原理解析与基础知识
2. 微观上:
2.9 学习来自多个节点的权重:
先前,我们通过调整节点线性函数的斜率参数,来调整简单的线性分类器。我们使用误差值,也就是节点生成了答案与所知正确答案之间的差值,引导我们进行调整。

一种思想就是在所有造成误差的节点中平分误差,如下图所示。

另一种思想是不等分误差。与前一种思想相反,我们为较大链接权重的连接分配更多的误差。为什么这样做呢?这是因为这些链接对造成误差的贡献较大。下图详细阐释了这种思想。

你可以观察到,我们在两件事情上使用了权重。第一件事情,在神经网络中,我们使用权重,将信号从输入向前传播到输出层。此前,我们就是在大量地做这个工作。第二件事情,我们使用权重,将误差从输出向后传播到网络中。我们称这种方法为反向传播,你应该不会对此感到惊讶吧。
2.10 多个输出节点反向传播误差:
下图显示了具有2个输入节点和2个输出节点的简单网络。

两个输出节点都有误差——事实上,在未受过训练的神经网络中,这是极有可能发生的情况。你会发现,在网络中,我们需要使用这两个误差值来告知如何调整内部链接权重。我们可以使用与先前同样的方法,也就是跨越造成误差的多条链接,按照权重比例,分割输出节点的误差。
让我们写出这些分割值,这样我们就不会有任何疑问了。我们使用误差e1的信息,来调整权重w1,1和w2,1。通过这种分割方式,我们使用e1的一部分来更新w1,1:
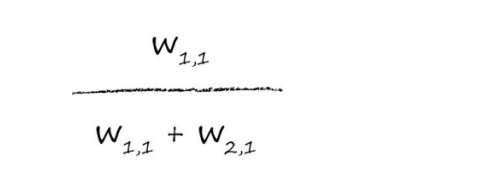
类似地,用来调整w2,1的e1部分为:
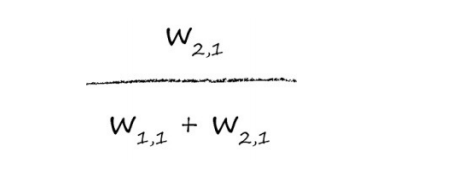
这些分数看起来可能令人有点费解,让我们详细阐释这些分数。在所有这些符号背后,思想非常简单,也就是误差e1要分割更大的值给较大的权重,分割较小的值给较小的权重。
接下来我们要问的问题是,当神经wang络多于2层时,会发⽣什么事情呢?在离最终输出层相对较远的层中,我们如何更新链接权重呢?
2.11 反向传播误差到更多层中:
下图显示了具有3层的简单神经网络,一个输入层、一个隐藏层和一个最终输出层。

这种方法,我们可以明白,对于额外的新层所需要做的事情。简单说来,我们采用与隐藏层节点相关联的这些误差ehidden,再次将这些误差按照输入层和隐藏层之间的链接权重wih进行分割。下图就显示了此逻辑。

如果神经网络具有多个层,那么我们就从最终输出层往回工作,对每一层重复应用相同的思路。误差信息流具有直观意义。同样,你明白为什么我们称之为误差的反向传播了。
沿着各个链接可以分割输出误差,就像我们先前所做的那样。这意味着,对于中间层节点的每个链接,我们得到了某种误差值。我们可以重组这两个链接的误差,形成这个节点的误差。

确认一下。我们需要隐藏层节点的误差,这样我们就可以使用这个误差更新前一层中的权重。我们称这个误差为ehidden。
我们可以使用先前所看到的误差反向传播,为链接重组分割的误差。

在具有实际数字的3层网络中,误差如何向后传播

让我们演示一下反向传播的误差。你可以观察到,第二个输出层节点的误差0.5,在具有权重1.0和4.0的两个链接之间,根据实例被分割成了0.1和0.4。你也可以观察到,在隐藏层的第二个节点处的重组误差等于连接的分割误差之和,也就是0.48与0.4的和,等于0.88。如下图所示,我们进一步向后工作,在前一层中应用相同的思路。

2.12 使用矩阵乘法进行反向传播误差:

因此,我们得到所希望的矩阵,使用矩阵的乘法来向后传播误差:

我们已经做了海量的工作了!
2.13 我们实际上如何更新权重:
请观察下面这个“面目可憎”的表达式,这是一个简单的3层、每层3个节点的神经网络,其中输入层节点的输出是输入值和链接权重的函数。在节点i处的输入是xi,连接输入层节点i到隐藏层节点j的链接权重为wi,j,类似地,隐藏层节点j的输出是xj,连接隐藏层节点j和输出层节点k的链接权重是wj ,k。那个看似有趣的符号Σba意味着对在a和b值之间的所有后续表达式求和。

