关键词
运用机器学习方法进行标签传播
之前提出的算法
1.用于时空密集滤波的时间双边网络。
2.只通过静态图像训练一个深度网络来细化前一帧掩码,并且在测试中使用测试视频的第一帧来记忆目标
的外观(即在线微调),从而提升了性能。
3.通过大量数据增强策略来实现更高的分割精度。
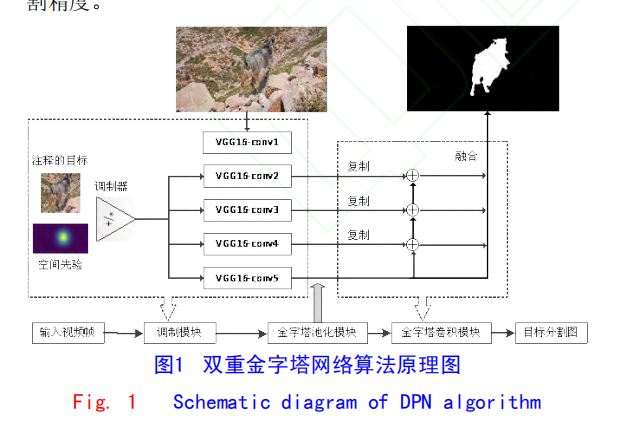
金字塔卷积方法最大的好处是不用微调
下图是基本思路
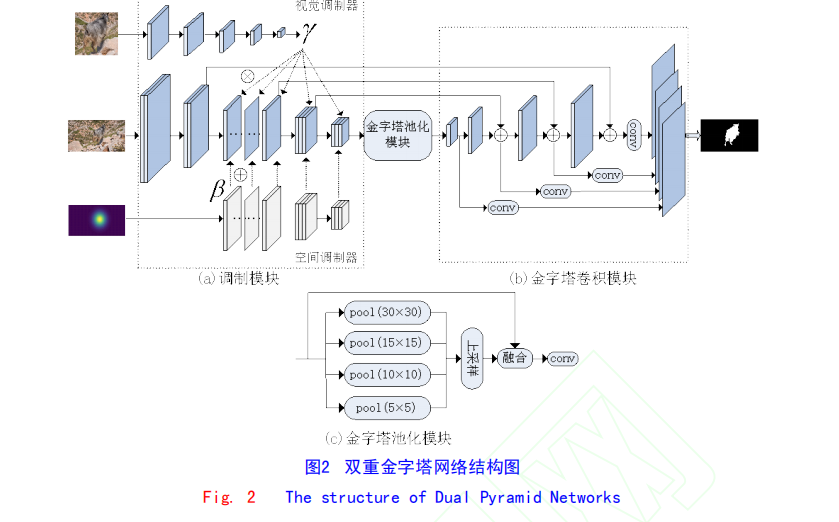
分割网络是基于 VGG16
[16] 的全卷积网络,且在除了
VGG16 的前四层外的所有卷积层中添加调制操作,具体的调
制过程和参数如下介绍。
视觉调制器用于使分割网络适应给定目标的外观,其从
给定注释帧中提取语义信息,例如,类别、颜色、形状和纹
理,并且生成对应通道的尺度参数以调整特征图中不同通道
的权重,从而在分割网络中重新定位给定目标的位置[14] 。本
文使用 VGG16 神经网络作为视觉调制器模型将第一帧图片
围绕目标裁剪为 224×224 像素大小作为输入,并且修改最后
一层用于分类的层,以匹配分割网络调制层中的参数数目。
所有视觉调制参数都与特征图相乘,具体表达式如式(1)所
示。
空间调制器生成像素级偏移参数,目的是为了在目标对
象的位置上提供粗略的先验信息。本文先在前一帧的预测掩码上生成二维热图,从而获
得目标位置的粗略估计,再将其作为空间调制器的输入。为
了匹配分割网络中的不同特征图的分辨率,空间调制器将二
维热图下采样为不同的尺度,进而获得对应于每个卷积层的
空间位移参数,空间调制参数与相应层的特征图相加
现在看来这篇文章的方法是基于vgg16的方法,每次有两个矩阵,分别代表了视觉参数,和偏移参数
然后根据式子

确定之后的Fcn,之后利用全卷积神经网络
关于本片论文的定性结果
2.5 定性结果
在图 3 中,本文展示了所提出的方法在部分遮挡(如图
3(a))、杂乱背景(如图 3(b))、运动模糊(如图 3(c))以及
在 kite-surf 序列(如图 3(d))上测试的效果图。部分遮挡的
情况下只需要分割未被遮挡目标部分,杂乱背景的情况下需
要将目标与背景中相似目标分离,运动模糊的情况下需要对
模糊的目标部位进行更加细致的分割。本文算法在以上情况
下都能准确地分割出给定目标,尤其在 kite-surf 序列中,可
以较为准确地分割出图中的小目标。从图 3(d)中可以看到小
目标的分割图与真实标签仍存在一些差距,如何更加充分地
利用局部信息(比如感兴趣区域中的一些关键特征点)和全
局信息(比如感兴趣区域中的类别、颜色和纹理等语义信息)
将是接下来的研究方向之一。