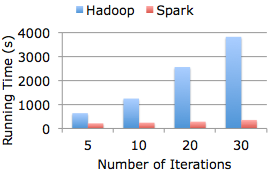
Apache Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
2.4.4 版本包含稳定性修复的维护版本,内容如下:
- 修复十进制 toScalaBigInt/toJavaBigInteger 表示不适合长的十进制的问题
- 修复 PushProjectionThroughUnion 可空性问题
- 修复 From_Avro 在本地模式下不修改其他行中的变量
- Spark 2.4.3 当 HiveUDAF 遇到 0 行时意外抛出 NPE。与其他版本一样,修复后返回 NULL
- 修复 PySparkSocket 服务器与 JVM 连接线程的同步
- KafkaOffsetRangeCalculator.getRange 可能会减少偏移量
- 缓存一个不确定的 RDD 会导致在重新运行阶段时出现不正确的结果
- Spark 2.2 引入了 LinearSVCModel.setWeightCol 方法,这种方法是不正确的。它在 2.4.4 中被弃用,在 3.0.0 中将被删除
详情见说明: