数据的完整性
1.什么是数据的完整性
保证用户输入的数据保存到数据库中是正确的。
2.如何添加数据完整性
在创建表时给表中添加约束
3.完整性分类
实体完整性、域完整性、引用完整性
实体完整性
1.什么是实体完整性
表中的一行(一条记录)代表一个实体(entity)
2.实体完整性的作用
标识每一行数据不重复。行级约束
3.约束类型
主键约束(primary key)
唯一约束(unique)
自动增长列(auto_increment)
主键约束
特点:每个表中要有一个主键。数据唯一,且不能为null
添加方式
CREATE TABLE 表名(字段名1 数据类型 primary key,字段2 数据类型);
CREATE TABLE 表名(字段1 数据类型, 字段2 数据类型,primary key(要设置主键的字段));
CREATE TABLE 表名(字段1 数据类型, 字段2 数据类型,primary key(主键1,主键2));
联合主键
两个字段数据同时相同时,才违反联合主键约束。
1.先创建表
2.再去修改表,添加主键
ALTER TABLE student ADD CONSTRAINT PRIMARY KEY (id);
唯一约束
特点:指定列的数据不能重复、可以为空值
格式
CREATE TABLE 表名(字段名1 数据类型 字段2 数据类型 UNIQUE);
自动增长列
特点:指定列的数据自动增长,即使数据删除,还是从删除的序号继续往下
格式
CREATE TABLE 表名(字段名1 数据类型 PRIMARY KEY AUTO_INCREMENT ,字段2 数据类型 UNIQUE);
域完整性
使用
限制此单元格的数据正确,不对照此列的其它单元格比较
域代表当前单元格
域完整性约束
数据类型:数值类型、日期类型、字符串类型
非空约束(not null)
CREATE TABLE 表名(字段名1 数据类型 PRIMARY KEY AUTO_INCREMENT ,字段2 数据类型 UNIQUE not null);
默认值约束(default)
CREATE TABLE 表名(字段名1 数据类型 PRIMARY KEY AUTO_INCREMENT ,字段2 数据类型 UNIQUE not null default '男');
插入的时候,values当中的值直接给default
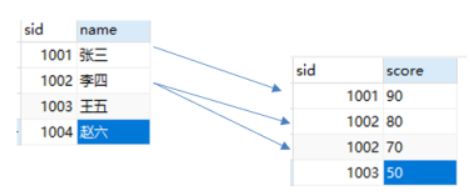
参照完整性
1.什么是参照完整性
是指表与表之间的一种对应关系
通常情况下可以通过设置两表之间的主键、外键关系,或者编写两表的触发器来实现。
有对应参照完整性的两张表格,在对他们进行数据插入、更新、删除的过程中,系统都会将被修改表格与另一张对应表格进行对照,从而阻止一些不正确的数据的操作。
2.注意
数据库的主键和外键类型一定要一致;
两个表必须得要是InnoDB类型
设置参照完整性后 ,外键当中的内容,必须得是主键当中的内容
一个表设置当中的字段设置为主键,设置主键的为主表
CREATE TABLE student(sid int PRIMARY key,name varchar(50) not null,sex varchar(10) default '男');
创建表时,设置外键,设置外键的为子表
CREATE TABLE score( sid INT, score DOUBLE, CONSTRAINT fk_stu_score_sid FOREIGN KEY(sid) REFERENCES student(sid) );
表之间关系
一对一: 一夫一妻
一对多关系: 一个人可以拥有多辆汽车,要求查询某个人拥有的所有车辆。
-- Person表 CREATE TABLE person( id int primary key NOT NULL, name VARCHAR(50), age int, sex CHAR(1) );
-- Car表 CREATE TABLE car( cid int primary key, cname varchar(50), color varchar(25), pid int, CONSTRAINT fk_Person FOREIGN KEY(pid) REFERENCES person(id) );
多对多关系:
学生选课,一个学生可以选修多门课程,每门课程可供多个学生选择。
一个学生可以有多个老师,而一个老师也可以有多个学生
1.创建老师表
CREATE TABLE teacher( tid INT PRIMARY KEY auto_increment, name VARCHAR(50), age int, gender char(1) DEFAULT '男' );
2.创建学生表
CREATE TABLE student( sid int PRIMARY KEY auto_increment, name VARCHAR(50) NOT NULL, age int, gender CHAR(1) DEFAULT '男' );
3.创建学生与老师关系表
CREATE TABLE tea_stu_rel( tid INT, sid INT );
4.添加外键
ALTER TABLE tea_stu_rel ADD CONSTRAINT fk_tid FOREIGN KEY(tid) PEFERENCES teacher(tid); ALTER TABLE tea_stu_rel ADD CONSTRAINT fk_sid FOREIGN KEY(sid) PEFERENCES student(id);
为什么要拆分表?避免大量冗余数据的出现

多表查询
合并结果集
1.什么是合并结果集
合并结果集就是把两个select语句的查询结果合并到一起
2.合并结果集的两种方式
UNION 合并时去除重复记录
UNION ALL 合并时不去除重复记录
格式:
SELECT * FROM 表1 UNION SELECT * FROM 表2;
SELECT * FROM 表1 UNION ALL SELECT * FROM 表2;
示例
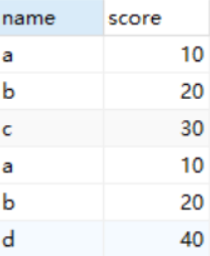
1.创建表
CREATE TABLE A(name varchar(10),score int); CREATE TABLE B(name varchar(10),score int); INSERT INTO A VALUES('a',10),('b',20),('c',30); INSERT INTO B VALUES('a',10),('b',20).('d',40);
2.UNIONSELECT * FROM A UNION SELECT * FROM B;

3.UNION ALLSELECT * FROM A UNION ALL SELECT * FROM B;
注意事项
被合并的两个结果:列数、列类型必须相同。
连接查询
1.什么是连接查询
也可以叫跨表查询,需要关联多个表进行查询
2.什么是笛卡尔集
假设集合A={a,b},集合B={0,1,2},
则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。
可以扩展到多个集合的情况
同时查询两个表,出现的就是笛卡尔集结果
查询时给表起别名
SELECT * FROM student stu,score sc;
3.多表联查,如何保证数据正确
在查询时要把主键和外键保持一致SELECT * FROM stu st,score sc WHERE st.id = sc.sid;
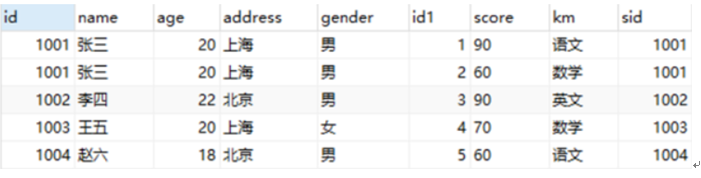
主表当中的数据参照子表当中的数据
原理
逐行判断,相等的留下,不相等的全不要
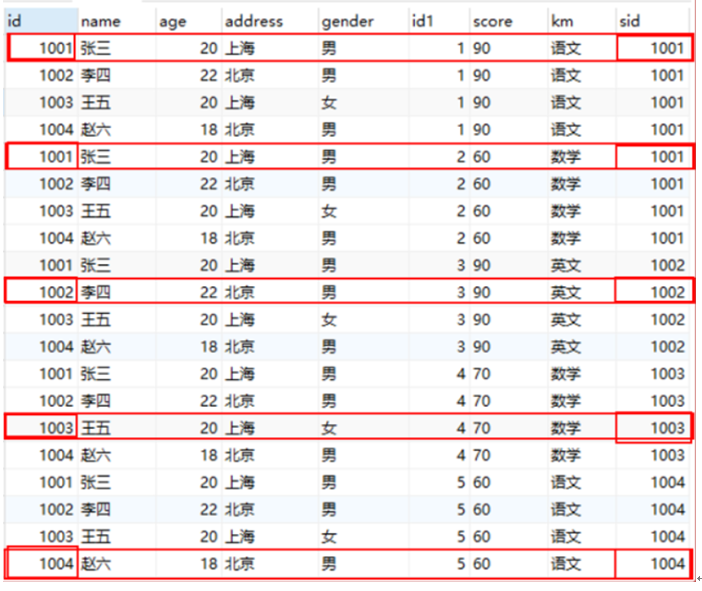
根据连接方式分类
内连接
一、等值连接
两个表同时出现的id号(值)才显示
SELECT * FROM stu st INNER JOIN score sc ON st.id = sc.sid;
与多表联查约束主外键是一样,只是写法改变了。
ON后面只写主外键
如果还有条件直接在后面写where
SELECT st.name,sc.score,sc.km FROM stu st INNER JOIN score sc ON st.id = sc.sid WHERE score>=70;
多表联查后面还有条件就直接写and
二、多表连接
建立学生,分数,科目表

使用99连接法
SELECT st.name,c.name,sc.score FROM stu st,score sc,course c WHERE st.id = sc.sid AND sc.cid = c.cid;
使用内联查询
SELECT st.name,c.name,sc.name FROM stu st INNER JOIN score sc ON st.id = sc.sid INNER JOIN course c ON sc.cid = c.cid;
三、非等值连接
示例表
查询所有员工的姓名,工资,所在部门的名称以及工资的等级
1.查询所有员工的姓名,工资
SELECT ename,salary FROM emp;
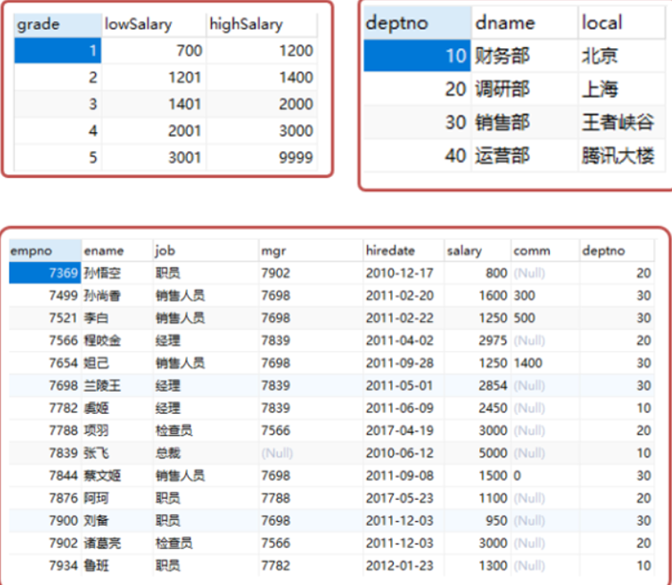
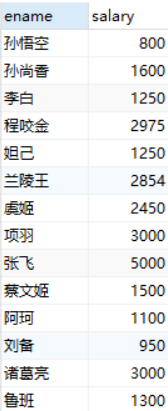
2.查询所有员工的姓名,工资和所有部门-- SELECT e.ename,e.salary,d.dname FROM emp e,dept d WHERE e.deptno = d.deptno; SELECT e.name,e.salaru,d.dname FROM emp e JOIN dept d ON e.deptno = d.deptno;
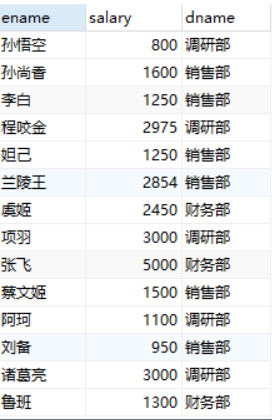
3.查询所有员工的姓名,工资和所在部门及工资等级
SELECT e.ename,e.salary,d.dname,g.grade FROM emp e JOIN dept d ON e.deptno = d.deptno JOIN salgrade g ON e.salary BETWEEN g.lowSalary AND g.highSalary;
四、外连接
1.左外连接(左连接)
两表满足条件相同的数据查出来,如果左边表当中有不相同的数据,也把左边表当中的数据查出来。
左边表当中的数据全部查出,右边表当中,只查出满足条件的内容
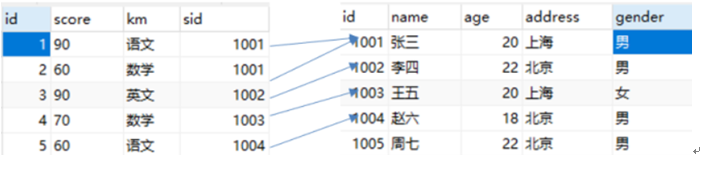
使用内连接时,周七不会查出来,没有成绩,缺考了。把所有考过试的学生分数查出来。
SELECT st.name,sc.score,sc.km FROM stu st,score sc WHERE st.id = sc.sid
SELECT st.name,sc.score,sc.km FROM stu st INNER JOIN score sc ON st.id = sc.sid;
使用左连接查询所有学生及学生的考试分数
SELECT st.name,sc.score,sc.km FROM stu st LEFT OUTER JOIN score sc ON st.id = sc.sid;
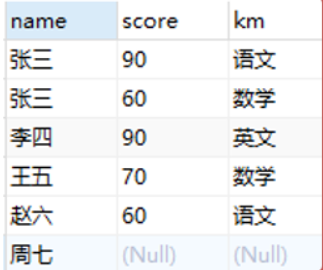
左连接会把左表当中的数据全部查出,右表当中只查出满足条件的数据
可以省略outer不写
查询时,两个表可以不需要建立主外键约束
2.右外连接(右连接)
右连接会把右当中的数据全部查出,左表当中只查出满足条件的数据
SELECT st.name,sc.score,sc.km FROM stu st RIGHT JOIN score sc ON st.id = sc.sid;
右边表当中的所有数据全部查出,左边表只查出满足条件的记录
站在表的角度去看,使用左连接就把左边表当中的内容全部查出,右边查出满足条件的。
使用右连接,就把右边表当中的数据全部查出。左边查出满足条件的。
五、自然连接
连接查询会产生无用笛卡尔集,我们通常使用主外键关系等式来去除它。
而自然连接无需你去给出主外键等式,它会自动找到这一等式
也就是说不用去写条件
要求
两张连接的表中列名称和类型完全一致的列作为条件
会去除相同的列
SELECT * FROM stu NATURAL JOIN score;
子查询
1.什么是子查询
一个select语句中包含另一个完整的select语句。
或两个以上SELECT,那么就是子查询语句了。
2.子查询出现的位置
where后,把select查询出的结果当作另一个select的条件值
from后,把查询出的结果当作一个新表;
示例表

使用
查询与项羽同一个部门人员工
1.先查出项羽所在的部门编号
SELECT deptno FROM emp WHERE ename = '项羽';
2.再根据编号查同一部门的员工
SELECT ename,depatno FROM emp WHERE depatno = (SELECT deptno FROM emp WHERE ename = '项羽');
把第1条查出来的结果当第2天语句的条件
查询工资高于程咬金的员工
1.查出程咬金的工资
SELECT salary FROM emp WHERE ename = '程咬金';
2.再去根据查出的结果查询出大于该值的记录员工名称
SELECT ename,salary FROM emp WHERE salary > (SELECT salary FROM emp WHERE ename='程咬金');
工资高于30号部门所有人的员工信息
1.先查出30号部门工资最高的那个人
SELECT MAX(salary) FROM emp WHERE deptno = 30;
2.再到整个表中查询大于30号部门工资最高的那个人
SELECT ename,salary FROM emp WHERE salary > (SELECT MAX(salary) FROM emp WHERE deptno = 30);
查询工作和工资与妲己完全相同的员工信息
1.先查出妲已的工作和工资
SELECT job,salary FROM emp WHERE ename='妲己';
2.根据查询结果当作条件再去查询工作和工资相同的员工
SELECT ename,job,salary FROM emp WHERE (job,salary) IN (SELECT job,salary FROM emp WHERE enname='妲己');
由于是两个条件,使用 IN进行判断
有2个以上直接下属的员工信息
1.对所有的上级编号进行分组
SELECT mgr,GROUP_CONCAT(mgr) FROM emp GROUP BY mgr;
2.找出大于2个的,大于2个说明有两个下属
SELECT mgr,GROUP_CONCAT(mgr) FROM emp GROUP BY mgr HAVING COUNT(*) >= 2;
3.把上条的结果当作员工编号时行查询
SELECT ename FROM emp WHERE empno IN (SELECT mgr FROM emp GROUP BY mgr HAVING COUNT(*) >= 2)
查询员工编号为7788的员工名称、员工工资、部门名称、部门地址
SELECT e.name,e.salary,d.dname,d.local FROM emp e,dept d WHERE e.deptno = d.deptno AND empno = 7788;
自连接
求7369员工编号、姓名、经理编号和经理姓名
SELECT * FROM emp WHERE empno = (SELECT mgr FROM emp WHERE empno=7369);
以上这种方法只能查询出一个经理的名称
自连接:自己连接自己,起别名
SELECT * FROM emp e1,emp e2 WHERE e1.mgr = e2.empno AND e1.empno = 7369;
老九学堂会员社群出品