机器通过损失函数进行学习。这是一种评估特定算法对给定的数据 建模程度的方法。如果预测值与真实值之前偏离较远,那么损失函数便会得到一个比较大的值。在一些优化函数的辅助下,损失函数逐渐学会减少预测值与真实值之间的这种误差。
机器学习中的所有算法都依赖于最小化或最大化某一个函数,我们称之为“目标函数”。最小化的这组函数被称为“损失函数”。损失函数是衡量预测模型预测结果表现的指标。寻找函数最小值最常用的方法是“梯度下降”。把损失函数想象成起伏的山脉,梯度下降就好比从山顶滑下,寻找山脉的最低点(目的)。
在实际应用中,并没有一个通用的,对所有的机器学习算法都表现的很不错的损失函数(或者说没有一个损失函数可以适用于所有类型的数据)。针对特定问题选择某种损失函数需要考虑到到许多因素,包括是否有离群点,机器学习算法的选择,运行梯度下降的时间效率,是否易于找到函数的导数,以及预测结果的置信度等。
从学习任务的类型出发,可以从广义上将损失函数分为两大类——回归损失(Classification Loss)和分类损失(Regression Loss)。在分类任务中,我们要从类别值有限的数据集中预测输出,比如给定一个手写数字图像的大数据集,将其分为 0~9 中的一个。而回归问题处理的则是连续值的预测问题,例如给定房屋面积、房间数量,去预测房屋价格。


回归损失
1. 均方误差(Mean Square Error), 二次损失(Quadratic Loss), L2 损失(L2 Loss)
均方误差(MSE)是最常用的回归损失函数。其数学公式如:
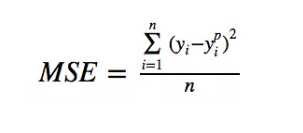
均方误差(MSE)度量的是预测值和实际观测值之间差的平方和求平局。它只考虑误差的平均大小,不考虑其方向。但由于经过平方,与真实值偏离较多的预测值会比偏离较少的预测值受到更为严重的惩罚。再加上 MSE 的数学特性很好,这使得计算梯度变得更容易。
下面是一个MSE函数的图,其中真实目标值为 100,预测值在 -10,000 至 10,000之间。预测值(X轴)= 100 时,MSE 损失(Y轴)达到其最小值。损失范围为 0 至 ∞。
