1.Sequence Generation
1.1.引入
在循环神经网络(RNN)入门详细介绍一文中,我们简单介绍了Seq2Seq,我们在这里展开一下
一个句子是由 characters(字) 或 words(词) 组成的,中文的词可能是由数个字构成的。
如果要用训练RNN写句子的话,以 character 或 word 为单位都可以
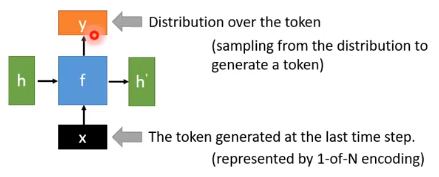
以上图为例,RNN的输入的为前一时间点产生的token(character 或 word)

假设机器上一时间点产生的 character 是 “我”,我们输出的向量 y 是在 character 上的分布,它有0.7的几率写出 “我是”,有0.3的几率写出 “我很” 。
1.2.例子:写诗
在产生句子第一个 character 的时候,由于前面没有东西,我们需要给机器一个特殊的character—— <BOS>
BOS:Begin of Sentence
输出的第一个character $y^{1}$ 可以下面的条件概率表示
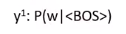
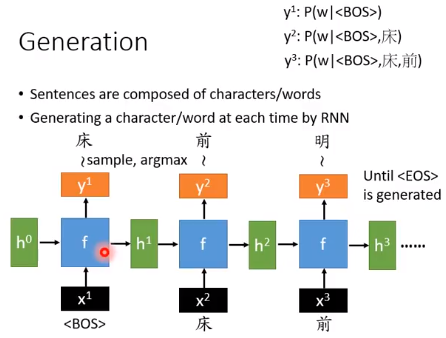
我们再输出概率最大的那个 character,然后把$y^{1}$作为输入,……,不断重复这个行为,直到我们输出 <EOS>
EOS:End of Sentence
我们训练 RNN 的数据集也类似上面这个样子。如下图所示,我们的输入是古诗的每一个字,输出是输入的下一个字,通过最小化 cross-entropy 来得到我们的模型

1.3.例子:画图
图片由 pixel 组成,我们可以把一张图片的像素点想成词汇,让RNN产生像素点,道理也是一样的。

但是图片每一行最右边的像素点 $a_{i,j}$ 和下一行最左边 $a_{i+1, j-2}$ 的像素距离很远,他们可能没有关系,$a_{i+1, j-2}$ 反而可能跟正上方的像素 $a_{i, j-2}$ 关系大些。
比如下图中 灰色 的像素点和 黄色 的像素点可能关系不大,而跟 蓝色 的像素点更有关系。
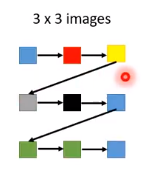 所以我们生成图片像素点的时候,灰色 的像素点是由 蓝色 像素点生成的,而不是 由 黄色像素点生成。
所以我们生成图片像素点的时候,灰色 的像素点是由 蓝色 像素点生成的,而不是 由 黄色像素点生成。

2.Conditional Generation
但我们不想随机生成句子,我们更期望它能根据我们的场景生成相应的句子。比如给张图片,输出对图片的描述;聊天机器人中输入一句话,输出这句话的response。

2.1.Image Caption Generation
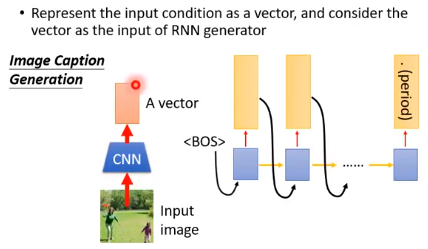
比如我们要训练一个模型,用来生成图片的文字说明。
我们可以让图片通过一个CNN,输出一个vector,再把这个vector丢到RNN中。
- 这个vector可以只在第一个时间点输入,让RNN把这个vector存到memory中,后面的时间点补零。
- 也可以在每个时间点都输入这个vector,因为RNN到后面可能忘记了我们输入的vector。
2.2.Machine translation / Chat-bot
如果要做一个翻译机或者一个聊天机器人,我们的输入是一个句子,输出是翻译结果或者response。
这个模型可以分为两个部分,Encoder 和 Decoder
把句子输入 Encoder 然后在最后一个时间点把 output 取出来
可以取output,也可以取 $h_{t}$,还有$c_{t}$
再把 Encoder 输出的vector 作为 Decoder 每一个时间点的输入。Encoder 和 Decoder 是一起训练的。

上面这种情况,我们的输入是Sequence,我们的输出也是Sequence,所以被称为 Sequence to Sequence Model
3.Dynamic Conditional Generation
这种模型又叫做 Attention Based Model。前面介绍的 Encoder- Decoder 这种架构,它可能没有能力把一个很长的 input 压缩到一个 vector 中,这样 vector 就不能表示句子里的所有信息,导致模型表现不如人意。 前面 Decoder 每个时间点输入都是同样的 vector 。在 Dynamic Conditional Generation 中,我们希望 Decoder 在每个时间点获得的信息是不一样的。
我们继续上面的例子,来训练一个翻译模型。 这里多了一个向量$z^{0}$,$z^{0}$也是模型需要训练的参数向量(称为key)
我们先把每个隐藏层的输出放到一个 Database 中,用$z^{0}$去搜寻 Database 中的内容。它会和隐藏层的每个输出$h^{i}$做匹配,得到一个匹配的程度 $\alpha ^{i}_{0}$
这就是Attention

匹配的方法 match 可以自己设计,比如:
- match 可以是 $z$ 和 $h$ 的余弦相似度(cosine similarity)
- match 也可以是个网络,输入是 $z$ 和 $h$,输出是一个数值
- match 还可以像这样设计:$\alpha =h^{T}Wz$
第二种网络的参数和第三种方法中的参数$W$是机器自己学习的
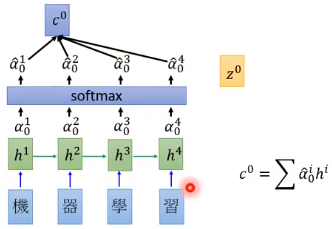
经过 match 后得到的$\alpha ^{i}_{0}$后面可以再接一个 softmax (也可以不用),得到$\hat{\alpha}^{i}_{0}$,再让$h$和$\hat{\alpha}$对应相乘再相加得到$c^{0}$
再把$c^{0}$作为 Decoer 的输入,根据 $z^{0}$ 和 $c^{0}$ ,Decoder 会得到一个 $z^{1}$ 并输出一个 word。
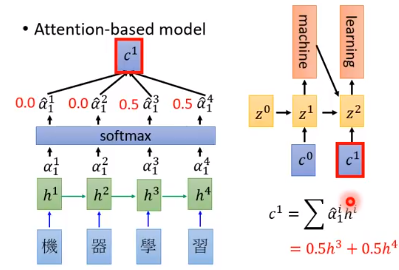
我们得到 $z^{1}$ 后,我们再计算一次Attention。一直重复这个动作,直到产生 <EOS>
Attention让我们不关心整个句子,而是关注在某个地方
4.Tips
4.1.Attention过于集中
$^{\alpha ^{i}_{t}}$ ,下标代表时间,上标代表第几个 component 的 Attention weight

比如观看影片,输出对影片的内容的描述文字。
如果我们的 Attention 样子像上图中的 条形图 所示,它都集中 第二个 画面里面。在这个画面中,第二个时间点和第四个时间点的 Attention 都很高。
那么我们的输出可能是下面这样奇奇怪怪的句子:
A woman and woman is doing a woman
我们希望我们的 Attention 是平均的,不应该特别只看某一个 frame,而是影片的每一个 frame 都要平均地看到。
我们可以对我们的 Attention 下一个 Regularization term,在机器学习中我们也常用 l1 和 l2 正则。

