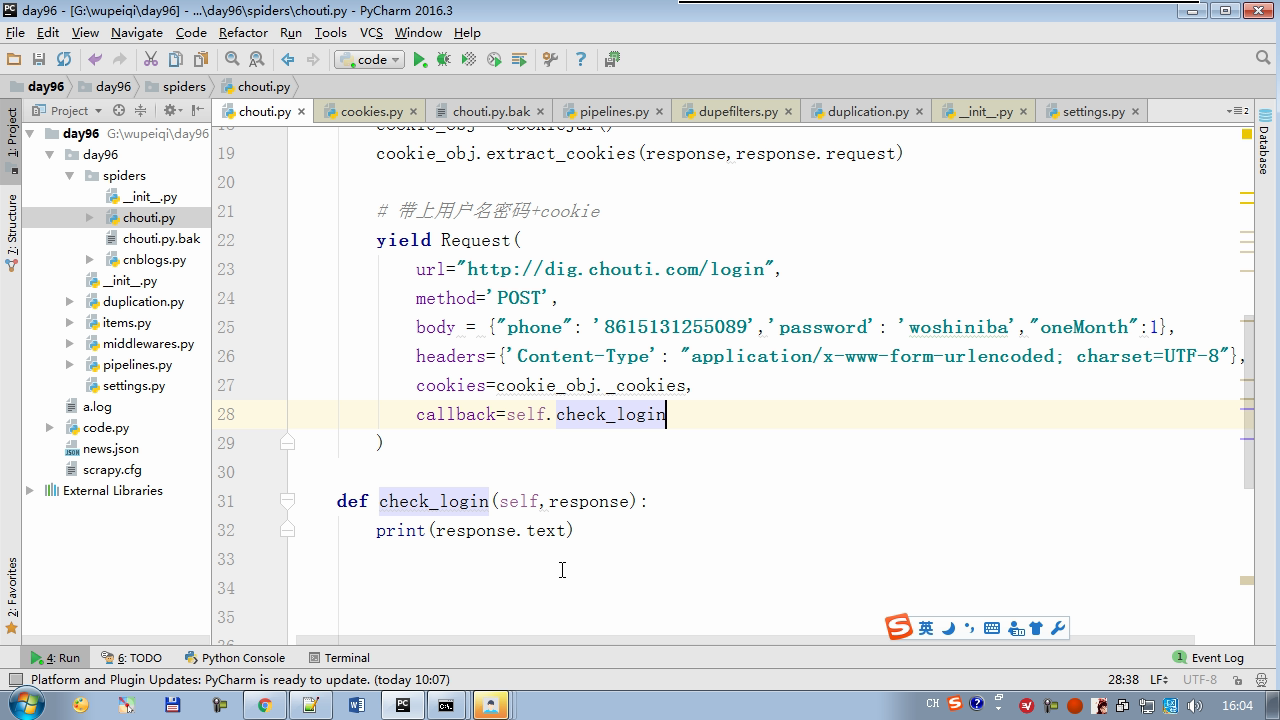
# -*- coding: utf-8 -*- import scrapy import sys import io from scrapy.http import Request from scrapy.selector import Selector, HtmlXPathSelector from ..items import ChoutiItem sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') from scrapy.http.cookies import CookieJar class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com",] start_urls = ['http://dig.chouti.com/'] cookie_dict = None def parse(self, response): cookie_obj = CookieJar() cookie_obj.extract_cookies(response,response.request) self.cookie_dict = cookie_obj._cookies # 带上用户名密码+cookie yield Request( url="http://dig.chouti.com/login", method='POST', body = "phone=8615131255089&password=woshiniba&oneMonth=1", headers={'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8"}, cookies=cookie_obj._cookies, callback=self.check_login ) def check_login(self,response): print(response.text) yield Request(url="http://dig.chouti.com/",callback=self.good) def good(self,response): id_list = Selector(response=response).xpath('//div[@share-linkid]/@share-linkid').extract() for nid in id_list: print(nid) url = "http://dig.chouti.com/link/vote?linksId=%s" % nid yield Request( url=url, method="POST", cookies=self.cookie_dict, callback=self.show ) # page_urls = Selector(response=response).xpath('//div[@id="dig_lcpage"]//a/@href').extract() # for page in page_urls: # url = "http://dig.chouti.com%s" % page # yield Request(url=url,callback=self.good) def show(self,response): print(response.text)