Spark工作原理入门
文章目录
1.功能概要
基本描述
Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
对于Spark这样的分布式计算系统,任务会分发到多台机器上执行,榨干有限的集群资源来实现快速并行计算达到高效快速,Spark优先考虑使用各节点的内存作为存储,当内存不足时都会考虑使用磁盘,这极大地减少了磁盘I/O,提供了任务执行的效率,使得Spark适用于实时计算、迭代计算、流式计算等场景。在实际场景中,有些Task是存储密集型的,有些则是计算密集型的,所以有时候会造成存储空间很空闲,而计算空间的资源又很紧张。Spark的内存存储空间与执行存储空间之间的边界可以是”软”边界,因此资源紧张的一方可以借用另一方的空间,这即可以有效利用资源,又可以提高Task的执行效率
运用场景
主要应用于处理大数据相关的业务
从大数据处理需求来看,大数据的业务大概可以分为以下三类:
1、复杂的批量数据处理,通常的时间跨度在数十分钟到数小时之间;
2、基于历史数据的交互式查询,通常的时间跨度在数十秒到数分钟之间;
3、基于实时数据流的数据处理,通常的时间跨度在数百毫秒到数秒之间。
实际使用
1.生成一些海量数据的报表
2.建立机器学习相关的模型
2.模块组成
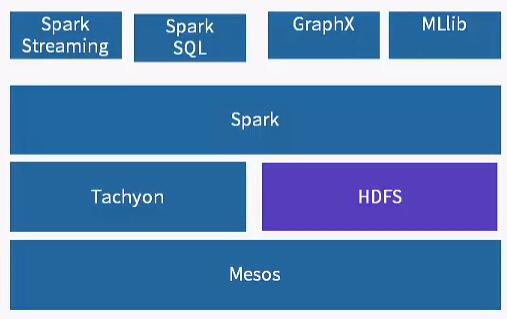
HDFS
分布式文件系统,像百度云,阿里云等就是个文件存储系统,HDFS目的不单单是用来存储文件这么简单,它还涉及分布式计算。
MLlib
Spark里的机器学习库。它的目标是使实用的机器学习算法可扩展并容易使用。它提供如下工具:
1.机器学习算法:常规机器学习算法包括分类、回归、聚类和协同过滤。
2.特征工程:特征提取、特征转换、特征选择以及降维。
3.管道:构造、评估和调整的管道的工具。
4.存储:保存和加载算法、模型及管道
5.实用工具:线性代数,统计,数据处理等。
Mesos
Mesos是一个资源管理框架。用户可以在其中插件式地运行计算框架的任务。Mesos会对资源和任务进行隔离,并实现高效的资源任务调度。可以通过队列进行分配,管理同时运行在集群种的多个服务,可根据不同类型的应用程序压力情况,调整对应的资源使用量,实现资源弹性管理。
Tachyon
Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,积极地使用内存,Tachyon的吞吐量要比HDFS高300多倍。Tachyon都是在内存中处理缓存文件,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件
GraphX
GraphX是图像处理模块,基于BSP模型(整体同步并行计算模型),在Spark之上封装类似Pregel的接口,进行大规模同步全局的图计算,尤其是当用户进行多轮迭代时,基于Spark内存计算的优势尤为明显。
Spark SQL
Spark SQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark。Spark SQL使用Catalyst做查询解析和优化器,并在底层使用Spark作为执行引擎实现SQL的Operator。用户可以在Spark上直接书写SQL,相当于为Spark扩充了一套SQL算子,这无疑更加丰富了Spark的算子和功能,同时Spark SQL不断兼容不同的持久化存储(如HDFS、Hive等),为其发展奠定广阔的空间。
Spark Streaming
Spark Streaming通过将流数据按指定时间片累积为RDD,然后将每个RDD进行批处理,进而实现大规模的流数据处理。其吞吐量能够超越现有主流流处理框架Storm,并提供丰富的API用于流数据计算。
3.Spark核心对象RDD的处理
什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
RDD的处理流程
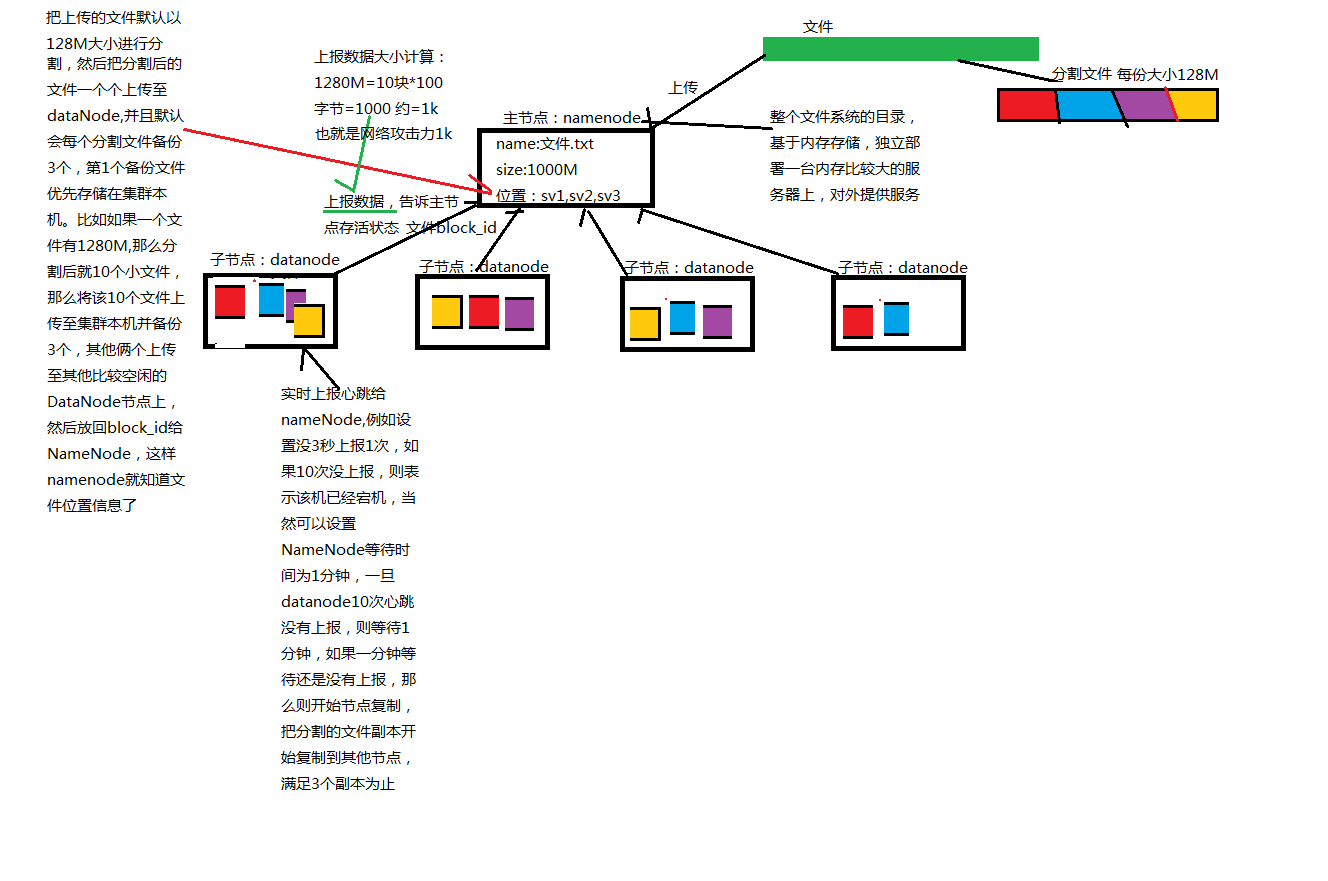
如下图,输入3个hello.txt然后对其进行单词切分统计并输出
分为五步:
1.输入 (input) 通过HDFS将不同设备上的同一文件输入到处理设备上
2.拆分 (split) 将内容按照一定格式拆分切片
3.映射 (map) 映射函数用来把一组键值对映射成一组新的键值对
4.缩减 (reduce) 将不同切片的类型合并缩减
5.输出 (output) 将得到结果输出
RDD的运算
1.变换(Transformations):
特点: 懒执行,变换只是一些指令集并不会去马上执行,需要等到有Actions操作的时候才会真正的据算结果
比如: map() flatMap() groupByKey reduceByKey
2.操作(Actions):
特点: 立即执行
比如: count() take() collect() top() first()
4.核心逻辑架构
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver和Worker是两个重要角色。Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。
Spark的任务提交流程
Spark的整体流程为:Client提交应用,Master进程找到一个Worker进程启动Driver,Driver向Master或者资源管理器申请资源,之后将应用转化为DAG(有向无环图),再由DAGScheduler将DAG转化为Stage提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行。
名词解释
Driver
运行Application的main()函数并创建SparkContext。
SparkContext
SparkContext是Spark的入口,整个应用的上下文,控制应用的生命周期。
RDD
Spark的基本计算单元,一组RDD可形成执行的有向无环图DAG
DAG Scheduler
根据作业(Job)把DAG划分为Stage,并提交Stage给TaskScheduler。
TaskScheduler
将任务(Task)分发给Executor执行。
Worker
从节点,负责控制计算节点,启动Executor,负责计算节点的控制。
Executor
执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
划分Stage
当某个操作触发计算,向DAGScheduler提交作业时,DAGScheduler需要从RDD依赖链最末端的RDD出发,遍历整个RDD依赖链,划分Stage任务阶段,并决定各个Stage之间的依赖关系。Stage的划分是以ShuffleDependency(派发依赖)为依据的,也就是说当某个RDD的运算需要将数据进行Shuffle时,这个包含了Shuffle依赖关系的RDD将被用来作为输入信息,构建一个新的Stage,由此为依据划分 Stage,可以确保有依赖关系的数据能够按照正确的顺序得到处理和运算。
Spark运行逻辑
在Spark应用中,整个执行流程在逻辑上会形成有向无环图(DAG)Action操作触发之后,将所有累积的算子形成一个有向无环图,然后由调度器调度该图上的任务进行运算。Spark根据RDD之间不同的依赖关系切分形成不同的阶段(Stage),一个阶段包含一系列函数执行流水线。图中的A、B、C、D、E、F分别代表不同的RDD,RDD内的方框代表分区。数据从HDFS输入Spark,形成RDD A和RDD C,RDD C上执行map操作,转换为RDD D,RDD B和RDD E执行join操作,转换为F,而在B和E连接转化为F的过程中又会执行分发,最后RDD F通过函数saveAsSequenceFile输出并保存到HDFS中。
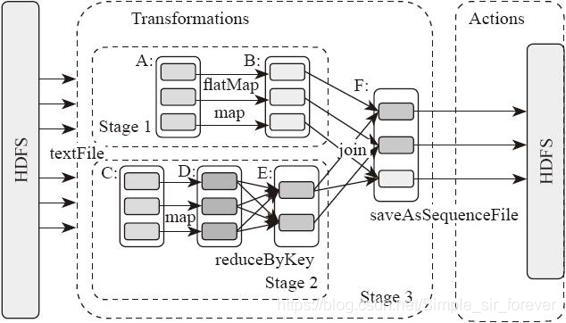
DagScheduler 和 TaskScheduler 的任务交接
spark 调度器分为两个部分, 一个是 DagScheduler, 一个是 TaskScheduler, DagScheduler 主要是用来把一个 Job 根据宽依赖划分为多个Stage(阶段),
对于划分出来的每个 stage 都抽象为一个 TaskSet任务集 交给 TaskScheduler 来进行进一步的调度运行,
我们用户编程使用的 RDD, 每个 RDD都有一个分区数, 这个分区数目创建 RDD 的时候有一个初始值,运行过程中,我们可以看到, 一个 task 对应一个 stage 里面一个分区数据的处理任务而一个 stage 里面 所有分区的任务集合 就被包装为一个 TaskSet 交给了 TaskScheduler,
5.测试用例
我把今天BBCnews世界头版的8条新闻文本用pyspark进行分词统计
from pyspark import SparkContext
from pyspark import SparkConf
import os
import warnings
# 创建SparkConf和SparkContext
wordbank=['and', 'is', 'after', 'i', 'a', '', 'but', 'the', 'it', 'why', 'being', 'for', 'when', 'so','with','lot','those','than','has','had','who'
,'mr', "how", "he", 'if','what',"even","in",'of','to','that','on','was','or','her','from','be','by','at','can','have','are','been','this','as','-','an']
if __name__ == '__main__':
#创建SparkContext Master是连接到的集群的URL AppName是工作名称
conf = SparkConf().setMaster("local").setAppName("wordcount")
sc = SparkContext(conf=conf)
#导入文件
file = open(url, "r")
text = file.read()
#拆分切片
#处理掉写常见的特色字符
text = text.replace('\n', '')
text = text.replace('.', '')
text = text.replace(',', '')
text = text.replace('@', '')
text = text.replace('*', '')
text = text.replace('"', '')
text = text.replace('–', '')
text = text.replace('/', '')
text = text.replace('“', '')
text = text.replace('’', '')
text = text.replace('\'', '')
text = text.replace('•', '')
text = text.replace('…', '')
text = text.replace('✔', '')
text = text.replace('!', '')
words = text.split(" ")
#映射生成
rdd = sc.parallelize(words)
res_rdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 并不会立马生效,先生成DAG
# 下面映射生效,将rdd转为collection并打印输出
res_rdd_coll = res_rdd.collect()1
result = sorted(res_rdd_coll, key=lambda x: x[1], reverse=False)
for text in result:
word = text[0]
if word.lower() not in wordbank:
if word[0]>='A' and word[0]<="Z":
print(text)
# 结束
sc.stop()
('Monday', 5)
('Commons', 5)
('Grindr', 6)
('King', 6)
('Sineenat', 6)
('Withdrawal', 6)
('Agreement', 6)
('Trump', 6)特朗普
('Gantz', 6)
('October', 7)
('UK', 7)
('MPs', 8)
('Netanyahu', 9)内塔尼亚胡
('Brexit', 10)英国退欧
('EU', 10)
('K-pop', 10)一个韩国组合
('Morales', 10)
('BTS', 11)美国运输统计局
('US', 15)
6.总结
因为spark是基于内存的计算框架尽管高效但是spark处理数据如果数据过大,OOM内存溢出等等,spark的程序就无法运行了,直接就会报错挂掉了。MapReduce利用磁盘的高I/O操作实现并行计算确实在处理海量数据是无法取代的
Spark利用RDD结构提升了容错性能。RDD是一个包含诸多元素、被划分到不同节点上进行并行处理的数据集合,可以将RDD持久化到内存中,这样就可以有效地在并行操作中复用,在节点发生错误时RDD也可以根据其Lineage自动重新计算恢复。
总的来说spark是一个非常高效好用的大数据计算框架,在处理海量数据报表统计,大计算量的时候拥有非常明显的优势。
mac配置 spark环境链接