上面的式子中,$\sum _t\alpha ^{i}_{t}$把同一帧中的所有Attention累加,希望跟一个常数$\tau $越接近越好。
这样我们得到的 Attention weight 就会平均散布在不同的帧上,而不会特别集中在某一帧上
4.2.training 和 testing 不一致
4.2.1引入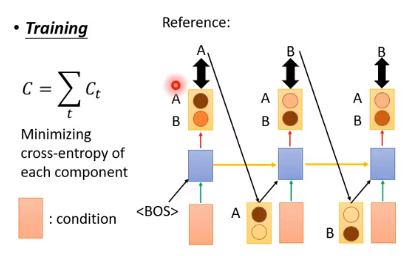
如上图所示,我们训练的时候,我们期望输出的是 A、B、B,通过最小化交叉熵损失得到我们的模型
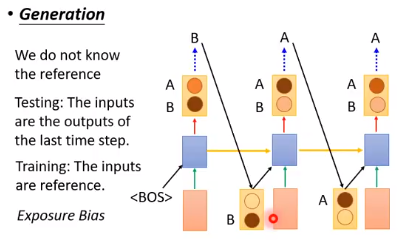
在测试的时候,假如我们第一个时间点输出是B,它会作为第二个时间点输入的一部分。但测试的时候没有标,我们不知道第二个时间点输入是错误的。
即在测试的时候,输入的一部分是机器自己生成的,有可能有错的东西。这种情况称为 exposure bias。
exposure bias指模型在训练的时候,有些状况它是没有去探测过的
我们来看一下 training 和 testing 的情况
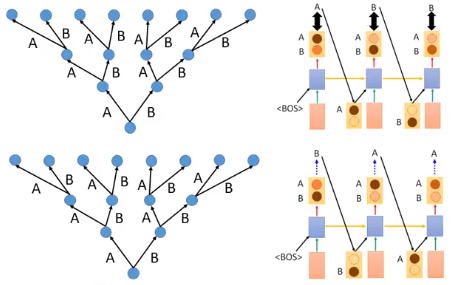
训练的时候,我们的模型只有看到过3条支路的比较,其他的状况在 training 的时候是没有模型是没有看到过的

测试的时候,我们没有了上面的限制。如果我们测试的时候,第一步就犯错了,而在 training 的时候我们的模型没有看到过其他支路的状况,导致一步错,步步错。
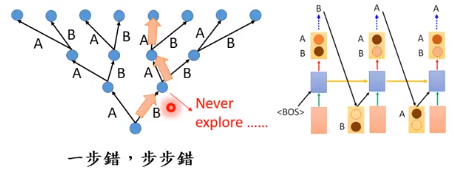
4.2.2 Scheduled Sampling
我们可以用 Scheduled Sampling 解决这种现象
Scheduled Sampling的意思是说给机器看自己生成的东西,会很难训练,给机器看正确的答案,training和testing会不一致。那就折中考虑。
就像用一个骰子来决定,如果是正面就看机器自己生成的东西,反面就看正确的答案。
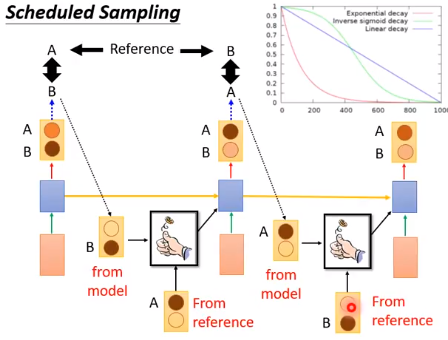
这个骰子的几率是动态决定的,在一开始的时候答案出现的几率比较高,随着training的进行,机器自己生成的东西几率比较高。因为testing的时候,机器自己生成的东西几率是100,答案出现的几率是0。
4.2.3Beam Search
我们还可以使用Beam Search。我们机器在 output 的时候,都是输出一个概率,然后选择概率高的。
那有没有可能在第一步选了 B 后面的几率更大?比 0.6 * 0.6 * 0.6 大?如下图所示
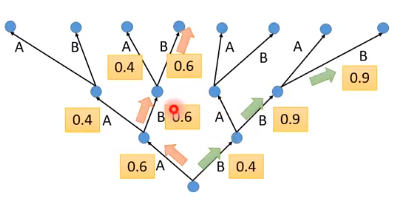
也许牺牲第一个时间点之后我们可以选到更好的结果。我们没有办法穷举所有可能,Beam Search就是要克服这个问题
每次在做 sequence 生成的时候,我们都会保留前N个分数最高的可能。存的数目就叫做Beam Size。下图中Beam Szie=2
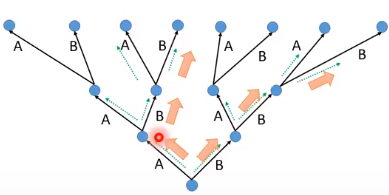
testing才用Beam Search,training用不上
另一个Beam Search例子
