目标检测系列文章
yolo v1原理:https://blog.csdn.net/cjnewstar111/article/details/94035842
yolo v2原理:https://blog.csdn.net/cjnewstar111/article/details/94037110
yolo v3原理:https://blog.csdn.net/cjnewstar111/article/details/94037828
SSD原理:https://blog.csdn.net/cjnewstar111/article/details/94038536
FoveaBox:https://blog.csdn.net/cjnewstar111/article/details/94203397
FCOS:https://blog.csdn.net/cjnewstar111/article/details/94021688
FSAF: https://blog.csdn.net/cjnewstar111/article/details/94019687
基本原理:
相对于yolo v2,yolo v3做了如下改进:
更换了backbone网络,使用darknet53,没有pool层,全部使用卷积,降采样5次
使用类似于FPN的技术,融合多层特征预测
对分类和置信度使用二分类交叉熵(v1和v2全部使用MSE)
网络结构:
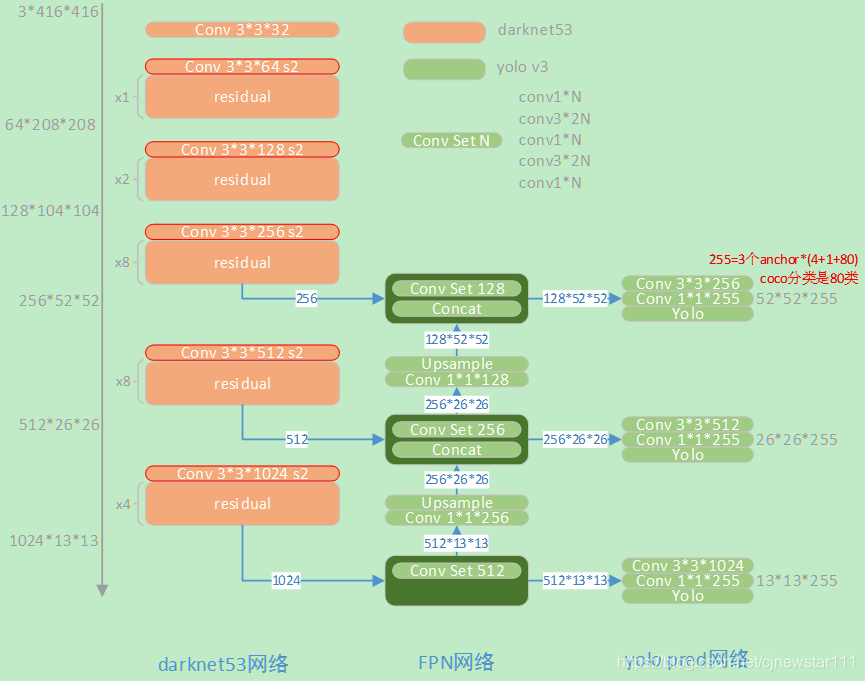
实现细节:
正负样本的确定:
对于正样本,以GT来找。某一个GT对应的cell里面,最大IOU的那个anchor作为正样本训练。然后对于负样本,需要计算其与anchor的最大IOU,如果最大IOU大于阈值(例如0.5),那么就不会把它当做负样本。这可以载一定程度上缓解正负样本比例失调的问题。
anchor值:
v2当中的anchors值使用相对于特征图的cell的倍数表示,v3当中使用绝对像素表示。
数据增强:
hsv抖动,放射变换以及flip(左右镜像)来做数据增强
参考资料:
yolo系列之yolo v3【深度解析】
来自 <https://blog.csdn.net/leviopku/article/details/82660381>
YOLO v3网络结构分析
来自 <https://blog.csdn.net/qq_37541097/article/details/81214953>
YOLOv3 深入理解