1 指定字段区间(如时间段、ID 端、区域)
2 按指定维度取模
根据 hash(key)的结果,模连接数的余数决定存储到哪个节点,也就是hash(key%ssions .size(),这个算法简单快速,表现良好。
缺点:
在 redis节点增加或者删除的时候,原有的缓存数据将大规模失效,命中率大受影响,如果节点数多,缓存数据多,重建缓存的代价太高,容易导致分片数据不均衡。使用该分片策略时要提前做好容量规划,用主备或者主从的方式来解决故障恢复。
3 一致性哈希算法
查找节点过程如下:首先求出 Redis服务器(节点)的哈希值,并将其配置到0的32次方的圆( continuum)上。然后用同样的方法求出存储数据的键的哈希值并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2的32次方仍然找不到服务器,就会保存到第一台Redis服务器上。
扩展性好,分片均衡,可维护性差。通过双环部署的方式可以最大限度的提高可用性。
consistent hashing是一种hash算法,简单的说,在移除/添加一个 cache时,它能够尽可能小的改变已存在kev映射关系,尽可能的满足单调性的要求。
Jedis支持一致性Hash算法。
把数据通过一定的hash算法处理后映射到环上

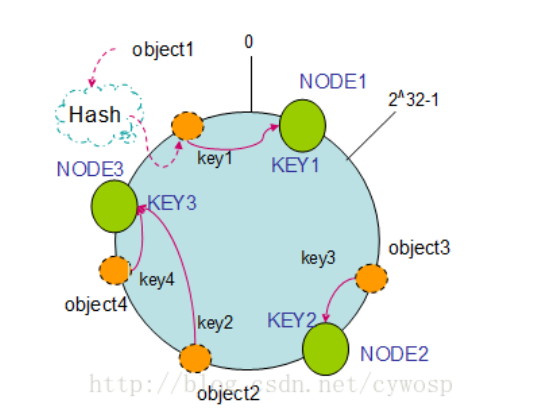
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
机器的删除与添加


一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
---------------------
原文:https://blog.csdn.net/cywosp/article/details/23397179