一、Redis集群介绍
Clustering:
redis 3.0之后进入生产环境
分布式数据库,通过分片机制来进行数据分布,clustering 内的每个节点,仅有数据库的一部分数据;
去中心化的集群:
redis集群中的每一个节点,都可以作为集群的接入节点。//每一个node都有全局元数据,client访问哪一个node都可以获取所有的node
client向任意node发起请求,该node会返回给client真正的key所在node,然后让client去获取。
每一个节点持有全局元数据,但仅持有部分数据。
redis分布式的常见解决方案:
Twemproxy(Twitter)
Codis(豌豆荚)
Redis Cluster(官方)
Cerberus(芒果TV)
1、Twemproxy特点:
代理分片机制
优点:
非常稳定,企业级方案
缺点:
单点故障
需依赖第三方软件,例如keepalived //进行HA
无法平滑地横向扩展
没有后台界面
代理分片机制引入更多的来回次数并提高延迟
单核模式,无法重新利用多核,除非多实例
Twitter官方内部不再私用Twemproxy
图1: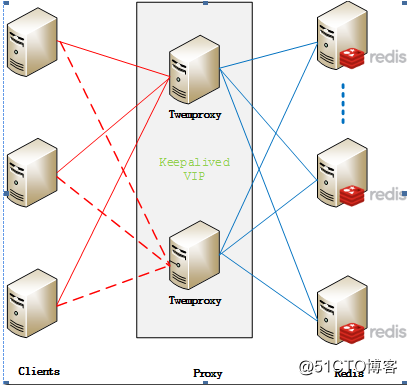
2、Codis(豌豆荚)
代理分片机制
2014年开源
基于Go以及C语言研发
优点:
文档充足,企业级方案
数据自动平衡
高性能
简单的测试显示较Twemproxy快一倍
善用多核CPU
简单:
没有paxos类的协调机制
没有主从复制
有后台界面
缺点:
代理分片机制引入更多的来回次数并提高延迟 //更多的ping(pong)操作
需要第三方软件支持协调机制 //目前支持Zookeeper及Etcd
不支持主从复制,需要另外实现
Codis采用proxy方案,所以必然会带来单机性能的损失,
静测试,在不开pipeline的情况下,大概会损失40%左右的性能
3、Redis cluster(官方)
官方实现
需要Redis 3.0 或更高版本
优点:
无中心的p2p Gossip分散式模式
更少的来回次数并降低延迟
自动于多个Redis节点进行分片,自动均衡
不需要第三方软件支持协调机制
缺点:
依赖于Redis 3.0或更高版本
需要时间验证其稳定性
没有后台界面
需要智能客户端 //万一某个client下线了,client需要知道哪个node在线。
Redis客户端必须支持Redis cluster架构
较Codis有更多的维护升级版本
4、Cerberus(芒果TV)
优点:
数据自动平衡
本身实现了Redis的smart client//server端直接实现了智能client
支持读写分离
缺点:
依赖Redis 3.0或更高版本
代理分片机制引入更多的来回次数并增大延迟
需要时间验证其稳定性
没有后台界面
codis-proxy : 是客户端连接的Redis代理服务,codis-proxy 本身实现了Redis协议,表现得和一个原生的Redis没什么区别(就像Twemproxy),对于一个业务来说,可以部署多个codis-proxy,codis-proxy本身是没状态的。
codis-config :是Codis的管理工具,支持包括,添加/删除Redis节点,添加/删除Proxy节点,发起数据迁移等操作,codis-config本身还自带了一个http server,会启动一个dashboard,用户可以直接在浏览器上观察Codis集群的状态。
codis-server:是Codis项目维护的一个Redis分支,基于2.8.13开发,加入了slot的支持和原子的数据迁移指令,Codis上层的codis-proxy和codis-config只能和这个版本的Redis交互才能正常运行。
ZooKeeper :用来存放数据路由表和codis-proxy节点的元信息,codis-config发起的命令都会通过ZooKeeper同步到各个存活的codis-proxy
二、官方版安装与实现
1、安装与实现
redis-trib.rb的ruby脚本。redis-trib.rb是redis官方推出的管理redis集群的工具,集成在redis的源码src目录下(redis-xxx/src/)
redis-trib.rb是redis作者用ruby完成的。所以redis集群需要先安装ruby环境。
[root@wolf src]# cd /usr/local/src ; wget http://download.redis.io/redis-stable.tar.gz
[root@wolf src]# tar xvf redis-stable.tar.gz
[root@wolf src]# ln -sv redis-stable redis && cd redis
[root@wolf src]# yum install tcl ruby ruby-devel rubygems -y && make && make install
[root@wolf redis-stable]# make -j 4 && taskset -c 1 make test
[root@wolf redis-stable]# make install && cd /usr/local/src/redis-stable/src
[root@wolf src]# cp redis-trib.rb /usr/local/bin/
[root@wolf src]# mkdir /redis/{1201,1202,1203,1204,1205,1206,1207,1208} -pv
[root@wolf src]# cat /redis/1201/redis.conf
port 1201 //分别改为1201,1202,1203,1204...1208
bind 127.0.0.1 //一样
daemonize yes
pidfile /var/run/redis_1201.pid
cluster-enabled yes
cluster-config-file node_1201.conf //自动生成的,不需要配置
cluster-node-timeout 15000 //超时多久认为其宕机了
appendonly yes
cluster-require-full-coverage no //默认是yes只要有结点宕机导致16384个槽没全被覆盖,整个集群就全部停止服务,所以一定要改为no
logfile "./redis.log" //日志文件
cluster-slave-validity-factor 0 //出现master监测异常之后,立马failover
//cluster-slave-validity-factor <factor> //0:不管slave和master失联多久都会一直尝试failover(设为正数),失联大于一定时间(factor*TimeOut)不再进行FailOver。比如如果TimeOut设置为5s,该项设置为10s,如果master和slave失联超过50s,slave不会去failover它的master(不会去取代master)
注意:任意非0值都有可能导致当master挂掉又没有slave给他,这样redis集群不可用。这种情况只有原来的master重新回到集群中才能让集群恢复工作
//另外几个配置文件参考1201的配置文件修改[root@node112 redis]# redis-server /redis/{1201,1202,,,,1208}/redis.conf
[root@node112 redis]# ps -ef |grep redis
root 35965 1 0 22:16 ? 00:00:04 redis-server 127.0.0.1:1201 [cluster]
root 35985 1 0 22:17 ? 00:00:04 redis-server 127.0.0.1:1202 [cluster]
root 35990 1 0 22:17 ? 00:00:04 redis-server 127.0.0.1:1203 [cluster]
root 35995 1 0 22:17 ? 00:00:04 redis-server 127.0.0.1:1204 [cluster]
root 40784 1 0 22:48 ? 00:00:00 redis-server 127.0.0.1:1205 [cluster]
root 40789 1 0 22:48 ? 00:00:00 redis-server 127.0.0.1:1206 [cluster]
root 40794 1 0 22:48 ? 00:00:00 redis-server 127.0.0.1:1207 [cluster]
root 40799 1 0 22:48 ? 00:00:00 redis-server 127.0.0.1:1208 [cluster][root@node112 redis]# redis-trib.rb --help
/usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require': cannot load such file -- redis (LoadError)
from /usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require'
from /usr/local/bin/redis-trib.rb:25:in `<main>'
需要安装ruby的client # gem install redis //要求ruby版本2.2之上,假如版本低更新ruby版本如下
# yum install autoconf automake bison libffi-devel libtool readline-devel sqlite-devel libyaml-devel
# curl -sSL https://rvm.io/mpapis.asc | gpg --import -
# curl -L get.rvm.io | bash -s stable
# source /etc/profile.d/rvm.sh //加载RVM环境。
# rvm reload
# rvm requirements run
# rvm install 2.4.2 //安装ruby2.4
设置默认的ruby版本:
# rvm list
# rvm use 2.4.2 --default
# ruby --version[root@node112 ~]# redis-trib.rb create --replicas 1 127.0.0.1:1201 127.0.0.1:1202 127.0.0.1:1203 127.0.0.1:1204 127.0.0.1:1205 127.0.0.1:1206 127.0.0.1:1207 127.0.0.1:1208
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.......
