https://www.cnblogs.com/combfish/p/7830807.html
发现了一款比较方便标注的工具
https://github.com/jiesutd/SUTDAnnotator ,使用python2编写的界面,相对比较轻量,适合个人使用。但如果是团体使用的,还是web界面的会比较好。
运行Annotator_backup.py得到如下界面:open导入文件,选中要标注的词语,按下已设定好的快捷键A-V,即可完成对应的标注
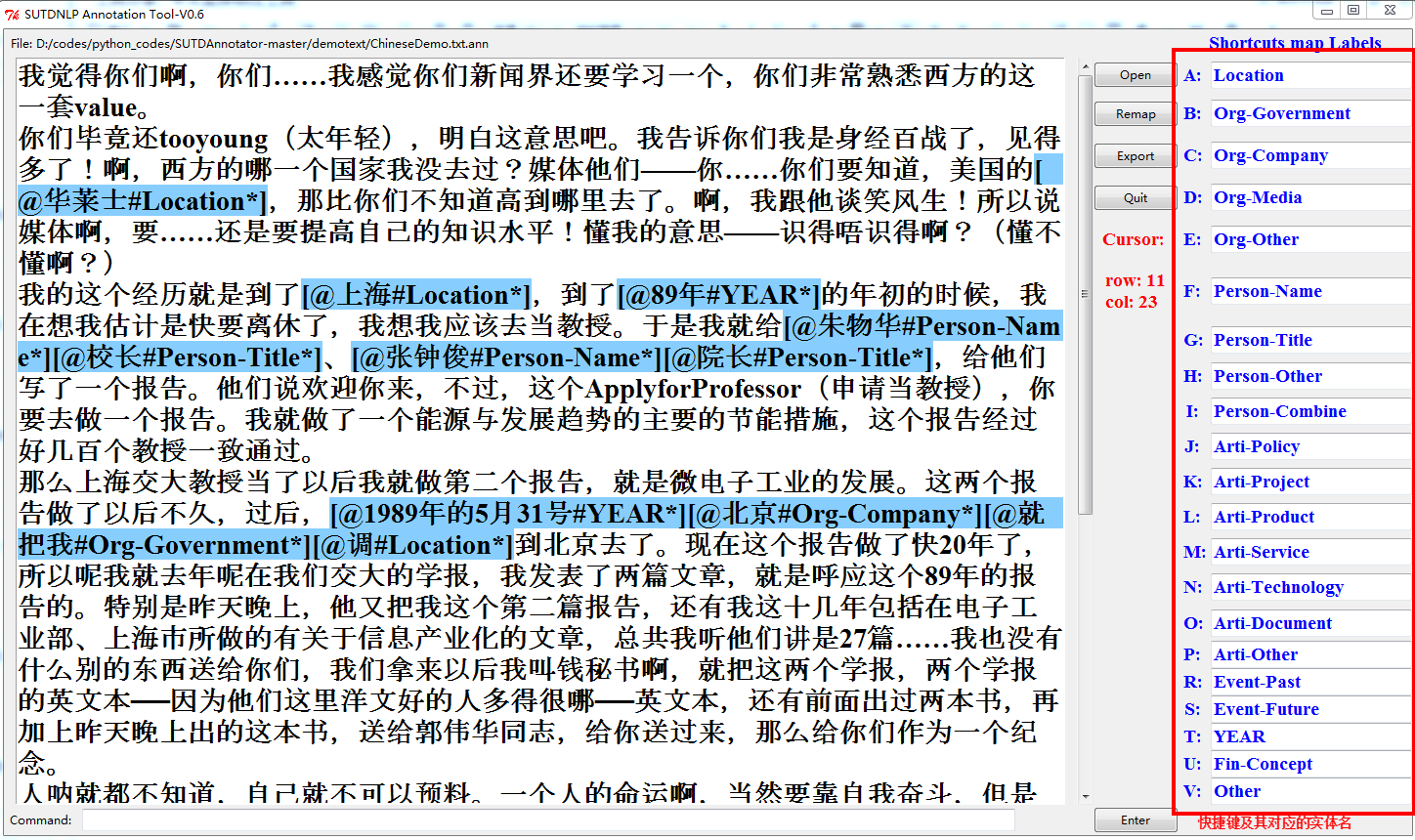
修改添加上自己所需的实体名:在对应的快捷键的右边输入实体名,按下remap按钮即可重新分配快捷键对应的实体名
导出结果:export


其他更详细的操作参照github中的描述
将标注好的ann文件转成常用的训练样本的格式,以下有python3实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import
re
# txt2ner_train_data turn label str into ner trainable data
# s :labeled str eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def
str2ner_train_data(s,save_path):
ner_data
=
[]
result_1
=
re.finditer(r
'\[\@'
, s)
result_2
=
re.finditer(r
'\*\]'
, s)
begin
=
[]
end
=
[]
for
each
in
result_1:
begin.append(each.start())
for
each
in
result_2:
end.append(each.end())
assert
len
(begin)
=
=
len
(end)
i
=
0
j
=
0
while
i <
len
(s):
if
i
not
in
begin:
ner_data.append([s[i],
0
])
i
=
i
+
1
else
:
ann
=
s[i
+
2
:end[j]
-
2
]
entity, ner
=
ann.rsplit(
'#'
)
if
(
len
(entity)
=
=
1
):
ner_data.append([entity,
'S-'
+
ner])
else
:
if
(
len
(entity)
=
=
2
):
ner_data.append([entity[
0
],
'B-'
+
ner])
ner_data.append([entity[
1
],
'E-'
+
ner])
else
:
ner_data.append([entity[
0
],
'B-'
+
ner])
for
n
in
range
(
1
,
len
(entity)
-
1
):
ner_data.append([entity[n],
'I-'
+
ner])
ner_data.append([entity[
-
1
],
'E-'
+
ner])
i
=
end[j]
j
=
j
+
1
f
=
open
(save_path,
'w'
, encoding
=
'utf-8'
)
for
each
in
ner_data:
f.write(each[
0
]
+
' '
+
str
(each[
1
]))
f.write(
'\n'
)
f.close()
# txt2ner_train_data turn label str into ner trainable data
# file_path :labeled multi lines' txt eg.'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
# save_path: ner_trainable_txt name
def
txt2ner_train_data(file_path,save_path):
fr
=
open
(file_path,
'r'
,encoding
=
'utf-8'
)
lines
=
fr.readlines()
s
=
''
for
line
in
lines:
line
=
line.replace(
'\n'
,'')
line
=
line.replace(
' '
,'')
s
=
s
+
line
fr.close()
str2ner_train_data(s, save_path)
if
(__name__
=
=
'__main__'
):
s
=
'我来到[@1999年#YEAR*]的[@上海#LOC*]的[@东华大学#SCHOOL*]'
save_path
=
's.txt'
str2ner_train_data(s, save_path)
file_path
=
'D:\\codes\\python_codes\\SUTDAnnotator-master\\demotext\\ChineseDemo.txt.ann'
txt2ner_train_data(file_path,
's1.txt'
)
|
