《Modeling Multi-turn Conversation with Deep Utterance Aggregation》阅读笔记
论文原文:https://arxiv.org/pdf/1806.09102.pdf
刚看到小夕的这篇总结个人感觉讲的很好很容易理解,里面涉及了4篇论文串烧,按照时间讲了算法的发展,文风也蛮有趣(有点嗲,哈哈~)
上海交通大学等2018年发表的文章,主要涉及基于检索式的多伦问答模型,提出了一个深度对话整合模型(DUA),是针对多轮对话将过去会话直接拼接作为上下文信息存在噪声和冗余等问题,DUA从对话和回复中采用attention机制挖掘关键信息,凸显关键信息忽略冗余信息,最终获得utterances和response的匹配得分。本文还发布了一个电子商务对话语料库ECD,涉及到商品咨询、物流快递、推荐、谈判、聊天等,本文的数据集及代码。结构如下可分为5个模块:
DUA的优点:
-
最后一轮对话很好的与前面对话结合,其最主要信息可以更好的用语义相关的方法来解决
-
每轮会话可以凸显关键信息,从一定程度上忽略冗余信息
-
计算最终匹配得分的时候充分考虑各轮对话之间的关系
Utterance Representation
采用GRU模型将每个utterance和候选response进行embedding。
Turns-aware Aggregation
Utterance Representation是将utterance同等看待没有考虑the last utterance和之前对话之间的关系,该模块主要是将最后一个utterance(the last utterance)与context中的其他utterance以及候选response进行融合,论文中是直接将utterances和response的embedding串联起来,得到表征F。

Matching Attention Flow
该模块是对上一模块turns-aware的表征信息F信息进行处理,采用一个self-matching attention mechanism将冗余信息进行过滤,挖掘utterances和response中的显著特征,即通过一个attention机制的GRU进一步做表征的交互与融合。

[·,·] 是两个向量串联在一起 ,Ct是self-matching attention的输出
Response Matching
第四模块在单词和会话级别上对 response和each utterance进行匹配,经过CNN形成匹配向量。
这里从两个粒度进行匹配:
- 词粒度:u和r都是相应utterance和response中的某一个词,通过下式可以得到这两个句子相应位置上的匹配度。最后这些各个位置上词粒度的匹配度可以形成一个shape为(utterance长度,response长度)的矩阵M1

- 句子粒度:P是上一个模块中得到的utterance和response中各个位置上的表征,同样可以得到一个shape为(utterance长度,response长度)的矩阵M2
尔后分别在这两个矩阵上进行CNN卷积操作,得到卷积之后的表征。
最后进行max-pooling和flatten之后concatenation。

Attentive Turns Aggregation
将匹配向量按上下文话语的时间顺序传递GRU,得到utterance和response的最终匹配得分,分为三步:
- 第一步:先通过一个GRU;

- 第二步:attention机制;

- 第三步:加一个softmax,得到匹配度。

参考:
https://www.paperweekly.site/papers/2352
https://zhuanlan.zhihu.com/p/44539292
检索式多轮问答系统模型总结
上篇对话系统综述的结尾, 文章作者列出3篇检索式问答系统的工作, 经了解发现都是出自MSRA、baidu等大佬团队, 所以笔者也赶忙扶正眼镜, 准备提高姿势水平. 之前我们提到, 检索式的单轮问答系统可视为语义匹配问题, 从下面分享的几篇文章看, 单轮扩展到多轮, 核心就是如何设计更有效的特征提取结构, 因此单轮问答系统的思路是值得借鉴的.
Multi-view Response Selection for Human-Computer Conversation
本文出自百度自然语言处理部, 发表于EMNLP2016, 作者提供了一种直接的单轮转多轮思路——将多轮问答语句合并为一列, 连接处用_SOS_隔开, 将整个对话历史视为"一句话"去匹配下一语. 如下图所示

将整个对话历史合并为一列, 做word embedding后通过GRU模块提取词汇级特征, 与候选的response做匹配. 熟悉语义匹配或单轮问答的观众老爷应该看得出这部分与单轮问答没有任何区别.
不过如此长的多语句序列靠一个GRU显然是不够的, 作者在此基础上提出了获取语句级特征的方法, 其结构也非常简单, 就是TextCNN+pooling+GRU, 其实这也是单轮问答提取多粒度文本表示特征的思路. 下图很清楚的展示了词汇-语句特征的提取模块的结合
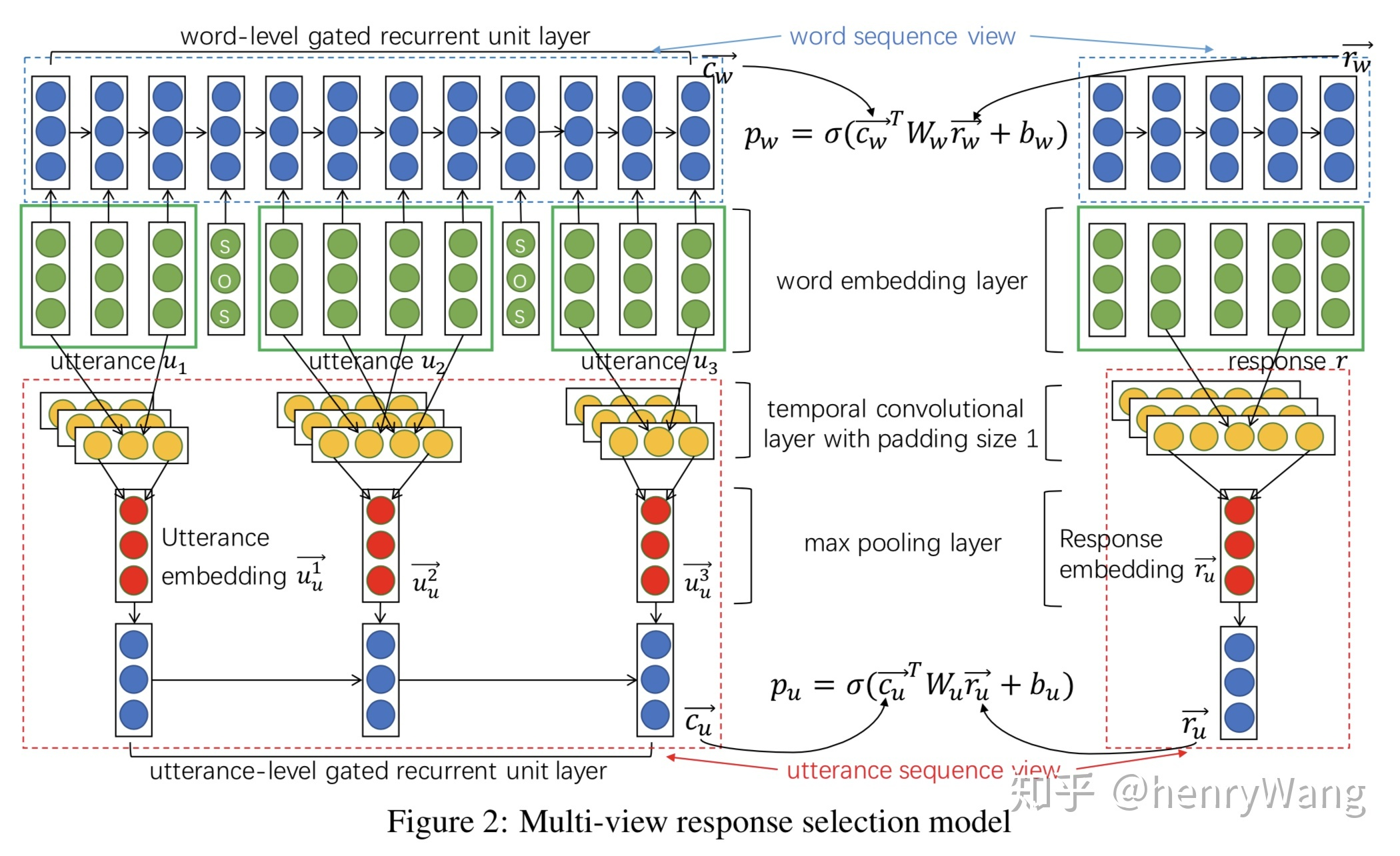

此外, 本文在损失函数部分也有技巧, 结合disagreement-loss(LD)和likelihood-loss(LL)的损失最小化过程也一定程度地利用了不同粒度特征的交互信息.
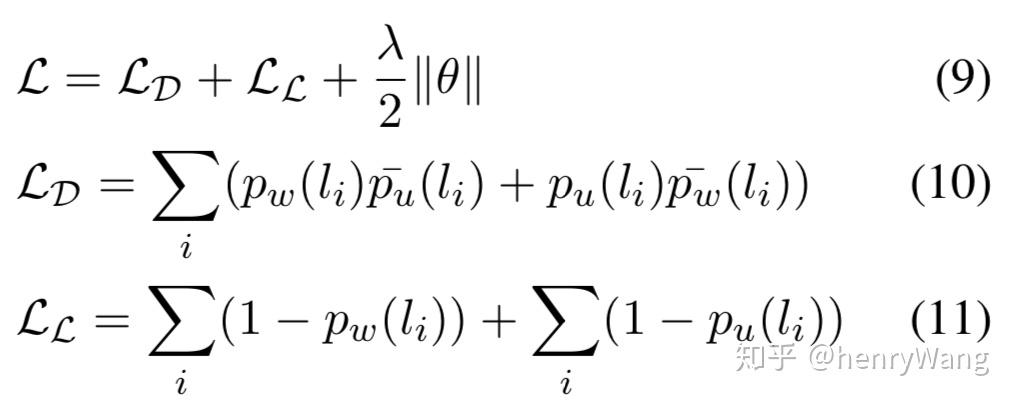
Sequential Matching Network A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots (SMN)
本文发表于ACL2017, 是MSRA大佬的佳作. 如果说第一篇Multi-view模型是单轮问答表示模型的扩展, 那这一篇就是单轮问答交互模型的扩展. 作者认为构建问答历史语句和候选回复的交互表示是重要的特征信息, 因此借鉴语义匹配中的匹配矩阵, 并结合CNN和GRU构造模型, 具体结构如下图

与Multi-view模型类似, 这里作者也考虑同事提取词汇级和语句级的特征, 分别得到两个匹配矩阵M1和M2, 具体的:
- Word-Matching-M1: 对两句话的词做word embedding, 再用dot(ei,ej)计算矩阵元素——直接计算 word embedding 的余弦相似性
- Utterance-Matching-M2: 对两句话的词做word embedding, 再过一层GRU提取隐状态变量h, 然后用dot(hi,A*hj)计算矩阵元素——word embedding 后再来一层 GRU,再计算隐层的相似性

得到的两个匹配矩阵可视为两个通道, 再传给CNN+Pooling获得一组交互特征{vi}. 交互特征传入第二个GRU层, 得到{h'i}
最后的预测层, 作者设计了三种利用隐变量{h'i}的方式:
- last: 只用最后一个h'last传入softmax计算score
- linearly combined: 将{h'i}线性加权传给softmax
- attention: 利用attention机制计算{h'i}的权重
作者的实验表明采用attention的SMN效果最好, 但训练相对最复杂, last最简单且效果基本优于linearly combined.
值得一提的是本文的实验数据, 英文数据集来自开放的Ubuntu Forum, 里面包含1百万context-response对训练集, 5万测试集和5万验证集; 中文数据集来自Douban Conversation Corpus, 包含1百万训练集, 1万验证集和1万测试集, 作者公开了该数据集, 看官老爷可以去文中的github地址下载. 在此对作者表示感激.
另外之前那篇综述中还有一篇来自baidu的相关工作, 该文发表在SIGIR2016, 作者将问答语句对分为Query-Reply, Query-Posting和Query-Context三类, 尝试用这种多角度response排序模式提升模型. 不过本文的整体架构与上述的RNN、CNN组合思路并无差别, 就不多介绍了~
Modeling Multi-turn Conversation with Deep Utterance Aggregation (DUA)
本文来自COLING2018, 文章提出, 诸如Multi-view和SMN模型都是将对话历史视为整体, 或者说每一句对于response都是平等的, 这样做会忽略对话历史的内部特征, 例如一段对话过程经常包含多个主题; 此外一段对话中的词和句的重要性也都不同. 针对这些对话历史中的信息特征, 作者设计了下图所示的DUA模型

模型分为5个部分:
- 第一部分: 通用的词向量+GRU做embedding
- 第二部分: 开始着手处理上面提到的对话历史交互问题, 首先虽然history中的多句话都对response有影响, 但最后一句通常是最关键的, 这一层的每个utterance(除最后一句)和response都和最后一句utterence做aggregation操作, aggregation操作有三种: 连接(concatenation), 元素加(element-wise summation), 元素乘(element-wise multiplication), 其中连接操作的效果最好
- 第三部分: 以utterance为单元做self-attention, 目的是过滤冗余(比如无意义的空洞词句), 提取关键信息, 由于self-attention会失去序列信息, 作者在attention上又加了一层GRU获得带顺序信息的P
- 第四部分: 完全采用SMN中构建和处理双通道匹配矩阵的策略, 用第一层的词向量和上一层的GRU输出P分别构建词汇级和语句级的匹配矩阵, 过CNN+Pooling获得交互特征
- 第五部分: 先将交互特征传给一层GUR获得隐状态h, 再对h和第三部分的GRU输出P做attention(h, P)操作, 将输出传给softmax获得预测匹配结果
可以看出DUA模型侧重于对词汇和语句都做多层特征提取, 实验结果也表明利用多层级多粒度特征的模型比前作SMN等模型都有不小的提升. 并且除了Ubuntu Froum和Douban Conversation Corpus两个数据集外, 本文作者还公开了一批中文数据 E-commerce Dialogue Corpus. 该数据取自淘宝, 包含1百万训练集, 1万验证集和1万测试集. 作者在文中给出了github项目地址, 数据共享在Google driver上. 特别感谢作者开放数据集.
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network (DAM)
下面再次出自百度自然语言处理部, 发表于ACL2018. 作者的attention组合技让人眼花缭乱, 尤其最后那个21维单元组成的3维立方体.... 不过下图展示的整体结构是非常清晰的
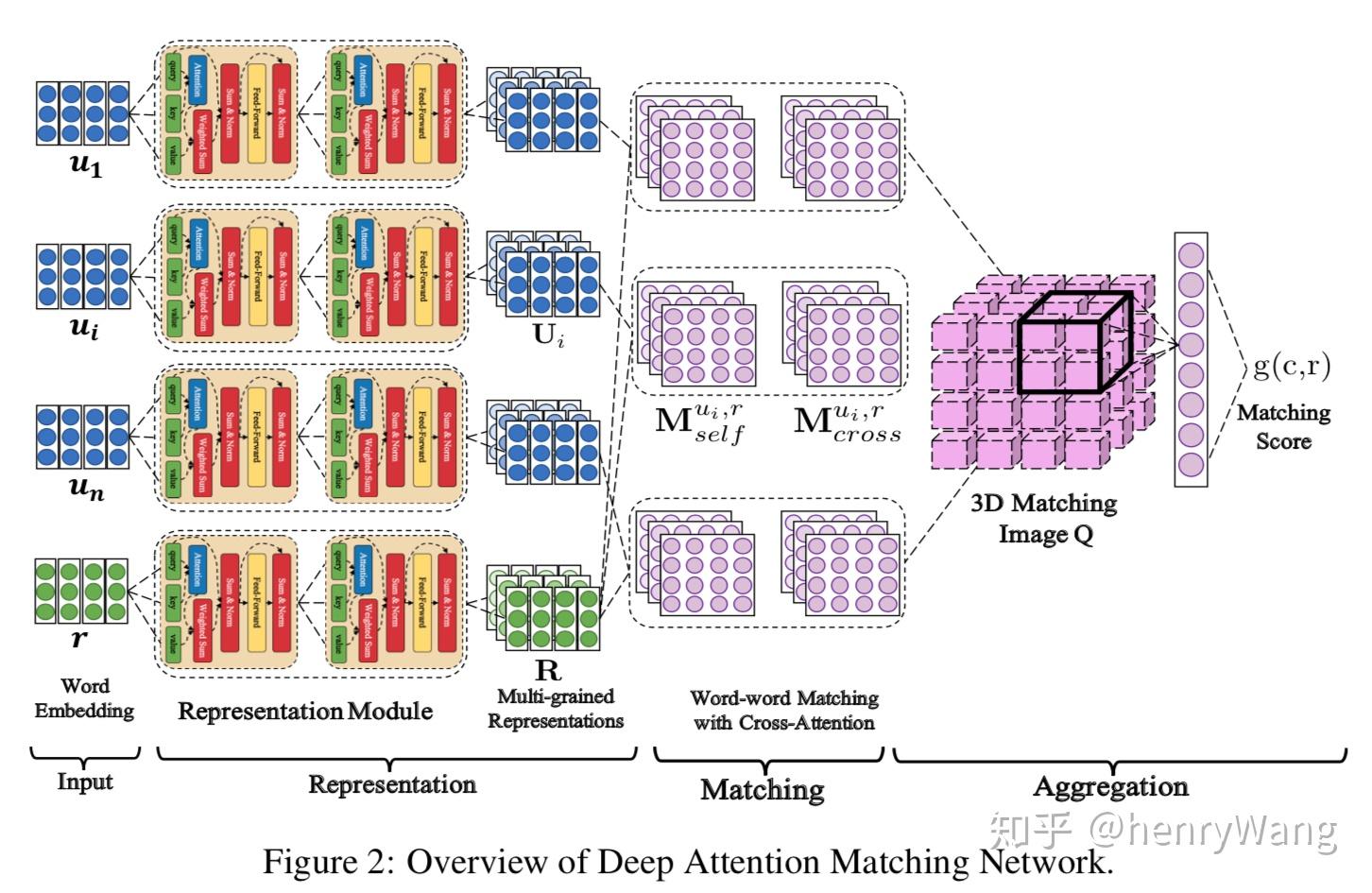
DAM模型以self-attention为基础, 稍作修改加入了cross-attention. 两种attention计算再结合匹配矩阵的思维构造了那个立方体, 最后用3D-CNN处理. 下面为大家详细介绍几个关键部分
- Representation
第一层Input就是单纯做词向量, embedding后传给了五颜六色的Attentive Module, 这里的每个Module其实就是略有修改的Transformer.

对话历史以句子为单位, 与response一起通过L个Attentive Module, 每个utterance和response都获得了L个矩阵U和R, 就是结构图第三列, 蓝色是每个句子ui的L个矩阵合并的Ui, 绿色是response对应的L矩阵组成的R.
- Matching
这里DAM模型同样有两种匹配矩阵, 不过构建思路就相对复杂了, 其中第一列Mself称为自注意力匹配(self-attention-match), 第二列Mcross称为交叉注意力匹配(cross-attention-match) Mself的构建相对简单, 上一层不是每个句子得到了ui和response都得到了L个矩阵构成的组Ui和R么, Mself就按下图的公式得到

上式给出了构建ui和response的Mselfi的过程. 由于ui和response的矩阵组Usub>i和R都包含L个矩阵, 这个Mselfi也是由L个矩阵构成的组, 每个矩阵l的第个元素就是U和R中第l个矩阵的元素uk和rt点乘计算得到. 对每个句子-回复组成的ui和response都做一遍上述计算, 就得到了n个Mself (注意n是对话历史中的utterance个数, 因此就有n个utterance-response对, 所以就有n个Mself, 每个Mself都由L个矩阵组成, 下面Mcross相同)
Mcross的构造过程和Mself一样, 区别在于这里的U和R是用cross-attention构造, 而Mself的U和R是self-attention构造, 下面给出对于句子ui和response的两种attention的计算方法(公式5,6为self-attention; 8,9为cross-attention, 10是计算cross-attention-match):


- Aggregation
最后的立方体Q就是通过两种匹配矩阵Mself和Mcross计算得到的. 最后用两层3D的CNN处理这个立方体, 得到的特征传给单层网络估计匹配程度.
Q有n个切片, 对应n个utterance-response对的匹配矩阵, 每一片的尺寸都是(nui, nr)对应匹配矩阵中每个矩阵的尺寸, 特别的, Q的每个元素都是由对应的Mselfi和Mcrossi连接得到的, 公式如下 (注: 文中Representation层的Module是从0算起到L, 故为L+1)
实验部分作者分别对比了5种不同的的DAM, 可以看到去掉DAMcross会造成很大的损失, Attentive Module的最后一层产生的效果优于第一层.

Learning Matching Models with Weak Supervision for Response Selection in Retrieval-based Chatbots
这一篇同样出自ACL2018的文章就相对轻松了, BTW本文作者也是SMN模型的作者, 这里没有展示复杂的模型, 而是讨论了如何降低手工标注工作量, 充分利用少量标注数据和大量未标注数据, 以及改进学习方法减少噪声, 优化决策面的思路. 具体的作者提出了一种借助seq2seq模型给未标注数据提供评判标记(matching signals)的方法, 可以结合上述模型共同使用, 实验结果显示用于SMN和multi-view上均有一定程度的提升. 另外作者设计了一种采样副样本的方法, 并配合给出了一种学习函数, 采样思路其实就是选择一些与正样本效果接近的(难以区分的)负样本, 原因不难想象, 简单的负样本会拖拽决策面, 使得与正样本接近的负样本无法被正确区分. 作者还用4组对比实验证明了较多的采样个数可以提升模型效果.
最后要私自蹭波知乎仙女大神 的腿. 作者对上述模型的介绍比笔者不知高到哪里去, 忍受笔者私货荼毒的看官老爷们可以移步知乎大佬区自行解毒.
夕小瑶:小哥哥,检索式chatbot了解一下?zhuanlan.zhihu.com