>>> Performing Cluster Check (using node 127.0.0.1:1201)
M: d392057bb258248b09db27e57da53e6277bfbb87 127.0.0.1:1201
slots:0-4095 (4096 slots) master
1 additional replica(s)
M: 8ee780051bba2d62514c3adddb6ad050128309c2 127.0.0.1:1204
slots:12288-16383 (4096 slots) master
1 additional replica(s)
S: 84fc85c03e8cd1d20b794a36091ccfd5235d3403 127.0.0.1:1207
slots: (0 slots) slave
replicates 32d3f692b64dd438d5ff9c4729be53c55d3768bb
S: e92354f4f158e5c45c508cf494dfd99892437bb4 127.0.0.1:1208
slots: (0 slots) slave
replicates 8ee780051bba2d62514c3adddb6ad050128309c2
S: a23562b6abf030b912f950c0e1fe2f576d4e1b8d 127.0.0.1:1205
slots: (0 slots) slave
replicates 8251d8d4bde7dd099acb462094d2132b94457481
M: 32d3f692b64dd438d5ff9c4729be53c55d3768bb 127.0.0.1:1203
slots:8192-12287 (4096 slots) master
1 additional replica(s)
S: b31e1d76d83c050c5870caaaf7a6807b3b5c16a3 127.0.0.1:1206
slots: (0 slots) slave
replicates d392057bb258248b09db27e57da53e6277bfbb87
M: 8251d8d4bde7dd099acb462094d2132b94457481 127.0.0.1:1202
slots:4096-8191 (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@node112 ~]#
[root@node112 ~]# netstat -tunlp |grep -i redis
tcp 0 0 127.0.0.1:1201 0.0.0.0:* LISTEN 35965/redis-server
tcp 0 0 127.0.0.1:1202 0.0.0.0:* LISTEN 35985/redis-server
tcp 0 0 127.0.0.1:1203 0.0.0.0:* LISTEN 35990/redis-server
tcp 0 0 127.0.0.1:1204 0.0.0.0:* LISTEN 35995/redis-server
tcp 0 0 127.0.0.1:1205 0.0.0.0:* LISTEN 40784/redis-server
tcp 0 0 127.0.0.1:1206 0.0.0.0:* LISTEN 40789/redis-server
tcp 0 0 127.0.0.1:1207 0.0.0.0:* LISTEN 40794/redis-server
tcp 0 0 127.0.0.1:1208 0.0.0.0:* LISTEN 40799/redis-server
tcp 0 0 127.0.0.1:11201 0.0.0.0:* LISTEN 35965/redis-server
tcp 0 0 127.0.0.1:11202 0.0.0.0:* LISTEN 35985/redis-server
tcp 0 0 127.0.0.1:11203 0.0.0.0:* LISTEN 35990/redis-server
tcp 0 0 127.0.0.1:11204 0.0.0.0:* LISTEN 35995/redis-server
tcp 0 0 127.0.0.1:11205 0.0.0.0:* LISTEN 40784/redis-server
tcp 0 0 127.0.0.1:11206 0.0.0.0:* LISTEN 40789/redis-server
tcp 0 0 127.0.0.1:11207 0.0.0.0:* LISTEN 40794/redis-server
tcp 0 0 127.0.0.1:11208 0.0.0.0:* LISTEN 40799/redis-server Redis集群不仅需要开通redis客户端连接的端口,而且需要开通集群总线端口,集群总线端口为redis客户端连接的端口 + 10000
[root@node112 redis]# redis-cli -h 127.0.0.1 -p 1201
测试:
终端一:订阅
[root@node112 ~]# redis-cli -h 127.0.0.1 -p 1206
127.0.0.1:1206> SUBSCRIBE mm
终端二:发布
[root@node112 redis]# redis-cli -h 127.0.0.1 -p 1201
127.0.0.1:1201> PUBLISH mm "test for messages"
在终端一上查看
[root@node112 ~]# redis-cli -h 127.0.0.1 -p 1201
127.0.0.1:1201> set hello "hello worlld"
OK
[root@node112 ~]# redis-cli -h 127.0.0.1 -p 1205 -c //-c使用集群模式
127.0.0.1:1205> get hello
-> Redirected to slot [866] located at 127.0.0.1:1201
"hello worlld"2、集群相关命令
redis-cluster把所有的物理节点映射到[0-16383]个slot(hash槽)上,由cluster负责维护node<->slot<->value
集群选举容错:节点fail选举是过程是集群中所有master参与,半数以上master与被检测node监测超时(cluster-node-timeout),就认为当前master节点down
集群不可用:cluster:fail
1.集群任意master挂掉,且当前master没有slave。集群进入fail状态,也可以理解成集群的slot映射[0-16838]不完整时进入fail状态。
2.集群半数以上master挂掉,收到error clusterdown The Cluster is down的错误
集群优缺点:
优点:
在master节点下线后,slave节点会自动提升为master,保证集群可用性
fail node复活后,自动添加到集群中,变成slave节点。
缺点:
redis的复制使用异步复制机制,auto-fail-over的过程中。集群可能会丢失write命令。然而redis几乎是同时执行(将命令恢复发送给客户端,以及将命令复制到slave节点)这两个操作。所以实际操作中,丢失的可能性非常小
127.0.0.1:1202> help @cluster
集群:
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
节点:
cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽(slot):
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
键:
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键 3、redis-trib.rb命令详解
redis-trib.rb help //查看帮助信息
redis-trib.rb主要有两个类:ClusterNode和RedisTrib。ClusterNode保存了每个节点的信息,RedisTrib则是redis-trib.rb各个功能的实现。
create:创建集群 //redis-trib.rb create --replicas 1 $host1:port1 $host2:port2 ...
check:检查集群
info:查看集群信息
fix:修复集群
reshard:在线迁移slot
rebalance:平衡集群节点slot数量
add-node:将新节点加入集群
del-node:从集群中删除节点
set-timeout:设置集群节点间心跳连接的超时时间
call:在集群全部节点上执行命令
import:将外部redis数据导入集群3.1、create:创建集群 //redis-trib.rb create --replicas 1 $host1:port1 $host2:port2 ...
1、首先为每个节点创建ClusterNode对象,包括连接每个节点。检查每个节点是否为独立且db为空的节点。执行load_info方法导入节点信息。
2、检查传入的master节点数量是否大于等于3个。只有大于3个节点才能组成集群。//master+slave大于6个
3、计算每个master需要分配的slot数量,以及给master分配slave。分配的算法大致如下:
先把节点按照host分类,这样保证master节点能分配到更多的主机中。
不停遍历遍历host列表,从每个host列表中弹出一个节点,放入interleaved数组。直到所有的节点都弹出为止。
master节点列表就是interleaved前面的master数量的节点列表。保存在masters数组。
计算每个master节点负责的slot数量,保存在slots_per_node对象,用slot总数除以master数量取整即可。
遍历masters数组,每个master分配slots_per_node个slot,最后一个master,分配到16384个slot为止。
接下来为master分配slave,分配算法会尽量保证master和slave节点不在同一台主机上。对于分配完指定slave数量的节点,还有多余的节点,也会为这些节点寻找master。分配算法会遍历两次masters数组。
第一次遍历masters数组,在余下的节点列表找到replicas数量个slave。每个slave为第一个和master节点host不一样的节点,如果没有不一样的节点,则直接取出余下列表的第一个节点。
第二次遍历是在对于节点数除以replicas不为整数,则会多余一部分节点。遍历的方式跟第一次一样,只是第一次会一次性给master分配replicas数量个slave,而第二次遍历只分配一个,直到余下的节点被全部分配出去。
4、打印出分配信息,并提示用户输入“yes”确认是否按照打印出来的分配方式创建集群。
5、输入“yes”后,会执行flush_nodes_config操作,该操作执行前面的分配结果,给master分配slot,让slave复制master,对于还没有握手(cluster meet)的节点,slave复制操作无法完成,不过没关系,flush_nodes_config操作出现异常会很快返回,后续握手后会再次执行flush_nodes_config。
6、给每个节点分配epoch,遍历节点,每个节点分配的epoch比之前节点大1。
7、节点间开始相互握手,握手的方式为节点列表的其他节点跟第一个节点握手。
8、然后每隔1秒检查一次各个节点是否已经消息同步完成,使用ClusterNode的get_config_signature方法,检查的算法为获取每个节点cluster nodes信息,排序每个节点,组装成node_id1:slots|node_id2:slot2|...的字符串。如果每个节点获得字符串都相同,即认为握手成功。
9、此后会再执行一次flush_nodes_config,这次主要是为了完成slave复制操作。
10、最后再执行check_cluster,全面检查一次集群状态。包括和前面握手时检查一样的方式再检查一遍。确认没有迁移的节点。确认所有的slot都被分配出去了。
11、至此完成了整个创建流程,返回[OK] All 16384 slots covered.。
3.2、check检查集群状态
[root@node112 redis]# redis-trib.rb check 127.0.0.1:1201
检查集群状态,只需要选择一个集群中的一个节点即可。
检查前会先执行load_cluster_info_from_node方法,把所有节点数据load进来。load的方式为通过自己的cluster nodes发现其他节点,然后连接每个节点,并加入nodes数组。接着生成节点间的复制关系。
load完数据后,开始检查数据,检查的方式也是调用创建时候使用的check_cluster。
3.3、info查看集群信息
info命令也是先执行load_cluster_info_from_node获取完整的集群信息。然后显示ClusterNode的info_string结果
[root@node112 redis]# redis-trib.rb info 127.0.0.1:1201
127.0.0.1:1204 (9a60d0fc...) -> 0 keys | 4096 slots | 1 slaves.
127.0.0.1:1203 (31f66735...) -> 1 keys | 4096 slots | 1 slaves.
127.0.0.1:1209 (a4dc7dd4...) -> 0 keys | 4096 slots | 2 slaves.
127.0.0.1:1202 (56b03fec...) -> 0 keys | 4096 slots | 1 slaves.
[OK] 1 keys in 4 masters.
0.00 keys per slot on average.3.4、fix修复集群
目前fix命令能修复两种异常,一种是集群有处于迁移中的slot的节点,一种是slot未完全分配的异常。
fix_open_slot方法是修复集群有处于迁移中的slot的节点异常。
1、先检查该slot是谁负责的,迁移的源节点如果没完成迁移,owner还是该节点。没有owner的slot无法完成修复功能。
2、遍历每个节点,获取哪些节点标记该slot为migrating状态,哪些节点标记该slot为importing状态。对于owner不是该节点,但是通过cluster countkeysinslot获取到该节点有数据的情况,也认为该节点为importing状态。
3、如果migrating和importing状态的节点均只有1个,这可能是迁移过程中redis-trib.rb被中断所致,直接执行move_slot继续完成迁移任务即可。传递dots和fix为true。
4、如果migrating为空,importing状态的节点大于0,那么这种情况执行回滚流程,将importing状态的节点数据通过move_slot方法导给slot的owner节点,传递dots、fix和cold为true。接着对importing的节点执行cluster stable命令恢复稳定。
5、如果importing状态的节点为空,有一个migrating状态的节点,而且该节点在当前slot没有数据,那么可以直接把这个slot设为stable。
6、如果migrating和importing状态不是上述情况,目前redis-trib.rb工具无法修复,上述的三种情况也已经覆盖了通过redis-trib.rb工具迁移出现异常的各个方面,人为的异常情形太多,很难考虑完全。
fix_slots_coverage方法能修复slot未完全分配的异常。未分配的slot有三种状态。
1、所有节点的该slot都没有数据。该状态redis-trib.rb工具直接采用随机分配的方式,并没有考虑节点的均衡。本人尝试对没有分配slot的集群通过fix修复集群,结果slot还是能比较平均的分配,但是没有了连续性,打印的slot信息非常离散。
2、有一个节点的该slot有数据。该状态下,直接把slot分配给该slot有数据的节点。
3、有多个节点的该slot有数据。此种情况目前还处于TODO状态,不过redis作者列出了修复的步骤,对这些节点,除第一个节点,执行cluster migrating命令,然后把这些节点的数据迁移到第一个节点上。清除migrating状态,然后把slot分配给第一个节点。
3.5、reshard在线迁移slot
在线把集群的一些slot从集群原来slot负责节点迁移到新的节点,利用reshard可以完成集群的在线横向扩容和缩容。
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
host:port:这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口。
--from <arg>:需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入。
--to <arg>:slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入。
--slots <arg>:需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--yes:设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard。
--timeout <arg>:设置migrate命令的超时时间。
--pipeline <arg>:定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
迁移的流程如下:1、通过load_cluster_info_from_node方法装载集群信息。
2、执行check_cluster方法检查集群是否健康。只有健康的集群才能进行迁移。
3、获取需要迁移的slot数量,用户没传递--slots参数,则提示用户手动输入。
4、获取迁移的目的节点,用户没传递--to参数,则提示用户手动输入。此处会检查目的节点必须为master节点。
5、获取迁移的源节点,用户没传递--from参数,则提示用户手动输入。此处会检查源节点必须为master节点。--from all的话,源节点就是除了目的节点外的全部master节点。这里为了保证集群slot分配的平均,建议传递--from all。
