作者 无涯
Requests:让HTTP服务人类!
OK,开始愉快的学习requests库吧,在python的标准库中,虽然提供了urllib,utllib2,httplib,但是做接口测试,requests真心好,正如官方说的,
“让HTTP服务人类”,一言以蔽之,说明一切,关于它的方法论这里不是讨论的重点,重点是我们要开始学习它。
安装request库的方式非常简单,安装命令为:
pip install requests
这样就会自动下载并且按照成功,进入到python的命令行模式下,如果可以导入request,说明requests库已经安装好
在HTTP的请求中,我们知道,最常使用的分别有GET,PUT,DELETE,POST,通过request库也是可以实现的,见如下的代码:
#!/usr/bin/env python #coding:utf-8 import requests requests.get('https://github.com/timeline.json') requests.put('http://httpbin.org/put') requests.post('http://httpbin.org/post') requests.delete('http://httpbin/ddelete')
事实上,每一个请求对应的参数是不同的,在这里我们有必要对每个请求的参数来了解并学习,先来看GET请求的参数,见源码部分:
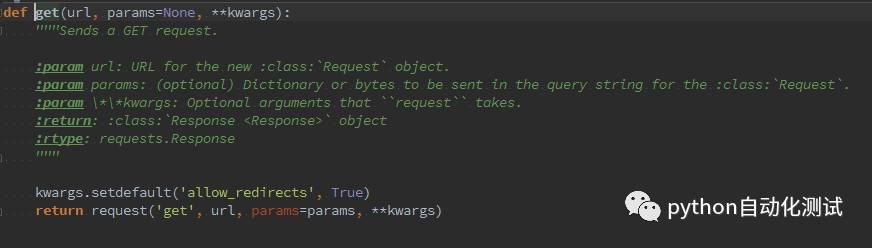
GET请求中,第一个参数是url,第二个请求是params,第三个参数是字典,比如我们实现在百度阅读搜索《selenium-python自动化测试》,实现这样的一个过程请求的 url为:
http://yuedu.baidu.com/ebook/3c0077aaa32d7375a41780bb?_searchquery=selenium-python%D7%D4%B6%AF%BB%AF%B2%E2%CA%D4
那么通过代码实现的方式为:
#!/usr/bin/env python #coding:utf-8 import requests r=requests.get(url='http://yuedu.baidu.com/ebook/3c0077aaa32d7375a41780bb',
params={'_searchquery':'selenium-python%D7%D4%B6%AF%BB%AF%B2%E2%CA%D4'}) print r.url
我们看请求的URL,见执行后的截图:

在GET请求中,我们把params的参数成为URL参数,也就是在URL中传递参数,事实上,在每一个GET的请求过程中,
得看具体的请求过程。接下来我们来看POST请求的参数,见该部分的源码截图:
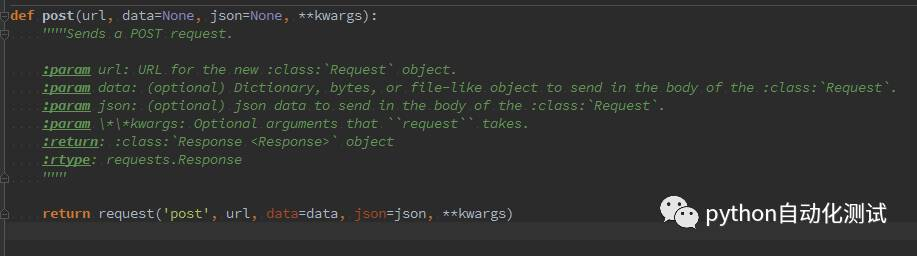
我们可以看到,在POST请求中,参数是URL,data,json以及字典,data其实就是以表单形式的数据,或者说我们只需要把一个字典给data作为参数来传递
来看这样的一个请求,请求的URL为:http://m.cyw.com/index.php?m=api&c=cookie&a=setcity,参数是城市的ID,然后返回这个城市,来看这样的一个POST请求,见实现的代码:
#!/usr/bin/env python #coding:utf-8 import requests r=requests.post(url='http://m.cyw.com/index.phpm=api&c=cookie&a=setcity',data={'cityId':438}) print r.json()
见返回的json数据,见截图:
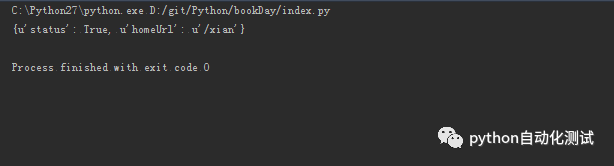
事实上,在一个post请求中,这是一个简单的请求,在工作的时候,很多时候是登录成功后,返回一个token,然后后面的每一个请求都带这个参数token去请求,
也就是说,在接口自动化测试中,首先要做的就是登录获取token这个参数,下来后面的请求把获取的这个参数token带上去请求或者操作系统的其他业务,
下面来看实现这样的一个过程代码,实现的思路把登录写成一个方法,然后把token返回,再做下一个请求的时候,把token当作参数来传递,具体实现见如下的代码:
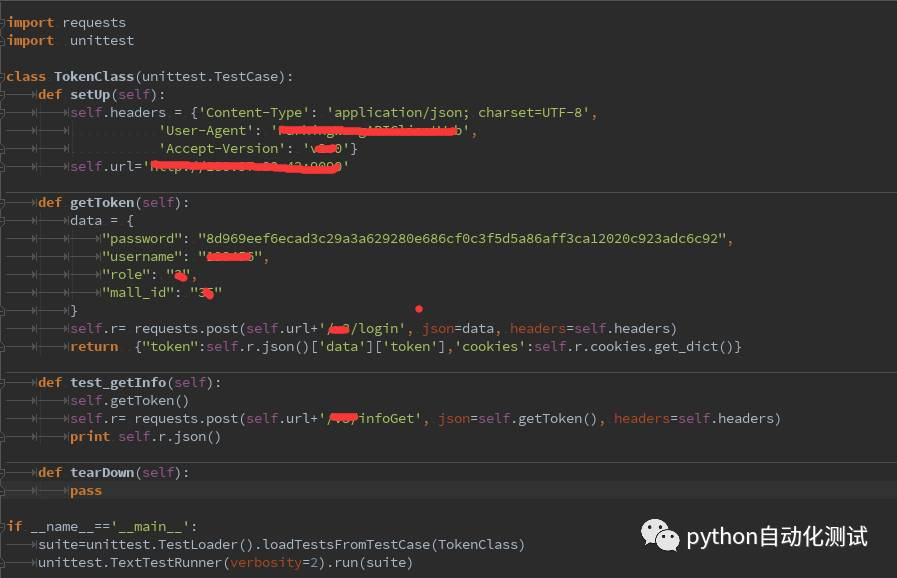
注释:如上的代码部分被红色的掩盖,希望理解,再如上的代码中,我们可以看到,登录成功后,返回了token,然后在执行其他接口的时候,
直接把返回的token当作是参数来处理,但是有一点是必须得注意的,必须先登录,再执行登录后的接口,要不会提示错误的。
使用requests发送一个请求后,我们可以获取这个请求的响应内容,HTTP的状态码,以及URL,我们来看这样的一个过程,
比如请求bing,我们获取text,stats_code,url和headers,见实现的代码:
#!/usr/bin/env python #coding:utf-8 import requests r=requests.get('http://www.bing.com') print u'HTTP状态码:',r.status_code print u'请求的URL:',r.url print u'获取Headers:',r.headers print u'响应内容:',r.text
见该代码执行后的结果:

在一个POST的请求中,很多时候,我们需要把获取的响应内容,进行反序列化成json字符串内容,来断言该接口是正确的还是错误的,
我们不可能对所有获取的响应内容来进行做断言,这样是很不明智的,我们只会截取关键的信息来做断言,见下面一个网站的登录请求,
以及获取的响应内容经过反序列化后的内容,见实现的源码:
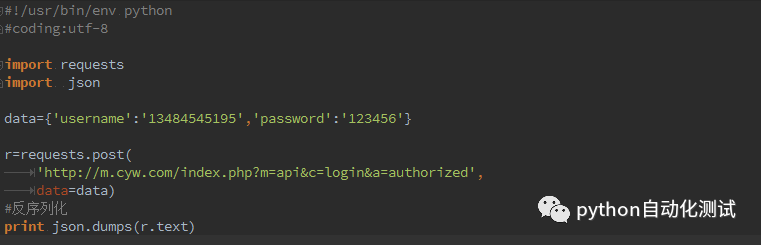
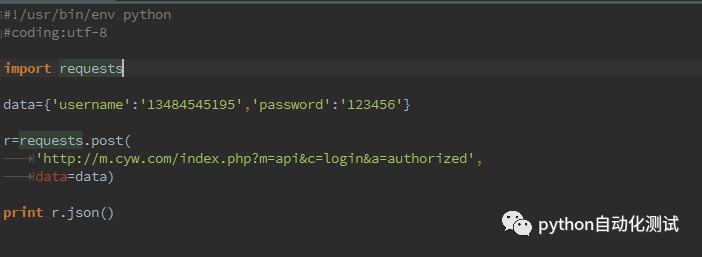
事实上,经过反序列化很麻烦的,在requests库中有一个内置的JSON解码器,来帮助我们处理JSON数据,我们重构下刚才的代码,可以精简反序列化的过程,见代码:
什么是请求头,或者说在一个HTTP的请求中,headers充当了什么角色和它有什么作用,在https://en.wikipedia.org/wiki/Header_(computing)有很详细的解释,
感兴趣的同学可以看下,headers分为二部分,一部分是request headers,另外部分是response headers,见如下的截图:
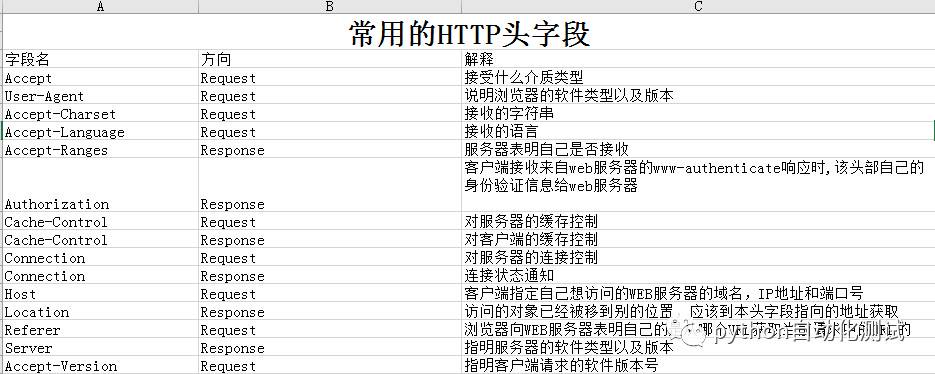
Headers部分详细的信息可以见:
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers