方式一:python之收集整个网站数据
目的:
建立一个爬虫和数据收集程序(数据打印)
1:代码
# coding=utf-8
"""
@author: jiajiknag
程序功能:收集整个网站数据
建立一个爬虫和数据收集程序(数据打印)
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
# 全集变量集合
global pages
# urlopen 用来打开并读取一个从网络获取的远程对象
html = urlopen("http://en.wikipedia.org"+pageUrl)
# 创建BeautifulSoup对象
bs0bj = BeautifulSoup(html)
try:
print(bs0bj.h1.get_text())
print(bs0bj.find(id="mw-content-text").findAll("p")[0])
print(bs0bj.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺少一些属性,不用担心")
# 遍历,以/wiki/开头
for link in bs0bj.findAll("a",href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
# 新页面
newPage = link.attrs['href']
# 虚线作用:分离不同的页面内容
print("-------------------------------\n"+newPage)
# 添加新页面
pages.add(newPage)
# 或许新页面
getLinks(newPage)
# 先处理一个空URL
getLinks("")2:结果
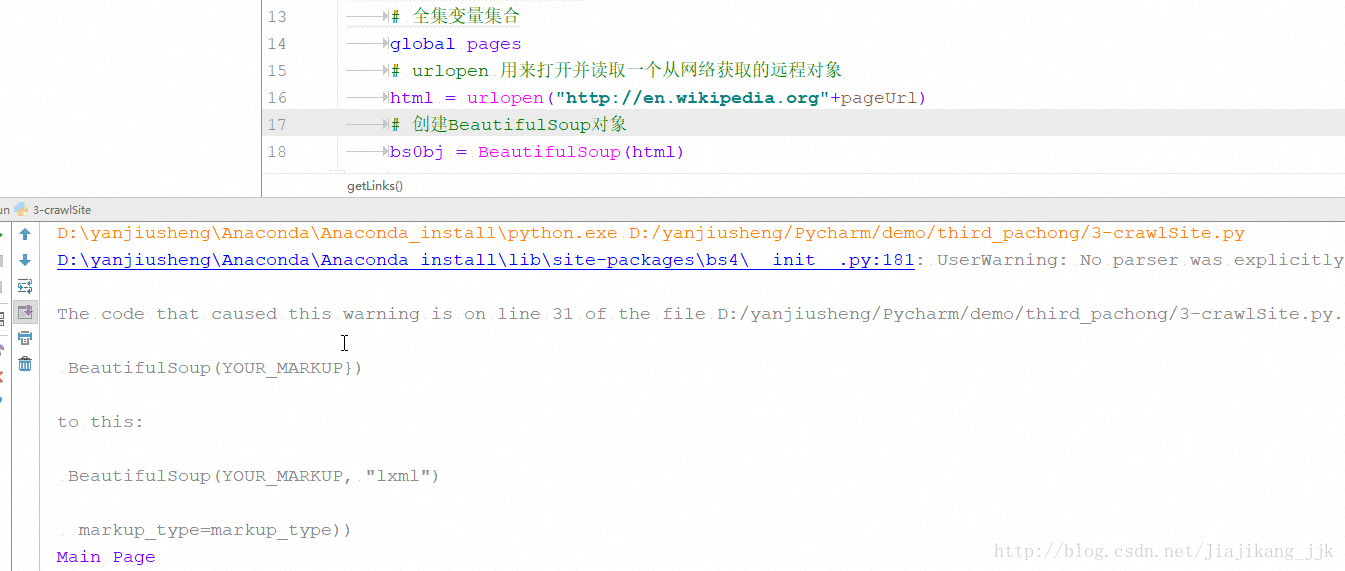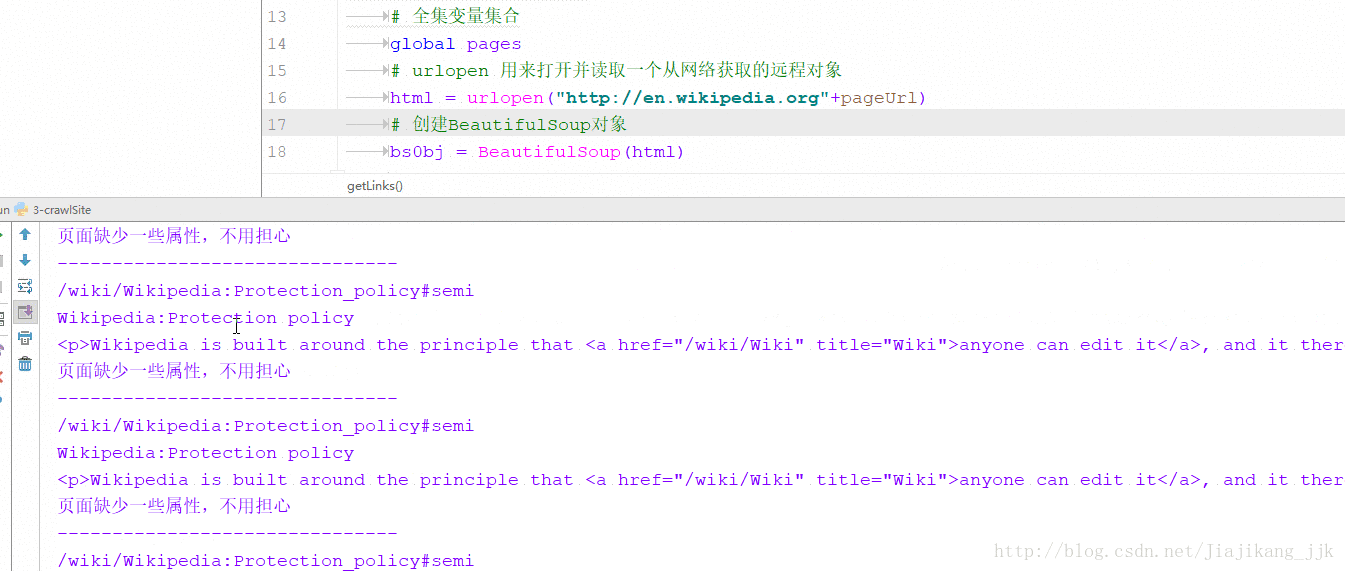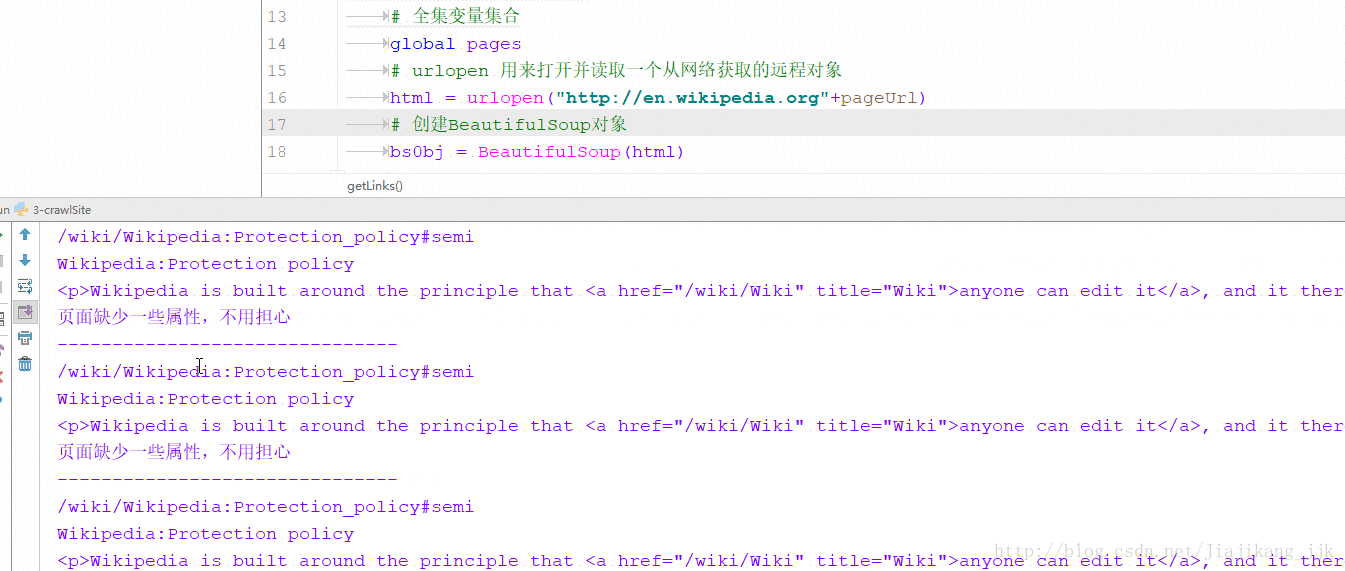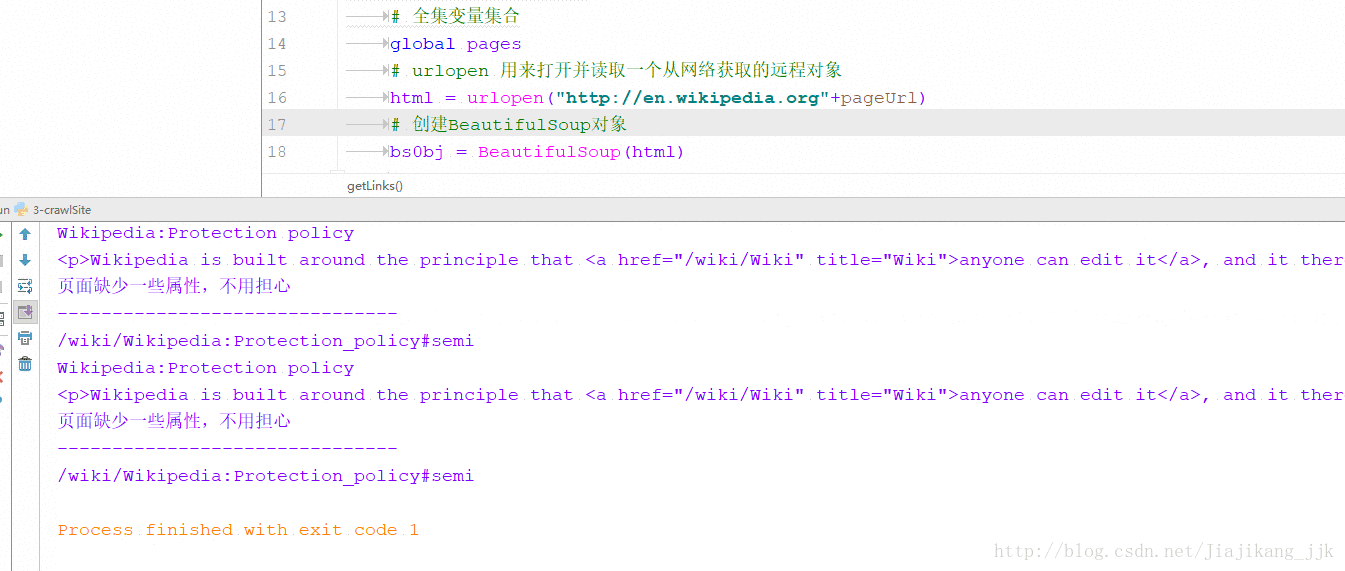
方式二:通过互联网采集->从一个外链随意跳转到另一个外链:获得随机外链
1:代码
# coding=utf-8
"""
@author: jiajiknag
程序功能: 通过互联网采集-从一个外链随意跳转到另一个外链
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
# 随机发送当前时间
# random.seed()是随机数种子,也就是为随机数提供算法,完全相同的种子产生的随机数列是相同的
random.seed(datetime.datetime.now())
# 获取页面所以内链的列表
def getInternalLinks(bs0bj, includeUrl):
internalLinks = []
# 找出所有以“\”开头的链接
for link in bs0bj.findAll("a",href=re.compile("^(/|.*)"+includeUrl)):
if link.attrs['href'] not in internalLinks:
internalLinks.append(link.attrs['href'])
return internalLinks
# 获取页面所有外链的列表
def getExternalLinks(bs0bj,excludeUrl):
externalLinks = []
# 找出所有以“http”或者“www”开头且包含当前的url的链接
for link in bs0bj.findAll("a", href=re.compile("^(http|www)((?!"+ excludeUrl+").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in excludeUrl:
externalLinks.append(link.attrs['href'])
return excludeUrl
# 爬去地址
def splitAddress(address):
addressParts = address.replace("http://", "").split("/")
return addressParts
# 获取随机外链接
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bs0bj = BeautifulSoup(html)
# [0]--返回一个列表,获取外链
externalLinks = getExternalLinks(bs0bj, splitAddress(startingPage)[0])
if len(externalLinks) ==0:
# 既然不是外链,那就是内链
internalLinks = getInternalLinks(startingPage)
# 返回获得的随机外链
return getRandomExternalLink(internalLinks[random.randint(0,len(internalLinks)-1)])
else:
return externalLinks[random.randint(0,len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink("http://oreilly.com")
print("随机外链是:", externalLink)
followExternalOnly(externalLink)
followExternalOnly("http://oreilly.com")
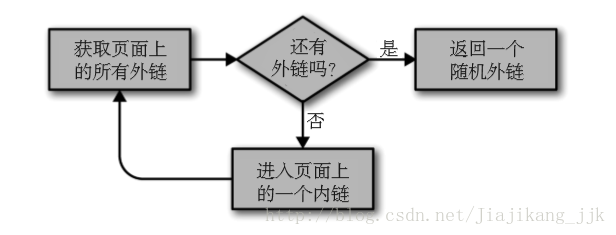
2:流程图
3:结果
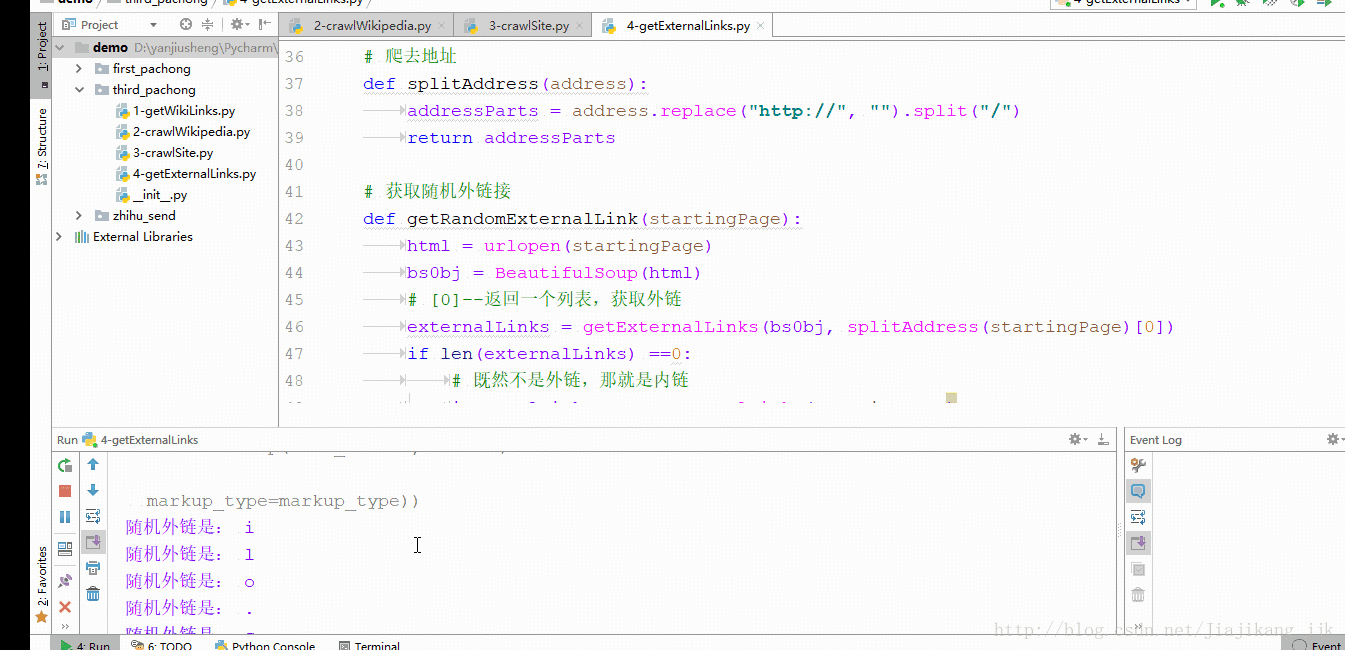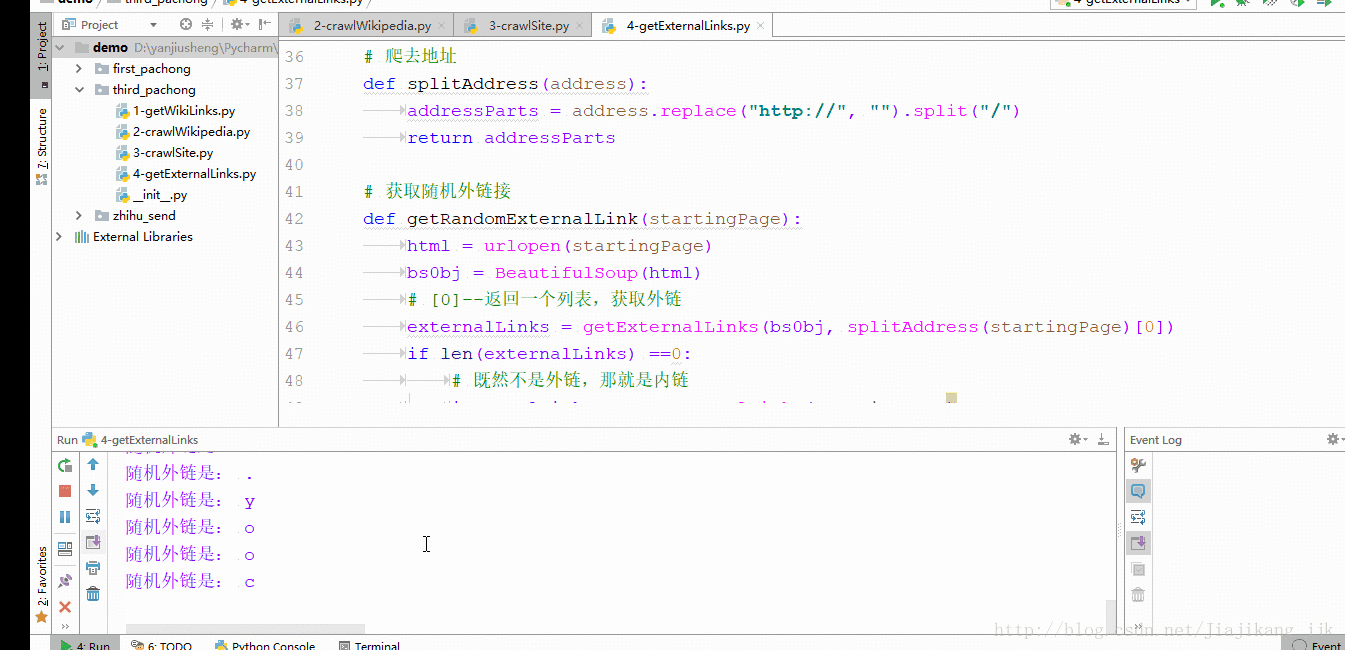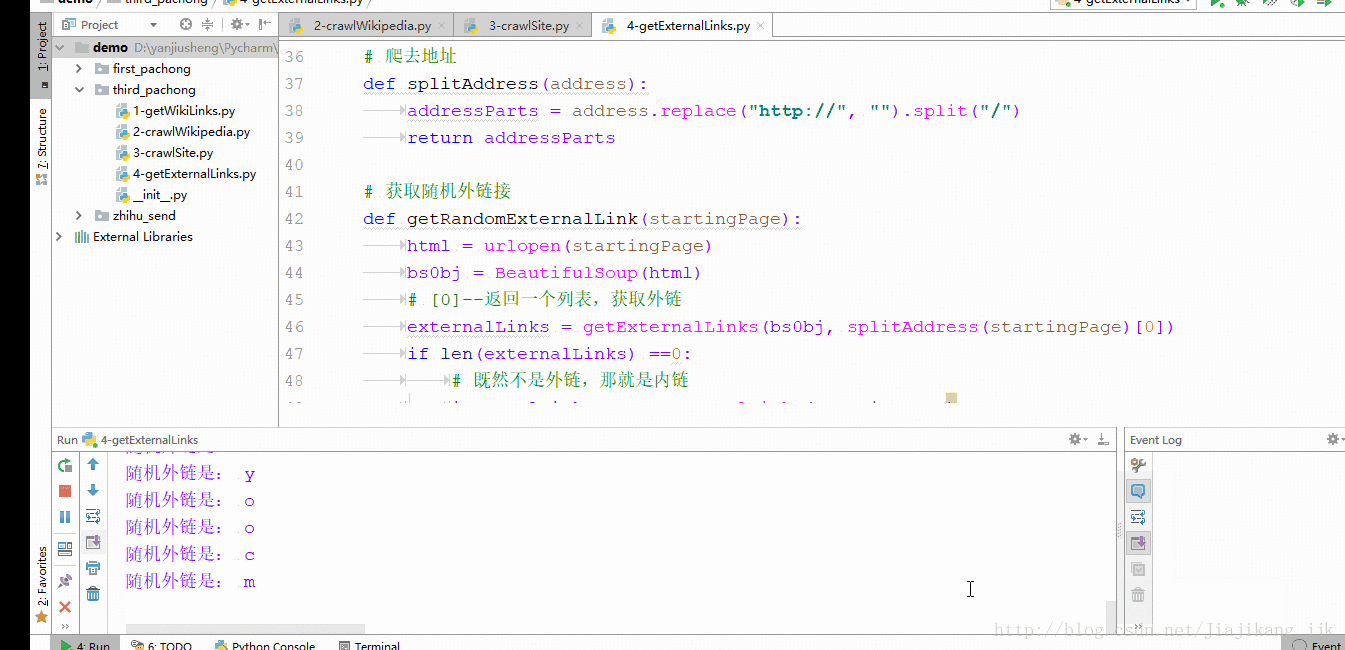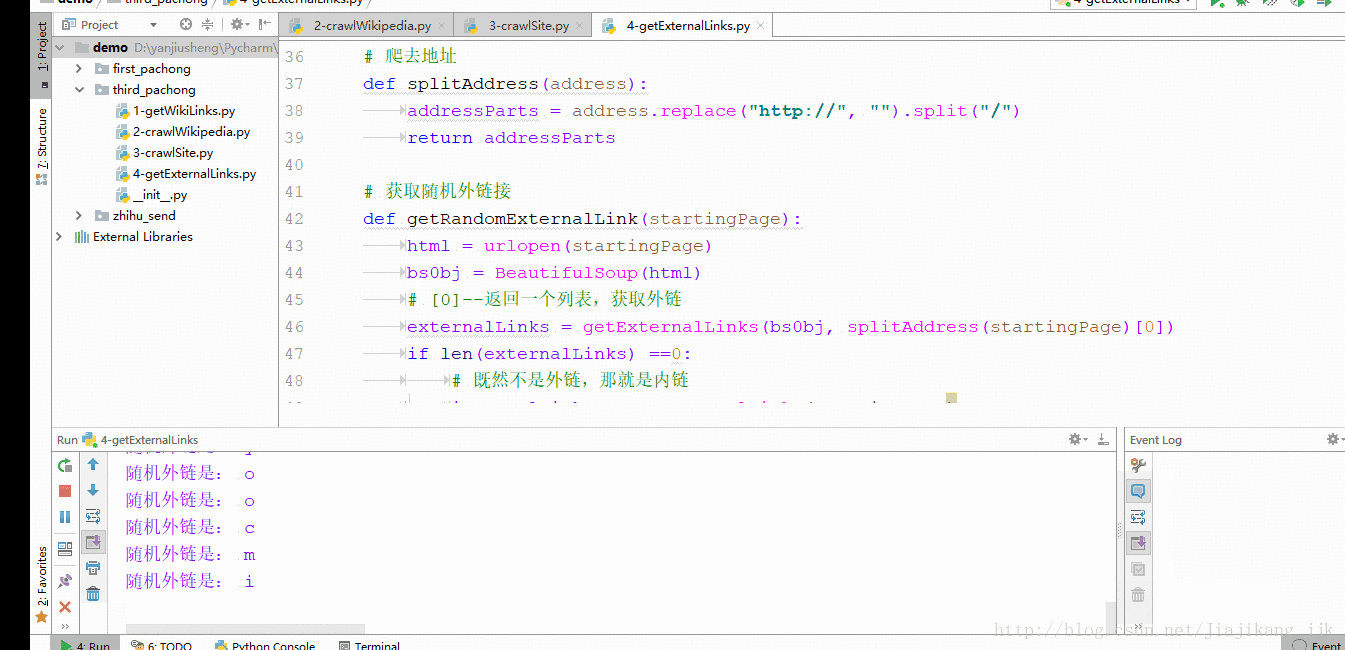
方式三: 收集网站上所有的外链
1:代码
# coding=utf-8
"""
@author: jiajiknag
程序功能:
"""
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
# 所有内部链接的列表
def getInternalLinks(bsObj, includeUrl):
includeUrl = urlparse(includeUrl).scheme + "://" + urlparse(includeUrl).netloc
internalLinks = []
# 查找所有以“/”开头的链接
for link in bsObj.findAll("a", href=re.compile("^(/|.*" + includeUrl + ")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
if (link.attrs['href'].startswith("/")):
internalLinks.append(includeUrl + link.attrs['href'])
else:
internalLinks.append(link.attrs['href'])
return internalLinks
# 所有外部链接的列表
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
# 查找以“http”或“www”开头的所有链接
# 不包含当前的URL
for link in bsObj.findAll("a", href=re.compile("^(http|www)((?!" + excludeUrl + ").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bsObj = BeautifulSoup(html, "html.parser")
externalLinks = getExternalLinks(bsObj, urlparse(startingPage).netloc)
if len(externalLinks) == 0:
print("没有外部链接")
domain = urlparse(startingPage).scheme + "://" + urlparse(startingPage).netloc
internalLinks = getInternalLinks(bsObj, domain)
return getRandomExternalLink(internalLinks[random.randint(0, len(internalLinks) - 1)])
else:
return externalLinks[random.randint(0, len(externalLinks) - 1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print("随机的外部链接是: " + externalLink)
followExternalOnly(externalLink)
# 收集一个网站上所有的外链接,并记录每一个外链
allExtLinks = set()
allIntLinks = set()
def getAllExternalLinks(siteUrl):
html = urlopen(siteUrl)
domain = urlparse(siteUrl).scheme + "://" + urlparse(siteUrl).netloc
bsObj = BeautifulSoup(html, "html.parser")
internalLinks = getInternalLinks(bsObj, domain)
externalLinks = getExternalLinks(bsObj, domain)
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.add(link)
print(link)
for link in internalLinks:
if link not in allIntLinks:
allIntLinks.add(link)
getAllExternalLinks(link)
# 创建对象
followExternalOnly("http://oreilly.com")
# 添加
allIntLinks.add("http://oreilly.com")
# 创建对象
getAllExternalLinks("http://oreilly.com")
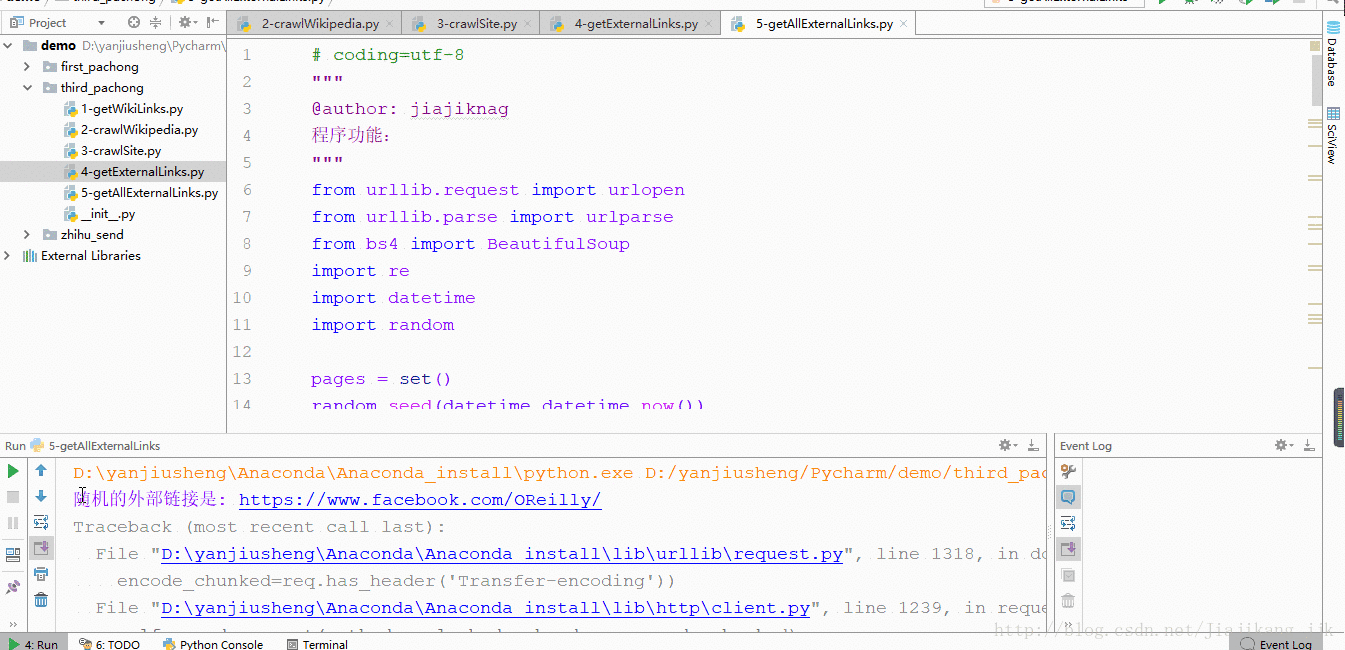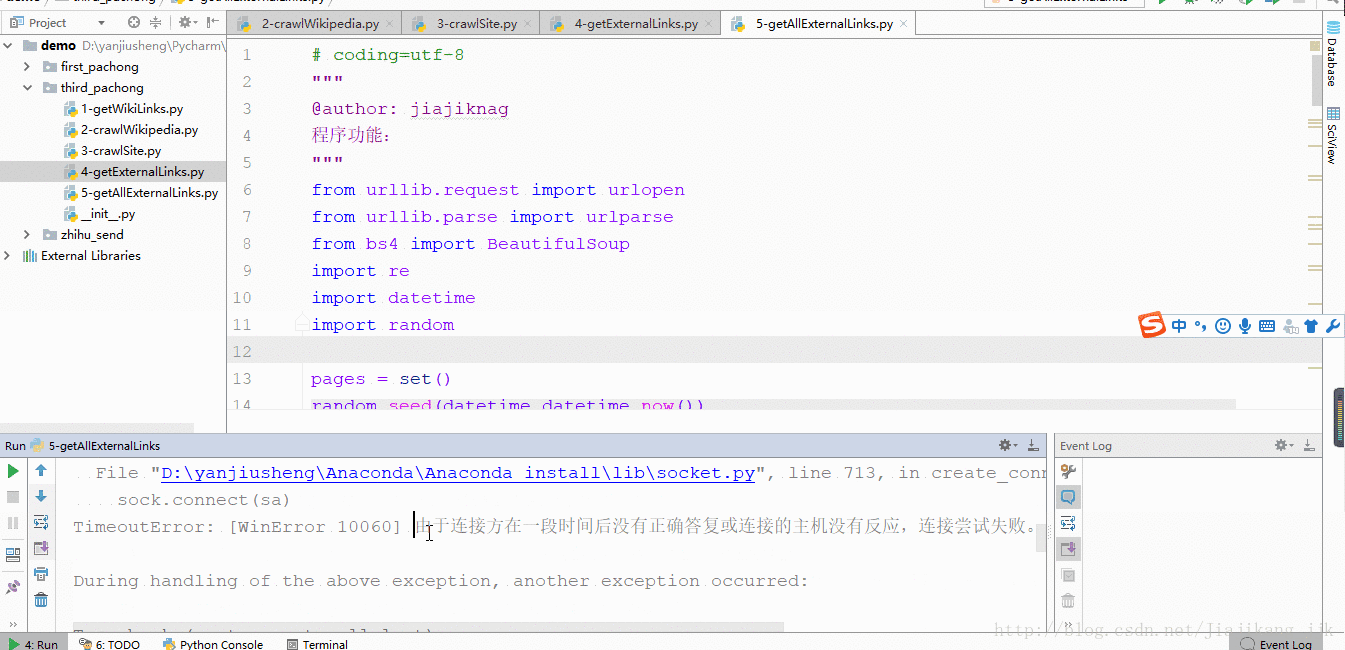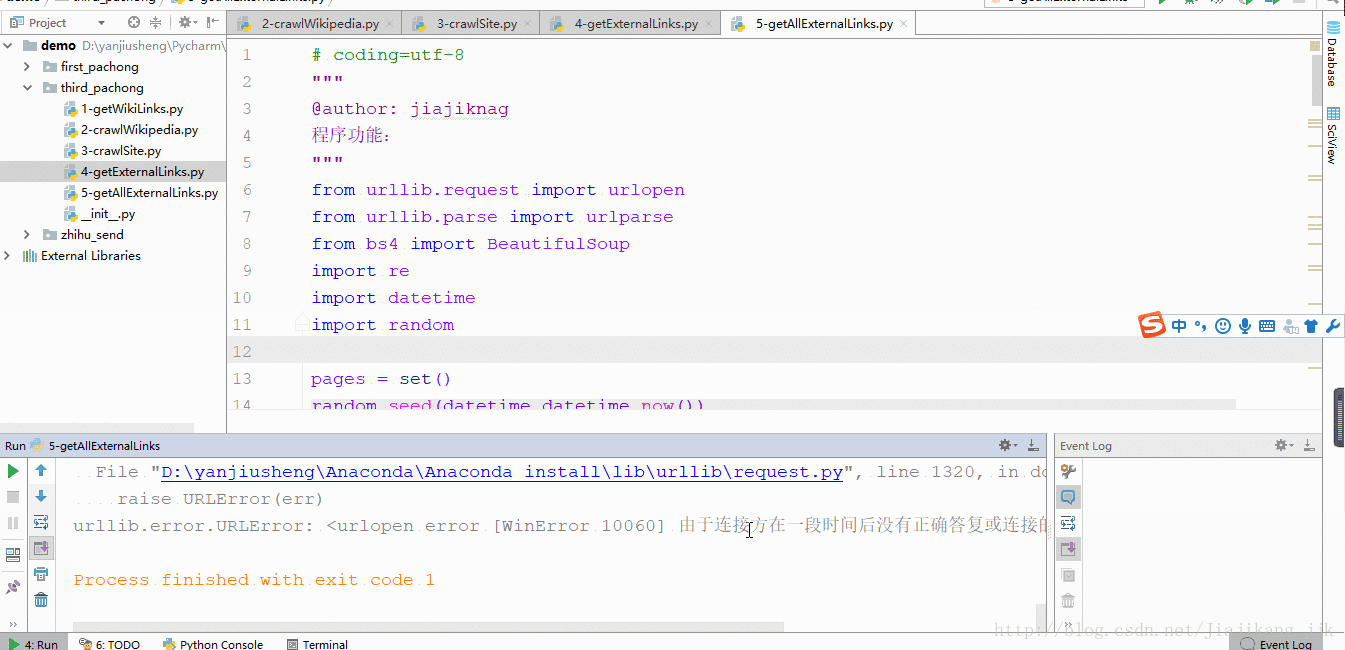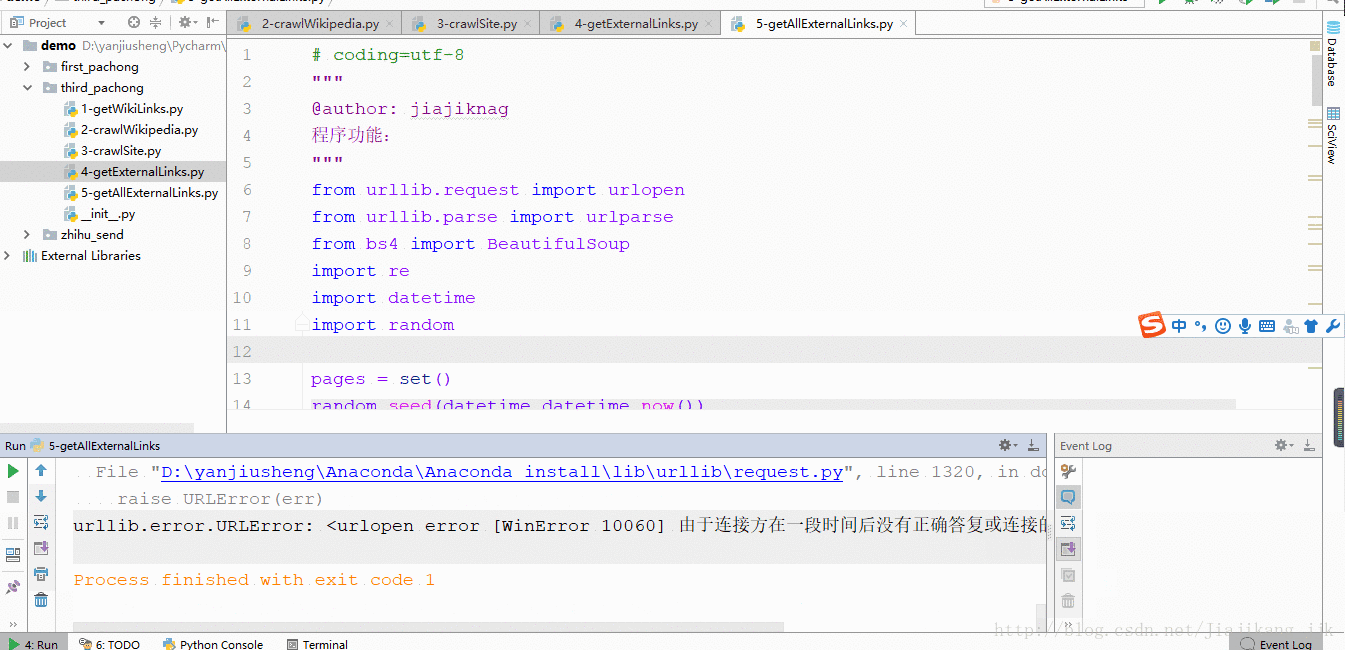
2:结果
博主这里可能请求过于频繁所以才导致如下结果啊。
注:小伙伴浏览到这可以提出建议和意见,,,