6、执行compute_reshard_table方法,计算需要迁移的slot数量如何分配到源节点列表,采用的算法是按照节点负责slot数量由多到少排序,计算每个节点需要迁移的slot的方法为:迁移slot数量 * (该源节点负责的slot数量 / 源节点列表负责的slot总数)。这样算出的数量可能不为整数,这里代码用了下面的方式处理:
n = (numslots/source_tot_slots*s.slots.length)
if i == 0
n = n.ceil
else
n = n.floor这样的处理方式会带来最终分配的slot与请求迁移的slot数量不一致,这个BUG已经在github上提给作者,https://github.com/antirez/redis/issues/2990。
7、打印出reshard计划,如果用户没传--yes,就提示用户确认计划。
8、根据reshard计划,一个个slot的迁移到新节点上,迁移使用move_slot方法,该方法被很多命令使用,具体可以参见下面的迁移流程。move_slot方法传递dots为true和pipeline数量。
9、至此,就完成了全部的迁移任务。
redis-trib.rb reshard --from all --to 80b661ecca260c89e3d8ea9b98f77edaeef43dcd --slots 11 10.180.157.199:6379
3.6、rebalance平衡集群节点slot数量
ruby redis-trib.rb rebalance --threshold 1 --weight b31e3a2e=5 --weight 60b8e3a1=5 --use-empty-masters --simulate 10.180.157.199:6379
host:port:这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口。
--weight <arg>:节点的权重,格式为node_id=weight,如果需要为多个节点分配权重的话,需要添加多个--weight <arg>参数,即--weight b31e3a2e=5 --weight 60b8e3a1=5,node_id可为节点名称的前缀,只要保证前缀位数能唯一区分该节点即可。没有传递–weight的节点的权重默认为1。
--auto-weights:这个参数在rebalance流程中并未用到。
--threshold <arg>:只有节点需要迁移的slot阈值超过threshold,才会执行rebalance操作。具体计算方法可以参考下面的rebalance命令流程的第四步。
--use-empty-masters:rebalance是否考虑没有节点的master,默认没有分配slot节点的master是不参与rebalance的,设置--use-empty-masters可以让没有分配slot的节点参与rebalance。
--timeout <arg>:设置migrate命令的超时时间。
--simulate:设置该参数,可以模拟rebalance操作,提示用户会迁移哪些slots,而不会真正执行迁移操作。
--pipeline <arg>:与reshar的pipeline参数一样,定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
rebalance命令流程如下:
1、load_cluster_info_from_node方法先加载集群信息。
2、计算每个master的权重,根据参数--weight <arg>,为每个设置的节点分配权重,没有设置的节点,则权重默认为1。
3、根据每个master的权重,以及总的权重,计算自己期望被分配多少个slot。计算的方式为:总slot数量 * (自己的权重 / 总权重)。
4、计算每个master期望分配的slot是否超过设置的阈值,即--threshold <arg>设置的阈值或者默认的阈值。计算的方式为:先计算期望移动节点的阈值,算法为:(100-(100.0*expected/n.slots.length)).abs,如果计算出的阈值没有超出设置阈值,则不需要为该节点移动slot。只要有一个master的移动节点超过阈值,就会触发rebalance操作。
5、如果触发了rebalance操作。那么就开始执行rebalance操作,先将每个节点当前分配的slots数量减去期望分配的slot数量获得balance值。将每个节点的balance从小到大进行排序获得sn数组。
6、用dst_idx和src_idx游标分别从sn数组的头部和尾部开始遍历。目的是为了把尾部节点的slot分配给头部节点。
sn数组保存的balance列表排序后,负数在前面,正数在后面。负数表示需要有slot迁入,所以使用dst_idx游标,正数表示需要有slot迁出,所以使用src_idx游标。理论上sn数组各节点的balance值加起来应该为0,不过由于在计算期望分配的slot的时候只是使用直接取整的方式,所以可能出现balance值之和不为0的情况,balance值之和不为0即为节点不平衡的slot数量,由于slot总数有16384个,不平衡数量相对于总数,基数很小,所以对rebalance流程影响不大。
7、获取sn[dst_idx]和sn[src_idx]的balance值较小的那个值,该值即为需要从sn[src_idx]节点迁移到sn[dst_idx]节点的slot数量。
8、接着通过compute_reshard_table方法计算源节点的slot如何分配到源节点列表。这个方法在reshard流程中也有调用,具体步骤可以参考reshard流程的第六步。
9、如果是simulate模式,则只是打印出迁移列表。
10、如果没有设置simulate,则执行move_slot操作,迁移slot,传入的参数为:quiet=>true,:dots=>false,:update=>true。
11、迁移完成后更新sn[dst_idx]和sn[src_idx]的balance值。如果balance值为0后,游标向前进1。
12、直到dst_idx到达src_idx游标,完成整个rebalance操作。3.7、add-node将新节点加入集群
--slave:设置该参数,则新节点以slave的角色加入集群
--master-id:这个参数需要设置了--slave才能生效,--master-id用来指定新节点的master节点。如果不设置该参数,则会随机为节点选择master节点。
ruby redis-trib.rb add-node --slave --master-id dcb792b3e85726f012e83061bf237072dfc45f99 10.180.157.202:6379 10.180.157.199:6379add-node流程如下:
1、通过load_cluster_info_from_node方法转载集群信息,check_cluster方法检查集群是否健康。
2、如果设置了--slave,则需要为该节点寻找master节点。设置了--master-id,则以该节点作为新节点的master,如果没有设置--master-id,则调用get_master_with_least_replicas方法,寻找slave数量最少的master节点。如果slave数量一致,则选取load_cluster_info_from_node顺序发现的第一个节点。load_cluster_info_from_node顺序的第一个节点是add-node设置的existing_host:existing_port节点,后面的顺序根据在该节点执行cluster nodes返回的结果返回的节点顺序。
3、连接新的节点并与集群第一个节点握手。
4、如果没设置–slave就直接返回ok,设置了–slave,则需要等待确认新节点加入集群,然后执行cluster replicate命令复制master节点。
5、至此,完成了全部的增加节点的流程。
3.8、del-node从集群中删除节点
del-node可以把某个节点从集群中删除。del-node只能删除没有分配slot的节点。删除命令传递两个参数:
host:port:从该节点获取集群信息。
node_id:需要删除的节点id。
del-node执行结果示例如下:
redis-trib.rb del-node 10.180.157.199:6379 d5f6d1d17426bd564a6e309f32d0f5b96962fe53
3.9、set-timeout设置集群节点间心跳连接的超时时间
set-timeout用来设置集群节点间心跳连接的超时时间,单位是毫秒,不得小于100毫秒,因为100毫秒对于心跳时间来说太短了。该命令修改是节点配置参数cluster-node-timeout,默认是15000毫秒。通过该命令,可以给每个节点设置超时时间,设置的方式使用config set命令动态设置,然后执行config rewrite命令将配置持久化保存到硬盘。
ruby redis-trib.rb set-timeout 10.180.157.199:6379 30000
3.10、call在集群全部节点上执行命令
call命令可以用来在集群的全部节点执行相同的命令。call命令也是需要通过集群的一个节点地址,连上整个集群,然后在集群的每个节点执行该命令。
redis-trib.rb call 10.180.157.199:6379 get key
3.11、import将外部redis数据导入集群
import命令可以把外部的redis节点数据导入集群。导入的流程如下:
1、通过load_cluster_info_from_node方法转载集群信息,check_cluster方法检查集群是否健康。
2、连接外部redis节点,如果外部节点开启了cluster_enabled,则提示错误。
3、通过scan命令遍历外部节点,一次获取1000条数据。
4、遍历这些key,计算出key对应的slot。
5、执行migrate命令,源节点是外部节点,目的节点是集群slot对应的节点,如果设置了--copy参数,则传递copy参数,如果设置了--replace,则传递replace参数。
6、不停执行scan命令,直到遍历完全部的key。
7、至此完成整个迁移流程
这中间如果出现异常,程序就会停止。没使用--copy模式,则可以重新执行import命令,使用--copy的话,最好清空新的集群再导入一次。
import命令更适合离线的把外部redis数据导入,在线导入的话最好使用更专业的导入工具,以slave的方式连接redis节点去同步节点数据应该是更好的方式。
./redis-trib.rb import --from 10.0.10.1:6379 10.10.10.1:7000 //把 10.0.10.1:6379(redis 2.8)上的数据导入到 10.10.10.1:7000这个节点所在的集群四、redis分布式锁