想象一下,有个非常复杂、有波峰波谷的地形以及连绵的群山峻岭。你拿着一个手电筒,看不见大的范围,只能通过小范围的梯度,判断出下山的路。

在数学上,这种方法称为梯度下降(gradient descent),你可以明白这是为什么吧。
这种酷炫的梯度下降法与神经网络之间有什么联系呢?好吧,如果我们将复杂困难的函数当作网络误差,那么下面找到最小值就意味着最小化误差。这样我们就可以改进网络输出。这就是我们希望做到的!
下图显示了一个简单的函数y =(x-1)2 + 1。如果在这个函数中,y表示误差,我们希望找到x,可以最小化y。现在,我们假装这不是一个简单的函数,而是一个复杂困难的函数。

我们假设在某个地方开始,如下图所示。

下面我们将详细说明,当函数梯度变得较小时调节步长的这种思想,函数梯度是在何种程度上接近最小值的良好指标。

同样,下面我们将使用稍微复杂的、依赖2个参数的函数,详细说明梯度下降法。这可以使用三维空间来表示,同时使用高来表示函数的值。

为了避免终止于错误的山谷或错误的函数最小值,我们从山上的不同点开始,多次训练神经网络,确保并不总是终止于错误的山谷。
下图详细说明了使用梯度下降方法的三种不同尝试,其中有一次,这种方法终止于错误的山谷中。

此图与我们先前看到的图一样,主要是强调我们所做的事情没有什么不同。

下图显示了两个链接权重,这次,误差函数是三维曲面,这个曲面随着两个链接权重的变化而变化。

让我们使用数学的方式,写下想要取得的目标。

这个表达式表示了当权重wj,k改变时,误差E是如何改变的。
下图突出显示了我们所感兴趣的这个区域。我们将重回输入层和隐藏层之间的链接权重。

首先,让我们展开误差函数,这是对目标值和实际值之差的平方进行求和,这是针对所有n个输出节点的和。
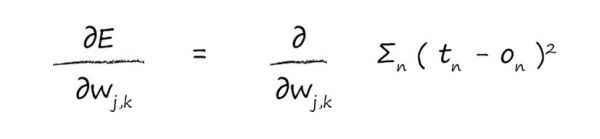
意味着误差函数根本就不需要对所有输出节点求和。原因是节点的输出只取决于所连接的链接,就是取决于链接权重。

我们将使用链式法则,将这个微积分任务分解成更多易于管理的小块。
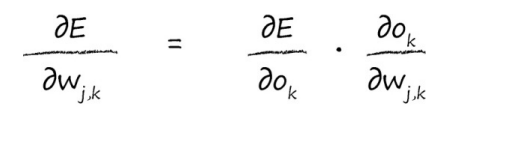
现在,我们可以反过来对相对简单的部分各个击破。我们对平方函数进行简单的微分,就很容易击破了第一个简单的项。这使我们得到了以下的式子:
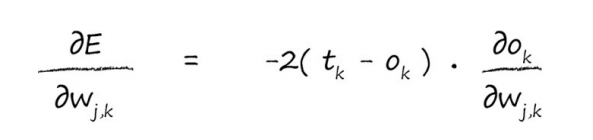
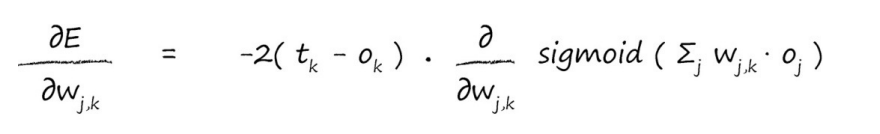
我们如何微分S函数呢?

因此,让我们应用这个酷炫的结果,得到以下的表达式。

这就是我们一直在努力要得到的最后答案,这个表达式描述了误差函数的斜率,这样我们就可以调整权重w j,k了。

因此,我们一直在努力达成的最终答案的第二部分如下所示,这是我们所得到误差函数斜率,用于输入层和隐藏层之间权重调整。
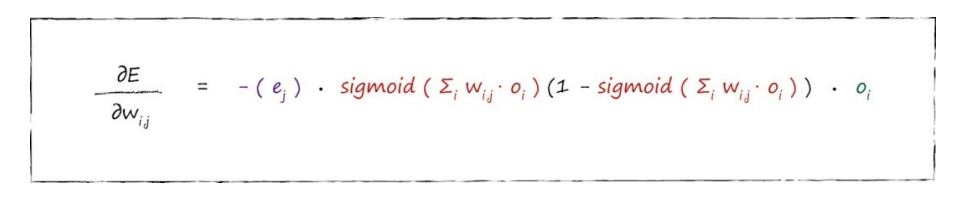
符号α是一个因子,这个因子可以调节这些变化的强度,确保不会超调
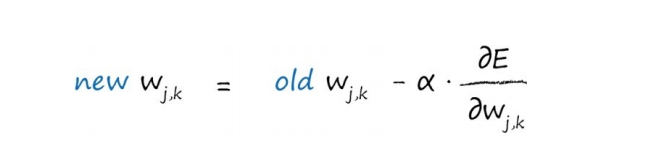
为了有助于理解,我们将按照以前那样写出权重变化矩阵的每个元素。

因此,权重更新矩阵有如下的矩阵形式,这种形式可以让我们通过计算机编程语言高效地实现矩阵运算。
