hadoop集群搭建前期准备:https://blog.csdn.net/weixin_41685388/article/details/102639751
1、集群搭建
集群分类:
单节点:
-
在一个节点上运行作业
伪分布式集群:
-
在一个节点里面启动了多个进程来模拟这种分布式的操作,只需要一个节点
完全分布式集群:
-
将进程完全分布到不同节点里去运行
高可用集群:
联邦集群:
2、完全分布式集群搭建:
-
1.下载hadoop软件包:http://hadoop.apache.org/
-
2.上传到服务器
-
在hadoop01的编辑器上alt + p 打开sftp,将压缩包hadoop-centos-6.7.tar.gz拖入hadoop01这台机上即可
-
3.解包
-
/opt/hadoop_2_7_7/ #解包目录,在/opt目录下创建sudo mkdir hadoop2x子目录
-
注意配置当前用户的高级权限:vi /etc/sudoers (hadoop ALL=(ALL) ALL),
-
这里我们在上一节准备工作时已经做了,没做的需要去配置,然后执行命令:
tar -zxvf hadoop-2.7.7-centos-6.7.tar.gz -C /opt/hadoop2x
-
以上解包后,因为/opt是在root用户权限下执行的,所以操作时很多时候需要加sudo才能执行,不妨删除hadoop2x/,直接解压到用户自己的家目录下cd /home/hadoop执行 tar -zxvf hadoop-2.7.7-centos-6.7.tar.gz
-
4.了解目录结果
-
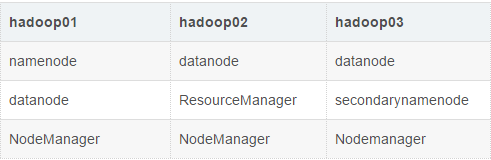
[hadoop@hadoop01 ~]$ cd /opt/hadoop2x/ [hadoop@hadoop01 hadoop2x]$ ll total 4 drwxr-xr-x. 9 root root 4096 Oct 30 2018 hadoop-2.7.7 [hadoop@hadoop01 hadoop2x]$ cd ./hadoop-2.7.7 [hadoop@hadoop01 hadoop-2.7.7]$ ll total 136 drwxr-xr-x. 2 root root 4096 Oct 30 2018 bin drwxr-xr-x. 3 root root 4096 Oct 30 2018 etc drwxr-xr-x. 2 root root 4096 Oct 30 2018 include drwxr-xr-x. 3 root root 4096 Oct 30 2018 lib drwxr-xr-x. 2 root root 4096 Oct 30 2018 libexec -rw-r--r--. 1 root root 86424 Oct 30 2018 LICENSE.txt -rw-r--r--. 1 root root 14978 Oct 30 2018 NOTICE.txt -rw-r--r--. 1 root root 1366 Oct 30 2018 README.txt drwxr-xr-x. 2 root root 4096 Oct 30 2018 sbin drwxr-xr-x. 4 root root 4096 Oct 30 2018 share #bin: 可执行文件(操作命令 hdfs...) #sbin: 可执行文件(集群启动关闭,负载均衡...) #etc: 配置文件 #share: 共享文件(common/hdfs/mapreduce等jar)5.进程规划
-

6.配置
-
配置前案例:以下内容先只对hadoop01机器操作(单节点模式),并且是安照 /opt/hadoop2x/解包目录下操作的。
-
vim hadoop-env.sh #整个hadoop的环境(cd /opt/hadoop2x/hadoop/hadoop-2.7.7/hadoop/目录下)
整个hadoop的环境,hadoop进程是jvm进程,配置jdk的环境变量 export JAVA_HOME=/opt/jdk1.8.0_144 运行一个mr示例: cd /opt/hadoop2x/hadoop-2.7.7/ #切换到解压包的文件夹下 sudo mkdir input_test #新建一个用于测试的文件夹 cd input_test/ #切换到input_test/目录 sudo vim wordcount.txt #创建一个新的文件,并写入一些单词,并且出现重复单词 cd .. #切换到上层hadoop-2.7.7/目录下 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar #查看jar有哪些可执行的操作 sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input_test/ output_test #wordcount单词计数统计,统计input_test/文件夹下面的内容,放到output_test文件目录下去 cd output_test/ #切换到cd output_test/目录下 ll #查看生成的文件 cat part-r-00000 #查看结果 -
以上操作虽然可以执行,但很多时候需要启动高级用户权限,非常麻烦,所以建议直接解包在当前家目录下,为了不重复配置,将/opt/hadoop2x删除(cd /opt目录下执行sudo rm -rf hadoop2x),cd /home/hadoop到家目录下执行tar -zxvf hadoop-2.7.7-centos-6.7.tar.gz,
(1)、vim hadoop-env.sh #整个hadoop的环境(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )

-
整个hadoop的环境,hadoop进程是jvm进程,配置jdk的环境变量 export JAVA_HOME=/opt/jdk1.8.0_144
(2)、vim core-site.xml #核心位置配置(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )
-
默认配置官网说明地址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml

#默认的文件系统,默认值(file:///本地文件系统) -
#hdfs://ip:port hdfs集群的入口地址(namenode:客户端的请求和响应)
-
#1.使用分布式的文件系统 #2.namenode所在的节点为hadoop01
-
#3.hdfs集群的访问路径: hdfs://hadoop01:9000
-
<property>
-
<name>fs.defaultFS</name>
-
<value>hdfs://hadoop01:9000</value>
-
</property>
-
#临时文件的存储目录:
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>/home/hadoop/hadoopdata</value>
-
</property>
-
(3)、vim hdfs-site.xml #分布式文件系统配置(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )
默认配置官网说明地址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml

-
dfs.replication: 副本数(默认3个副本) #按照默认
-
dfs.blocksize:每个块的大小(1.x:64m, 2.x:128m) #按照默认128兆
-
namenode的元数据存储的目录:
-
<property>
-
<name>dfs.namenode.name.dir</name>
-
<value>/home/hadoop/hadoopdata/name</value>
-
</property>
-
datanode的block信息存储的目录:
-
<property>
-
<name>dfs.datanode.data.dir</name>
-
<value>/home/hadoop/hadoopdata/data</value>
-
</property>
-
secondarynamenode的节点配置:
-
<property>
-
<name>dfs.secondary.http.address</name>
-
<value>hadoop03:50090</value>
-
</property>
-
(4)、vim mapred-site.xml #分布式运算编程框架配置(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )
-
cp mapred-site.xml.template mapred-site.xml #由于没有mapred-site.xml文件,先复制一个,再配置
-
mapreduce作业运行的平台配置:vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> -

-
(5)、vim yarn-site.xml #运算资源调度系统配置(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )
-

<property> <name>yarn.resourcemanager.hostname</name> <value>hdp02</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
(6)、vim slaves #用于配置dn和nm(cd /home/hadoop/hadoop-2.7.7/etc/hadoop目录下 )
-

主从架构的集群,一主多从。 namenode/ResourceManager --> master(主) datanode/NodeMnager --> slave(从,所以3台机都要配置上) hadoop01 hadoop02 hadoop03 -
7.环境变量的配置
sudo vim /etc/profile #配置环境变量
或者在当前当前用户下配置也可以:
vim /home/hadoop/.bashrc 或者vim /home/hadoop/.bash_profile
以上三个任选一个位置,如:vim /home/hadoop/.bash_profile

export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
最后重启一下文件:source /home/hadoop/.bash_profile
![]()

8.发送到其他节点
scp -r hadoop-2.7.7 hadoop@hadoop02:~/
scp -r .bash_profile hadoop@hadoop02:~/
scp -r hadoop-2.7.7 hadoop@hadoop03:~/
scp -r .bash_profile hadoop@hadoop03:~/
统一执行:source /home/hadoop/.bash_profile
-
9.hdfs集群(namenode)格式化
-
在 HDFS 主节点上执行命令进行初始化 namenode
-
hdfs namenode -format # (只能格式化一次)
-
10.启动集群
-
1.逐个进程启动
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
yarn-daemon.sh start/stop ResourceManager/NodeManager
2.整个集群启动(涉及到通信,ssh免密登录)
start-dfs.sh/stop-dfs.sh
start-yarn.sh/stop-yarn.sh #(必须在rm节点启动)所以这里在hadoop02里启动
3.全部启动
start-all.sh/stop-all.sh -
注意:如果启动错误,去查看日志
-

-
11.成功检测
-
1.jps #查看启动进程
2.利用图形界面
hdfs: http://hadoop01:50070
yarn: http://hadoop02:8088
3.运行任务 -
在hadoop01机上创建一个文件mkdir input
在input/目录下vim wordcount.txt 随便写入几行内容,保存并退出
-
hdfs: hdfs dfs -copyFromLocal input/ / 或者hdfs dfs -copyFromLocal input/ hdfs://hadoop01:9000/
-
hdfs dfs -ls / 或者http://hadoop01:50070 #查询一下看是否上传
-
yarn: hadoop jar hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
-
hdfs dfs -ls / 或者 hdfs dfs -ls hdfs://hadoop01:9000/ 查看输出的内容
-
#wordcount单词计数统计,统计input/文件夹下面的内容,放到output文件目录下去