最近针对NLP的人机对话系统方向作了学习,首先从底层技术NLP理解其工作原理,再了解基本的智能搜索、对话交互、问答匹配技术,最后体验了chatbot的一些开放平台进而抽象其框架和功能等,从而整理出此篇学习笔记。
一、人机对话系统概述
1.对话交互的终极目标
信息交互方式的演进过程(图片from百度云智)
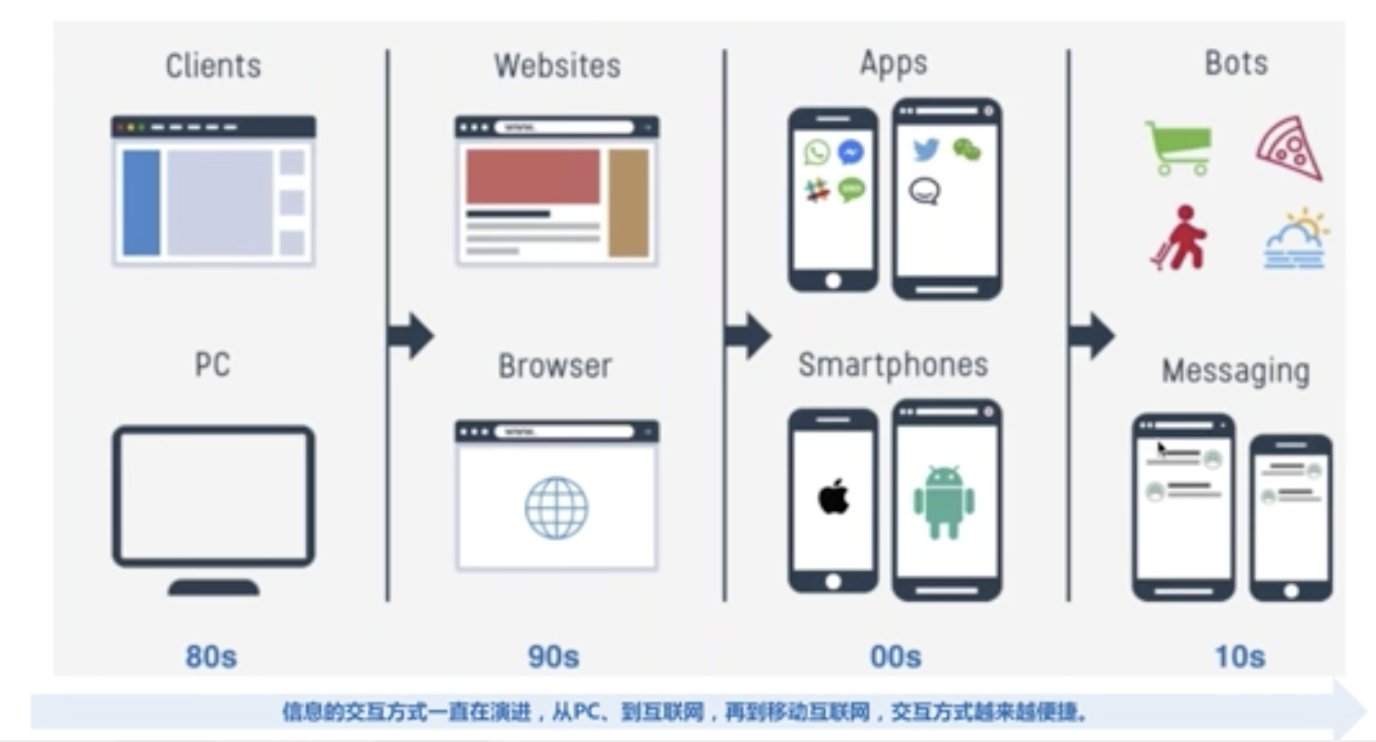
新一代的人机对话的交流方式是人习惯的自然语言交流方式(包括智能语伴、语音和手写等,甚至包括人的表情、手势、步态等)
对话交互的终极目标:让人与机器的交流,就像与人交流一样自然。
2.人机对话系统解释
人机对话系统,又称chatbot系统。引用微软亚洲研究院副院长周明老师对于“对话系统”的解释:
对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。同时,为了体现个性化,要开发用户画像以及基于用户画像的个性化回复。
二、人机对话系统发展历程和应用场景
1.人机对话系统发展历程
第一阶段:2011年10月份在 iphone 手机上语音助手Siri,开启了聊天机器人的大门,教育了用户和市场。Siri其实是一个面向特定任务的对话系统,对接了很多本地服务(如通讯录、音乐播放等)以及Web服务(如订餐、订票和导航等)但当时的Siri主要是调戏用的,听得见但听不懂,没有实用性。
第二阶段:2014年5月,微软做了一款聊天机器人-微软小冰,主要用于闲聊。是一个基于搜索的回复检索系统,通过各种基于深度学习的语义匹配算法,从海量的问答对语料中返回最佳回复。
第三阶段:2014年11月份,Amazon 推出了一款跨时代的智能音响产品 Echo,Echo 是一款专注于任务型的机器人,即专注于在特定场景做一些具体的事。正因为 Echo 在国外非常火,国内的巨头也纷纷进行了部署。也就迎来了人机对话的第四阶段。
第四阶段:2017年天猫精灵发布,2018年3月小度(带屏)发布,2018年4月14号的腾讯叮当的发布。特色是集合了闲聊、娱乐、技能/任务的功能,提升了用户体验。
发展历程参考物灵科技姜博士的分享的人机对话系统解析
2.对话系统产品形态和应用场景

如上图所示,对话系统目前已应用在各类设备端,包括的场景有:智能音箱、智能电视、智能冰箱、智能故事机、小家电、家庭机器人、智能手机语音助手\app内语音助手、车载、可穿戴设备等。
一些chatbot产品
苹果Siri、微软小冰和小娜、IBM Watson系统、Facebook Messenger、亚马逊Alexa的Echo智能音箱、Google Assistant、百度度秘、搜狗旺仔、阿里小蜜、科大讯飞灵犀、叮咚智能音箱、小i机器人等。
3.对话系统的技能/服务
在对话系统可实现的技能服务方面,百度DuerOS官方称可提供250多项能力,其中包括不同场景下实现指令控制、信息查询、知识应用、寻址导航、日常聊天、智能提醒和多种O2O生活服务。
为了便于对外输出服务,一些开放平台还会对某些常见业务场景的对话逻辑进行封装,如DuerOS、腾讯叮当都提供了智能家居、内容播报等技能。开发者通过预置指令就可以实现此技能。
当前的对话交互与真正的用户期望还是有明显距离的,对话交互覆盖的领域比较受限,常用的可能是服务可能是音乐、地图、导航、百科问答类。
三、关键技术与知名厂家
人机对话系统关键技术主要有:自然语言处理技术、语音技术、知识构建和自学习能力、大数据处理和挖掘等前沿技术领域。以下是语音、语义技术的模块和部分知名厂家
1.自然语言处理NLP
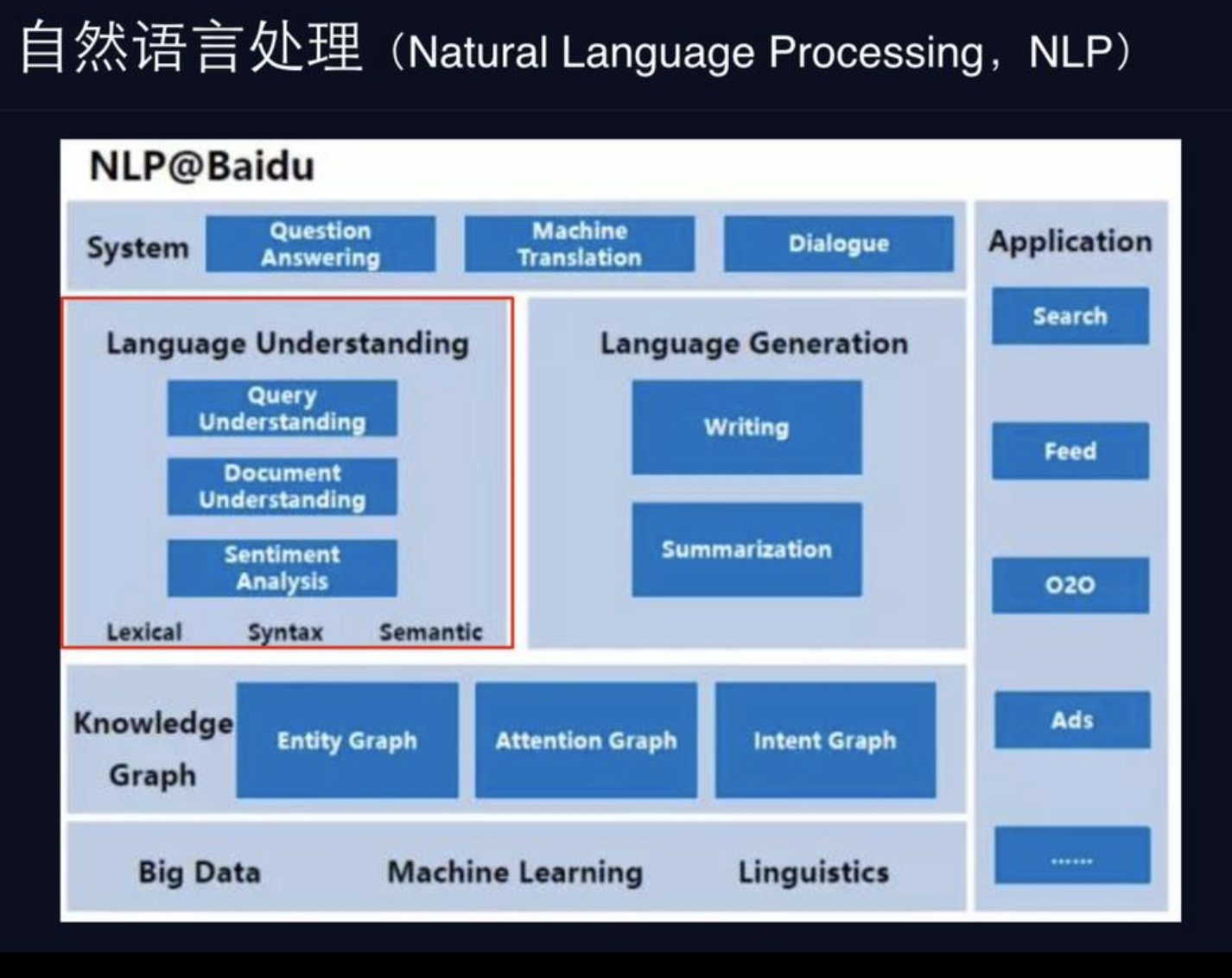
其中,自然语言理解NLU是NLP的一部分。NLU包含:
- 词性分析(分词、命名名体识别、词性分析)
- 句法分析(句法结构、依存句法分析)
- 语义分析(词义消歧、语义角色标注、共指消解)
- 情感分析
- Query理解
- 文本理解等
NLP的难点:
- 多样性:同个意思可以有多种表达方式
- 歧义性:在缺少语境约束的情况下,语言有很大的歧义
- 鲁棒性:语言在输入的过程中,尤其是经过语音识别转录过来的文本,存在多字、少字、错字、噪音、不连贯等问题
- 知识依赖:语言连接着世界知识。
- 语境:语言的上下文
知名厂商:BAT、搜狗、网易、竹间智能、追一科技、三角兽等
2.语音技术
包含模块:语音识别ASR、语音合成TTS、声纹识别等
知名厂商:讯飞、BAT、搜狗、云知声、声智科技等
四、对话系统的结构、核心流程及算法
1.对话系统的组成结构
对话交互框架如下图所示,其组成包含输入、输出、自然语言理解、对话管理、自然语言生成几大部分。同时,对话任务的完成离不开知识库。
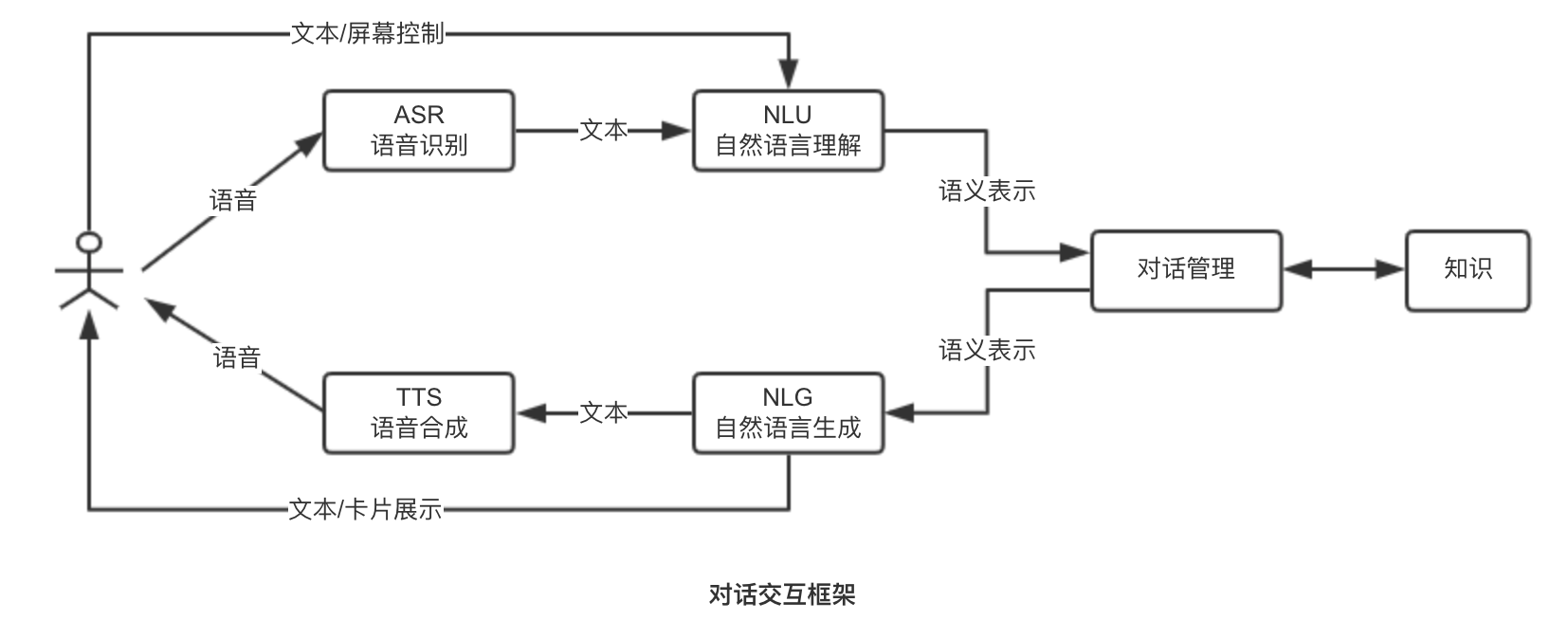
1)输入
根据用户表达请求的方式,输入大致可分为三种情况:
- 语音输入,这种情况系统需要做语音识别,将语音信号转成文本信息
- 文本输入,如使用app/公众号的文本输出
- 从设备端的屏幕控制输入
2)输出
当返回结果给用户时,会根据产品的形式,有以下三种情况:
- 语音输出,如智能音响
- 文本输出,如app直接返回文本
- 通过卡片展示,在有屏设备显示信息。如有屏的智能音响
3)自然语言理解
将识别出来的文本信息转换成机器可以理解的语义表示
4)对话管理
根据NLU模块输出的语义表示,执行对话状态的更新和追综,并根据一定策略选择相应的候选动作。
对话管理主要是针对多轮对话,比如第二轮对话是为了询问一个不知道的槽位。那么对话管理会发出一个询问槽位的指令。例如:“请帮我订一张北京到上海的机票”—>对话状态管理会引导填写“出发时间”信息。
5)自然语言生成
负责生成需要回复给用户的自然语言文本
2.核心流程
意图识别层
前面讲到自然语言理解是将文本信息转换成机器可以理解的语义表示。而语义表示常见方式是框架语义表示,使用领域Domain、意图Intent、槽位slots对语义进行结构化表示。如下图:

所以,语义表示包含:意图识别、填槽(或者称“参数抽取”)
1)意图识别
可以把它看作一个分类问题,实现算法有:
第一代:使用词袋模型BOW或 TF-IDF + Sklearn库中封装的一些分类器
第二代:使用DNN, 或“word2vec、glove加上CNN”,或RNN实现(相比DNN,CNN能更好建模短距离依赖关系,而RNN因其记忆功能能建模长距离的依赖关系)主要有:
- 用户点击日志+文档对方法+DNN
- ARC-1:Word embedding+CNN;
- ARC-2:把两个句子看作“图片”的两个维度+CNN
- RNN
第三代:Bert+Transformer (这是由谷歌在2018年提出,谷歌推出的BERT模型在11项NLP任务中夺得STOA结果,引爆了整个NLP界。Transformer是在Encoder-Decoder框架+注意力机制的基础上,在Encoder和Decoder的每层网络层之前都加了“自注意力层”。自注意力可以支持“指代识别” ,比RNN训练快)
2)参数抽取
可看作一个IOB序列标注问题,主流算法:Bi-LSTM + CRF。当语料数量比较少时,可以用余弦相似度+CRF
3)意图排序
针对上下文,要判断是否应该直接继承上文意图。可以把它看成是二分类问题。将新意图和上文意图送入一个线性二分类器,以判定是否继承上文。
处理流程
完成语言理解的语义表示和对照上下文后,接下来要决定采取什么样的动作。根据意图的业务场景,可以将处理流程分为3种类型:问答型、任务型、闲聊型。不同类型的实现方式,如下:
1)问答型
- 基于检索模型,通过预设问答对集合,再寻找用户问句语义最相近的标准问句,取出答案提供给用户。主流算法有TF-IDF和BM25算法。还可以在检索模型基础上,使用SMT/LDA等主题模型,可以度量词与词之间的语义相关性和词相似度。
- 基于无结构化的数据,采用搜索引擎方式,利用网页之间的链接关系。如Google的PageRank链接分析算法
- 对精准度要求比较高的,使用基于知识图谱的方法。构建知识图谱,将问句转为逻辑表达式,然后执行与之相应的查询语句,获得答案。
2)任务型
- 识别意图后,通过多轮对话交互,把用户的需求表达完整,得到结构化的完整信息。然后请求服务,完成后面回应。这个多轮对话除了澄清参数外,也有因为用户变更参数和变更意图的情况。
3)闲聊型
- 基于检索模型:预先通过爬虫爬取+人工审核/人工撰写的方式构建语料库,在预料库中找到最相似的问题,把答案返回给用户。
- 基于生成模型:如Seq2seq,实现了Encoder-Decoder框架并结合注意力机制的序列转换模型,生成答案。
五、人机对话开放平台体验
BAT、讯飞、思必驰、滴滴等公司,利用其积累的技术,为传统行业和领域输出AI服务。此次体验了百度的DuerOS、UNIT、腾讯微小云平台,主要的组成部分和搭建对话系统的流程基本类似,当然也存在些区别。以下对话系统开放开台的框架梳理和部分功能分析。
1.开放平台简述
开放平台包含两大部分:设备平台、技能平台。
简单来说,就是一端连接智能设备,一端连接技能服务。设备可以选择需要接入的技能,这些技能包含平台原有的技能和客户(开发者)自定义的技能。设备平台对接的用户类型主要有:硬件厂家、解决方案商或者是个人开发者。下面重点讲技能开放平台。
百度关于技能开放平台的概述:
技能开放平台是DuerOS为第三方开发者提供的一整套技能开发、测试、部署工具的开放平台。第三方开发者可以在平台上,通过可视化界面,简单、高效地开发各类DuerOS技能。通过可视化编辑界面,可以便捷设计技能的意图、词典等内部逻辑,开发对话式技能。
2.自定义技能
便于理解,可以把自定义技能看作开发一个app,技能下面的意图就好比实现一个个功能,而槽位就是功能下的参数,技能为了进行多轮对话,需要创建的对话模型就好比app的页面交互设计,只不过技能是用对话方式来做交互的。

同样,技能的开发过程,也可以类比与一个app软件从设计、开发、测试、发布的流程。

技能设计—>业务需求设计
技能开发—>功能实现
技能测试—>产品测试
技能发布—>产品发布
app发布成功后在“应用市场”,技能发布成功后在“技能商店”
3.技能交互流程
交互流程
以下是腾讯叮当的“查询天气”意图的交互流程示意图:

技能系统包含:用户、语音输入设备、开放平台系统、技能服务系统(如果是智能家居类的,还会包含设备云)
单轮对话与多轮对话
i.单轮对话
上面例子中是查询天气的意图,就是一个单轮对话。只有一问一答,问题可以用一句话来描述,且不依赖上下文。对话交互中大量的问题都是这样的单轮问答。依赖于一个知识库/问答对集合,机器人从知识库里检索相似的问题,给出答案。
ii.多轮对话
在与用户交互过程中,仅通过单轮对话很难完成用户的请求。大多数技能都需要通过不断与用户交互获取的用户请求的准确信息,完成用户的请求。比如需要考虑话语之间的相互关系,处理不完整的语义,处理中途更改意图等情况。
下面模拟用户表述不完整时,“查询天气”意图要进行两轮对话的交互流程:
开放平台收到用户的请求信息后,会根据技能的语义配置(或者交互模型)去解析用户的请求,然后将意图、相关槽位与槽位值等发送给技能服务平台,由技能服务平台进行业务逻辑处理后,向开放平台返回处理的结果和对话指令,开放平台会将结果转成语音发送给用户,如些进行多轮对话,直到会话结束。

一些说明:
上面的例子中,为了用户体验,其实城市的槽位可以通过定位默认填入用户所在地(如“深圳”),并返回“2019年9月9日深圳预计有中到大雨”,如果用户实际想查的是杭州,用户追问“杭州呢”,开放系统会联系上文,将城市槽位更新为杭州。然后由技能服务返回处理结果。
关于结果向用户输出的方式,要根据设备的形态,如带屏/不带屏,会有播放音频/视频/图片展示/文本等。
4.技能的语义设计
如上面交互流程所述,开放平台会根据技能开放平台的语义配置来解析用户请求。下面以百度DuerOS为例子,看技能的语义设计:
百度DuerOS把语义配置称为“交互模型”,包含三个主要部分:意图、词典、训练。
意图
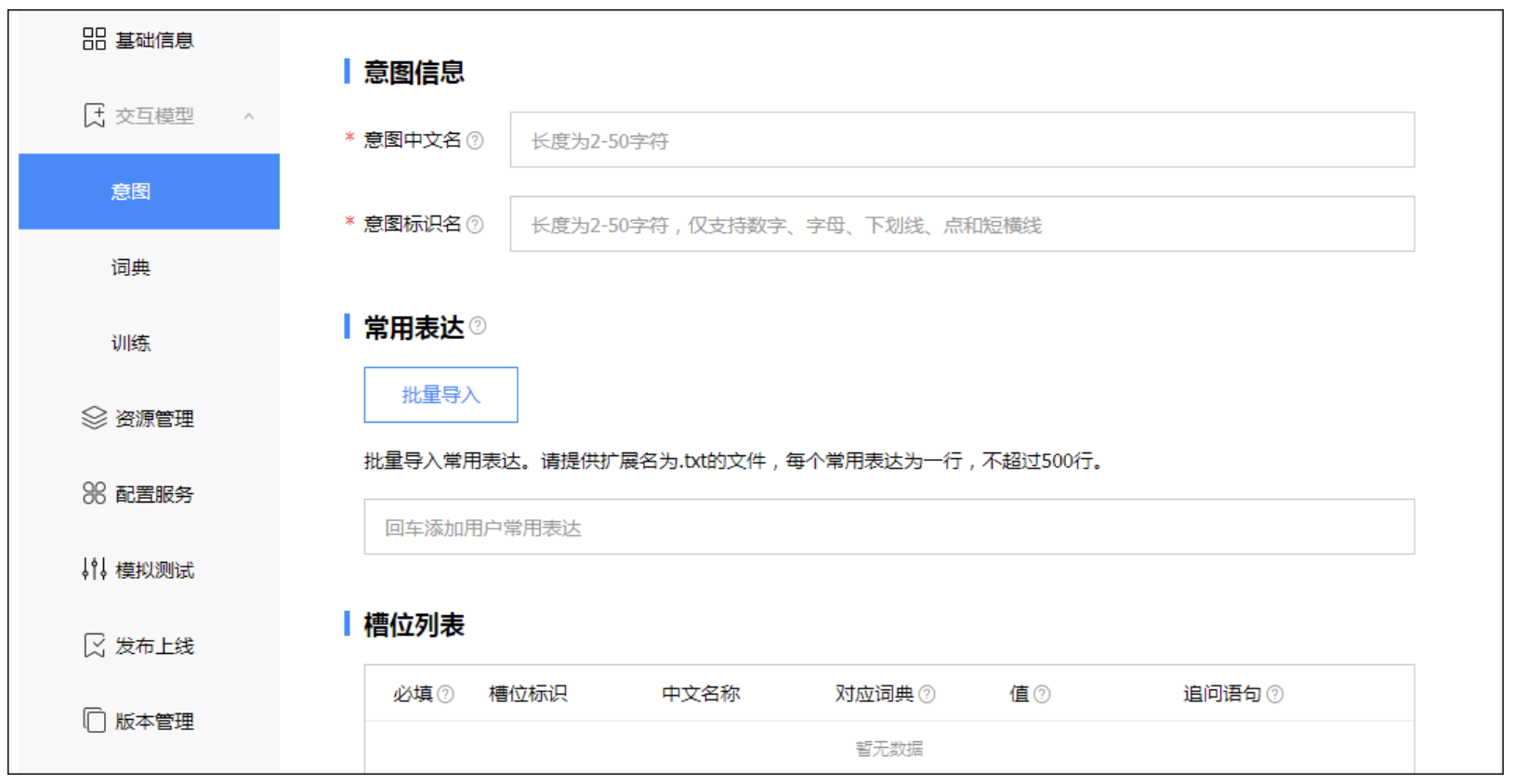
意图,指技能要满足的用户的请求或目的
常用表达,指用户表达意图时具体的样例
槽位,即意图的关键信息,或称“参数”。每个槽位都需要关联一个词典。
对话模型,通过建立对话模型,完成多轮对话的交互。
对话模型包含:
- 必填槽位的追问
- 槽位确认
- 意图确认
- 上下文语境
对话模型的实现:
1)必填槽位的追问语句,实现方式:
方法一:可视化窗口的槽位列表中填写追问语句,最多可以填写5个,设置多个时系统会随机返回1个。可以让机器人的回复更佳灵活,贴近真人对话。
方法二:通过代码指令进行
2)槽位确认,实现方式:通过指令对槽位进行确认
3)意图确认。两种方式实现:
方法一:技能通过委托指令完成意图确认
方法二:可视化窗口的意图确认中设置。一般引用本意图的槽位用“$槽位标识”,引用其他意图的槽位用“#语境.槽位标识”

4)上下文语境
多轮对话的发生场景分为:
- 机器为了收集用户更多的信息来完成一项具体的任务,主动引导用户回答问题,进而完成意图的槽位的识别。
- 用户更新已填写的槽位值。如查询天气,用户说“查询北京明天的天气”,技能查询并返回明天的天气。用户又说“那后天呢”,这时用户把槽位“日期”的值更新为后天,但意图、城市都没有变。
- 用户更换了意图。如订火车票,用户说“订明天从上海到北京的火车票”,技能返回结果,此时用户说“不是坐飞机吧”,此时意图更改为“订机票”,但上面的参数应该要继承下来。
通过上下文“语境”的设置,可以完成以上多轮对话的场景。

输出语境
- 任何自定义意图,都可以定义一个或者多个"输出语境”。不同输出语境标识名不同。
- 可以规定每个语境的生效轮数(关于生效轮数,目前DuerOS和叮当都暂时不可配置)
输入语境
- 每个意图都可以引用当前技能里定义的任意一个"输出语境",作为本意图的"输入语境"。
- 如果意图订阅了“输入语境”,那么这个意图的生效必须满足上文语境与订阅的相符,如果不相符,即使用户的请求与该意图的用户表达一致也不会触发。
- 意图可以订阅多个输入语境,这些语境是或的关系,只要满足其中一个语境即可。
词典
词典,有的开放平台也称为“实体库/实体”,约定了槽位/参数的取值范围。词与词之间的关系有:
- 同义关系:如“上海”、“魔都”与“上海”。“上海”和“魔都”是映射词典,也就是上海的别名是魔都
- 从属关系:如“苹果”、“梨”与“水果”。它们是枚举词典。 也就是水果是词典,苹果、梨是词表
- 具有关系:如“人”与“国籍”
- 含有关系:如“汽车”与“引擎” (具有和含有关系,可以用组合词典表示。如词典名称“sys.date-time”是日期与时间的组合词典。)
训练
百度DuerOS的训练流程如下图:

初始训练语料的来源
1)DuerOS:根据意图中定义的用户常见表达,从DuerOS的线上数据中找到相似的用户表达进行开发者标注。优点:能够帮开发者更容易地解决冷启动问题。
2)腾讯叮当:来自开发者在意图创建时添加的用户语料,和模拟测试时添加的测试语料集。还可以查看测试的结果详情:

人机对话系统的模型训练是一个持续提高意图识别、排序及参数识别的准召率的过程,除了初始模型的训练,持续增加已标注的正负例测试样本,在技能服务上线发布后,也会对线上的输出结果进行纠正和重新标注,将标注后的用户问句作为新的训练预料持续训练。
综上,为了实现多轮对话,具体配置流程如下:
1)配置意图和槽位,即用户的目的和问句的关键信息
2)配置系统回复的话术及输入、输出语境
3)对话样本的标注。即训练预料的标注,让系统理解用户问句的意图,关键信息和对应槽位在哪里。
4)训练验证。完成语义设计和数据标注后,即可触发训练以生效对话能力。(一般开放平台都有“快速体验”功能,这是系统自动生成的沙箱环境,提供给开发者使用)
5)效果优化。让机器不断学习,在平台中不断完成配置和标注的过程,提升机器人的对话能力。
六、对话系统的性能指标
不同类型的优化目标
| 类型 | 优化目标 |
|---|---|
| 任务型 | 用最短的对话轮次,满足用户需求 |
| 问答型 | 用最短的对话轮次,满足用户需求 |
| 闲聊型 | 聊得越久越好 |
单轮/多轮对话的评测指标
| 对话类型 | 评价指标 |
|---|---|
| 单轮对话 | 召回率=机器人能回答的问题数/问题总数 |
| - | 准确率=机器正确回答的问题数/问题总数 |
| - | 问题解决率=机器人成功解决的问题数/问题总数 |
| 多轮对话 | 任务完成率= 成功结束的多轮会话数/多轮会话总数 |
模型识别的测试指标(意图、槽位的识别)
| 模型 | 评价指标 |
|---|---|
| 语义识别 | 准确率=语义识别对的/模型总识别出来的 |
| - | 召回率=语义识别对的/人注出来总的 |
对于任务型、问答型,优先保证准确率,即可以不答,但要保证答对。任务型,如果涉及调用第三方服务进行订单生成、支付环节的,一定要做得到用户的最终确定。如果是智能客服类,需要考虑转人工的机制,并提供给用户反馈和打分机制。
七、总结
本次学习是从人机对话大框架出发,以便有较为全面的理解。但PM要真正落实到某个行业或者是细分应用场景时(比如细到传统金融的智能客服、驾驶员的语音助手等),除了技术预研/技术定型阶段需要的技术理解能力,还是要基于产品经理的底层能力:业务理解能力、用户体验、需求分析、产品设计、项目管理、人文逻辑等。
实践是最重要的,只有案例分析才有价值,空讲道理无益。