Redis为单进程单线程模式、采用队列模式将并发访问变成串行访问。且多client对redis的链接并不存在竞争关系。其次Redis提供SETNX,GETSET方便实现分布式锁
条件:
系统是一个分布式系统(关键是分布式,单机的可以使用ReentrantLock或者synchronized代码块来实现)
共享资源(各个系统访问同一个资源,资源的载体可能是传统关系型数据库或者NoSQL)
同步访问(即有很多个进程同事访问同一个共享资源。没有同步访问,谁管你资源竞争不竞争)
分布式锁多种方式实现,比如zookeeper、redis...。不管哪种方式,基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
1、setNX实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系。redis的SETNX命令可以方便的实现分布式锁。
SETNX key value //若给定的 key 已经存在,则 SETNX 不做任何动作。
设置成功,返回 1 。 //exists key1 测试key1是否存在,为0表示不存在,1表示存在
设置失败,返回 0 。
127.0.0.1:1209> SETNX job "yunweigongchengshi"
(integer) 1
127.0.0.1:1209> SETNX job "jiaofugongchengshi" //覆盖设置失败
(integer) 0
127.0.0.1:1209> get job
"yunweigongchengshi"SETNX lock.foo <current Unix time + lock timeout + 1>
返回1:则该客户端获得锁,把lock.foo的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
返回0:表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
GETSET key value
将给定 key 的值设为 value,并返回 key 的旧值(old value)。
当 key 存在但不是字符串类型时,返回一个错误 //当 key 没有旧值时,也即是,key 不存在时,返回 nil 。
127.0.0.1:1209> GETSET job "chanpinjingli" //返回旧指
"yunweigongchengshi"
127.0.0.1:1209> get job //已经修改
"chanpinjingli"
2、解决死锁
删除锁的操作应该是锁拥有这执行的,只需要等它超时即可
当多个客户端检测到锁超时后都会尝试去释放它,这里就可能出现一个竞态条件,让我们模拟一下这个场景:
C0操作超时了,但它还持有着锁,C1和C2读取lock.foo检查时间戳,先后发现超时了。
C1 发送DEL lock.foo
C1 发送SETNX lock.foo 并且成功了。
C2 发送DEL lock.foo
C2 发送SETNX lock.foo 并且成功了。
这样一来,C1,C2都拿到了锁!问题大了!
解决方法:
C3发送SETNX lock.foo 想要获得锁,由于C0还持有锁,所以Redis返回给C3一个0
C3发送GET lock.foo 以检查锁是否超时了,如果没超时,则等待或重试。反之,如果已超时,C3通过下面的操作来尝试获得锁:
GETSET lock.foo <current Unix time + lock timeout + 1>
通过GETSET,C3拿到的时间戳如果仍然是超时的,那就说明,C3如愿以偿拿到锁了。
如果在C3之前,有个叫C4的客户端比C3快一步执行了上面的操作,那么C3拿到的时间戳是个未超时的值,这时,C3没有如期获得锁,需要再次等待或重试。留意一下,尽管C3没拿到锁,但它改写了C4设置的锁的超时值,不过这一点非常微小的误差带来的影响可以忽略不计。
为了让分布式锁的算法更稳键些,持有锁的客户端在解锁之前应该再检查一次自己的锁是否已经超时,再去做DEL操作,因为可能客户端因为某个耗时的操作而挂起,操作完的时候锁因为超时已经被别人获得,这时就不必解锁了
参考博客:
https://www.oschina.net/question/tag/twemproxy //twemproxy开源中国社区
https://www.cnblogs.com/lihaoyang/p/6906444.html //gem安装redis官方集群版
https://redis.io/commands/cluster-nodes //官方redis集群相关命令
https://blog.csdn.net/huwei2003/article/details/50973967 //redis-trib.rb详解
https://piaosanlang.gitbooks.io/redis/content/redisfen-bu-shi-suo-shi-xian.html
https://www.cnblogs.com/haoxinyue/p/redis.html //twitter版redis集群
https://blog.csdn.net/shmiluwei/article/details/51958359 //Codis安装和配置