数据结构
pg_interval_t{
vector<int32_t> up, acting;//当前pg_interval的up和acting的osd列表
epoch_t first, last;//该interval的起始和结束epoch
bool maybe_went_rw;//在这个阶段是否可能有数据读写
int32_t primary;//主osd
int32_t up_primary;//up状态的主osd
}
PriorSet {
Const bool ec_pool;//是否是ec pool
set<pg_shard_t> probe; //需要probe的osd
set<int> down; //当前是down的osd
map<int, epoch_t> blocked_by; //导致pg_down为true的osd及对应osdmap的epoch
bool pg_down; //pg是否为down
boost::scoped_ptr<PGBackend::IsRecoverablePredicate> pcontdec;//判断pg是否可恢复的函数指针
}
pg_info_t {
spg_t pgid;//pgid和shardid信息
eversion_t last_update; // last object version applied to store.当前osd最新的一次更新
eversion_t last_complete; // last version pg was complete through.要保证所有osd都更新的版本号
epoch_t last_epoch_started;// last epoch at which this pg started on this osd //最新的一次变成active后的epoch
version_t last_user_version; // last user object version applied to store
eversion_t log_tail; // oldest log entry.
hobject_t last_backfill; //backfill的object指针,正常情况为hobject_t::get_max()
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;//统计信息
pg_history_t history;//历史版本
pg_hit_set_history_t hit_set;//cache tier相关
};
pg_log_t{
eversion_t head; // 最新的pg_log_entry版本
eversion_t tail; // 最老的pg_log_entry
eversion_t can_rollback_to;//可以回滚的版本
eversion_t rollback_info_trimmed_to;//回滚场景可以trim的版本
list<pg_log_entry_t> log; //具体的pg_log_entry信息
};
pg_missing_t {
map<hobject_t, item> missing;//丢失对象和版本
map<version_t, hobject_t> rmissing;
};
class MissingLoc {
map<hobject_t, pg_missing_t::item> needs_recovery_map;//需要恢复的对象和版本信息
map<hobject_t, set<pg_shard_t> > missing_loc;//表示该对象在哪些osd上存在
set<pg_shard_t> missing_loc_sources;//存在missing对象的osd列表
PG *pg;
set<pg_shard_t> empty_set;
};
概要分析
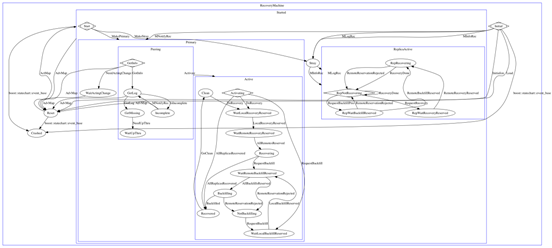
Pg状态机的总体状态转换图
Peering过程中的交互图
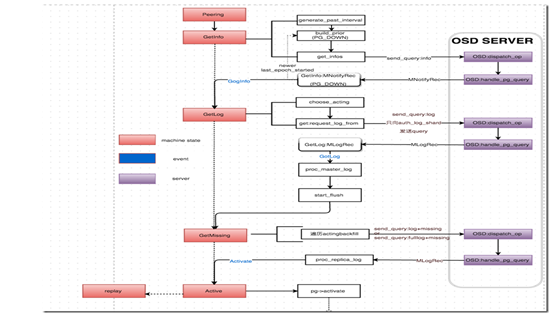
整体来看peering分为4个阶段:Getinfo,Getlog,Getmissing,Active。必要的时候在getmissing之后会有个waitupThru。
Getinfo:pg的主osd收集其他从osd上pg_info_t的信息。
GetLog:选出拥有权威日志的osd,如果不是主则从该osd拉去权威日志给主osd。
GetMissing:主osd去其他osd上拉取pg_entry_t,通过和权威日志对比pg_entry_t来判断各个osd上缺失的object信息。
Active:激活主osd和从osd
基本概念
临时PG、acting set和up set
acting set为pg对应的osd列表,其中列表第一个为主osd。一般情况下acting set和up set是一样的。假设一个pg的acting为[1,2,3]。当1挂了后up为[4,2,3]。这个时候由于4是新加入该pg的osd,上面并没有数据,且需要进行backfill。这个时候会产生一个临时pg。则up为[4,2,3]。但是acting还是为[2,3]。
Up_thru
简单举例:当某个pg对应的osd列表为[1,2],min_size为1。当osd.1和osd.2依次挂掉,可能会有2种情况:
情况1:osd.1挂了,osd.2还未完成peering阶段,osd.2紧接着挂了。这个时候数据无法写入osd.2。
情况2:osd.1挂了,osd.2完成peering进入active后挂了。这个时候该pg存在一个时间窗口可以正常写入数据。
当osd.1重新启动后,如果是情况1,因为没有新数据写入,则pg可以正常完成peering。如果是情况2,有可能一部分数据只在osd.2上存在,则无法完成peering。
为了区分情况1和情况2,所以引入up_thru。up_thru记录了每个osd完成peering的epoch值,osdmap会维护up_thru[osd]的数组。
引入up_thru后,假设初始的up_thru为0。则情况1中up_thru[osd.2]为0,而情况2中up_thru[osd.2]不为0。
Osdmap维护osd_info信息,其中包含up_from和up_thru。up_from到up_thru之间的epoch是无法写入数据的。
past_interval
表示一个epoch的连续序列,在这个epoch的连续序列中该pg的acting和up都没有发生变化。例如:
| epoch |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| 失效 osd |
Osd.3 |
Osd.4 |
Osd.5 |
Osd.2 |
Osd.10 |
Osd.11 |
Osd.12 |
Osd.13 |
|
| up |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
| acting |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,2] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
[0,1,6] |
| Past_interval |
Current_interval |
Statechart状态机
状态:继承boost::statechart::state。状态分为2种:
第一种是没有子状态的状态。例如:
struct Reset : boost::statechart::state< Reset, RecoveryMachine >, NamedState
进入该状态则直接调用构造函数。
第二种是有子状态的状态。例如:
struct Started : boost::statechart::state< Started, RecoveryMachine, Start >, NamedState
struct Start : boost::statechart::state< Start, Started >, NamedState
表示Start是Started的第一个子状态。如果进入Started状态会进入Start
事件:继承boost::statechart::event。例如:
struct MakePrimary : boost::statechart::event< MakePrimary >
状态响应事件:
大致分为3种:
boost::statechart::transition< NeedActingChange, WaitActingChange >
表示收到NeedActingChange事件,进入WaitActingChange 状态,一般投递事件通过post_event方法。
boost::statechart::custom_reaction< ActMap >
这种一般会有 boost::statechart::result react(const ActMap&)方法对应处理事件
boost::statechart::custom_reaction< NullEvt >
NullEvt没有对应的react方法处理,什么也不做,一般只是为了流程上的调度使用。
主要流程
Started/Primary/Active到peering状态转换
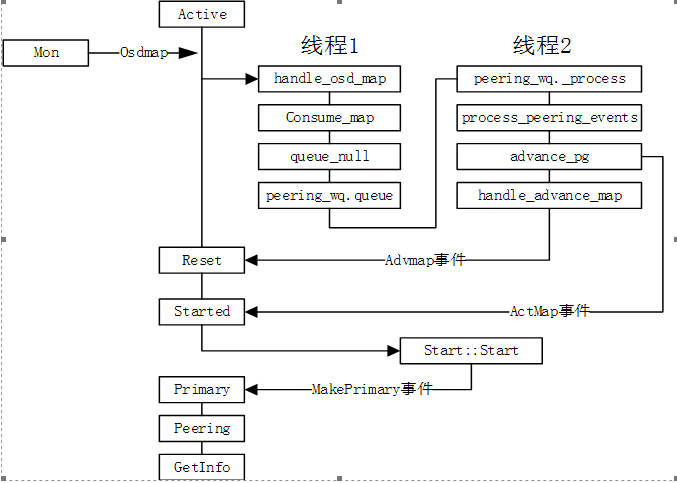
当有osd故障或者启动,会导致osdmap的变化。对应pg的主osd会收到mon发送的osdmap信息。当投递advmap事件后,进入reset状态。

在reset状态,投递Actmap事件进入Started状态,则直接进入Started的第一个子状态Start。构造函数中判断当前osd是osd的主pg,则投递MakePrimary事件,进入Primary状态。于是进入GetInfo状态
GetInfo流程
GetInfo的核心功能都在构造函数中完成。主要包含3个函数:
generate_past_intervals:计算past_intervals的值。
1)调用_calc_past_interval_range来推测所有past_intervals的epoch的start和end范围。
start值:上一次pg clean状态的epoch,pg创建的epoch,最老的osdmap的epoch中较大的值。
end值:一般为当前osdmap的epoch。
2)根据start,end值来遍历历史的osdmap。通过依次比较相邻的osdmap来获取past_intervals值。这里要注意对于maybe_went_rw的判断。
build_prior:根据当前acting,up以及past_intervals构建osd列表
1)把当前acting和up的osd添加到probe的osd列表中。
2)倒序遍历past_intervals中的每一个pg_interval_t,如果interval.last小于info.history.last_epoch_started,表示这个interval在上一次peering之前的,直接break。如果acting为空,或者该interval无数据写入,则continue。遍历interval的acting列表中的osd,如果osd在当前osdmap中是up则加入到probe和up_now中,否则加入到down列表中。通过pcontdec判断当前pg是否处于down状态,pcontdec在多副本场景只要有一个为up_now存在,则为true,ec场景要大于等于M个up_now存在才为true。
3)判断是否要进行up_thru操作。如果该osd在当前osdmap的up thru小于最新的osdmap的epoch,则需要更新。
4)发送pg_query_t给所有prior_set.probe的osd,并将发送osd的信息保存在GetInfo.peer_info_requested和pg->blocked_by中。
5)Pg主osd收到其他osd返回的信息,调用handle_pg_notify。投递MNotifyRec事件,则调用boost::statechart::result PG::RecoveryState::GetInfo::react(const MNotifyRec& infoevt)。
a.从peer_info_requested和pg->blocked_by中移除对应的osd
b.调用proc_replica_info来处理各个副本的pg_info_t信息。
1.检查peer_info中是已经有pg_info_t的信息(peer_info信息在Reset状态的时候会被clear),如果有了直接返回false,否则保存到peer_info中
2.使pg不在osd的scrub的操作队列里。
3.通过merge从osd pg的history到本pg info.history。更新的方法就是使用最大的epoch。如果有更新则dirty_info为true。
4.如果from的osd不在当前的up和acting列表中,则放到stray_set中,当pg clean后调用purge_strays清理数据。
5.更新PGheartbeat_peers,如果需要更新,OSD.heartbeat_need_update设置为true。
c.如果新的pg.info.history.last_epoch_started更大,说明从osd上有更新的上一次peering版本,这个时候需要重新构建prior_set,目的是将不许要probe的osd从peer_info_requested中去掉,以便更快触发GotInfo事件。
d.当peer_info_requested为空,即所有pg_info_t都保存在peer_info中了。倒序遍历past_intervals,以及具体intervals中的acting列表的osd,至少要有一个osd是up状态并且非incomplete状态,不然pg设置为down状态。
e.投递GotInfo事件,进入GetLog状态
GetLog状态流程
GetLog的核心功能也在构造函数中完成。
1)调用choose_acting来选择一个权威日志的osd。整个choose_acting要做的事情包括:
1.选出一个权威日志的osd
2.填充pg的字段:actingbackfill,want_acting,backfill_targets
a.调用find_best_info函数从peer_info中选出一个权威日志的osd。
1.计算所有peer_info中的最大的last_epoch_start,以及在最大last_epoch_start情况下最小的last_update,为min_last_update_acceptable。
2.过滤掉last_update比min_last_update_acceptable小的,last_epoch_started比max_last_epoch_started_found小的,pg是incomplete的情况。
3.如果pg是ec pool的pg则选择last_update较小的,如果是多副本则选择last_update较大的。尽量选log_tail较小的,也就是日志较多的,最后尽可能选主。
综上所述。权威日志的osd要满足的条件:
last_epoch_start必须是最大的,必须是非incomplete的osd,last_update要大于等于min_last_update_acceptable。然后是日志最多的,或者是主。
b.如果find_best_info没有选举出权威日志的osd,且up不等于acting,则把pg加到pg_temp_wanted中,申请临时PG。最后choose_acting返回false
c.如果权威日志的osd是incomplete,则需要从peer_info中complete的osd列表中再选一个权威日志的osd。
d.如果所有的peer_info的osd都支持EC特性,则compat_mode为true。
e.如果是多副本pool,调用calc_replicated_acting。如果是ec pool,则调用calc_ec_acting。
calc_replicated_acting:
这个函数的目的就是要找到主osd以及获取backfill和acting_backfill列表。
1.选pg的主osd,即primary变量。如果up_primary(当前主)的pg_info_t信息的last_update大于权威日志的log_tail,即和权威日志有重叠,则primary就是up_primary。否则权威日志的osd就是主osd。把主osd设置为want_primary,want,acting_backfill中添加主osd。
2.遍历当前up列表的pg_info_t信息,如果last_update小于MIN(primary->second.log_tail,auth_log_shard->second.log_tail)或者是incomplete状态,表示需要backfill的osd,加入到backfill和acting_backfill中。否则是正常的或者recovery的osd放acting_backfill中。
3.遍历acting中存在但是up中不存在的osd。如果存在这样的osd,且和权威日志有重叠,则加到acting_backfill中。
4.遍历all_info中存在但是up和acting中不存在的osd。如果存在这样的osd,且pg_info信息和权威日志有重叠,则加到acting_backfill中。
calc_ec_acting:
1.初始话vector<int> want大小为ec pool size,以及初始值为CRUSH_ITEM_NONE
2.遍历want,其实也是遍历up。将up中pg_info是非incomplete和last_update大于权威日志的tail,则将up中的osd加入到want中。
3.up中其他的osd加入到backfill列表中
4.want中的第一个osd为want_primary。
f.如果want的size小于pool的min_size,则choose_acting返回失败。
g.根据want构造set<pg_shard_t> have。调用recoverable_predicate判断是否可以恢复
h.如果want不等于acting,但是want等于up。则发送MOSDPGTemp消息给mon,申请临时pg,返回失败。
2)如果权威日志的osd就是自己,直接投递GotLog事件,进入GetMissing状态
3)如果权威日志的osd不是自己,更新request_log_from为peer_info中最小的且大于权威日志的tail的last_update。去拉去权威日志
4)主osd收到权威日志的msg,投递GotLog事件,调用boost::statechart::result PG::RecoveryState::GetLog::react(const GotLog&)
5)GotLog事件处理,如果有msg,则调用proc_master_log来合并权威日志。完成后进入GetMissing状态
a.调用PGLog::merge_log来合并权威日志。输入包括权威日志的信息oinfo和olog和本pg的info信息
| From |
To |
||||
| 权威日志 |
(20,2) |
(20,3) |
(20,4) |
(20,5) |
(20,6) |
| 本地日志 |
(20,4) |
(20,5) |
(20,6) |
1.如果权威日志的tail小于本地log的tail,说明本地日志有缺失,计算权威日志和本地日志重叠的版本号to。从权威日志中拷贝本地日志缺失的log_entry_t到本地,更新本地info的log_tail为权威日志的log_tail。
| 分歧日志 |
|||||
| 权威日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
||
| 本地日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
2.如果权威日志的head小于本地日志的head,说明最新的数据在本地日志中存在。调用
rewind_divergent_log来处理分歧日志。
a.先根据权威日志的head来获取本地分歧日志的列表,将本地日志的info和pglog的head信息以及last_update信息都更新为权威日志的head。说明分歧日志是需要被trim的
b.将分歧日志按照object分类,将同一个object的pg_log_entry_t放到一个list中。
c.调用_merge_object_divergent_entries来处理对象的分歧日志集合。将所有分歧日志给加入trim的事务中。1)如果本地日志该对象最新的版本大于或等于分歧日志的第一个版本,说明该对象后续还有对于该object的操作完成。把这个对象删除,missing列表中have设置为空,通过missing列表来恢复。这个场景有一些没明白。2)如果分歧日志的前一个版本是eversion_t或者第一条日志是clone日志,说明是个创建日志,没必要恢复,直接从missing列表中删除,这个对象也删除。3)如果这个对象已经在missing列表中了,且分歧日志的前一个版本已经是当前item的have,说明当前版本就是最新的版本,则从missing列表中移除。否则item的need就是分歧日志的前一个版本。如果分歧日志的前一个版本比日志的最老的版本还要老,则另外处理。4)5)先判断分歧日志是否有一条日志可以rollback。如果可以rollback则放到rollback的队列中,否则将对象删除,通过missing列表恢复。
| from |
|||||
| 权威日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
| 本地日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
3.如果权威日志的head大于本地日志head,说明本地日志的数据不够新。先通过后续遍历权威日志找到from点。把从from开始的权威日志加到本地pg_log中。同时将pg_log_entry_t的object加入到missing列表中。
| from |
|||||
| 权威日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(22,5)obj2 |
(22,6)obj2 |
| 本地日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
入上图,权威日志的head大于本地日志head有可能的一种特殊情况。将本地日志(20,5)(20,6)放到分歧日志列表中,并从本地日志中删除这些分歧日志,更新为权威日志的pg_log_entry。再根据2中处理分歧日志的5条规则来处理这些分歧日志。
b.更新权威日志osd的peer_info和peer_missing到本地pg中。Merge权威日志的history信息到本地的history信息中。整个proc_master_log完成后,进入GetMissing阶段。
GetMissing流程
1)构造函数中遍历actingbackfill的副本osd的pg_info_t信息。其中需要backfill和没有missing对象的osd直接continue。剩下的都是需要recovery的副本osd。如果副本osd的pg_info信息的last_epoch_started(上一次达到active的版本号)大于log_tail,说明只有部分日志的对象需要回复,所以只需要拉去从last_epoch_start到log_head的日志。否则就是全部日志都需要恢复,则拉去全部日志。同时把需要拉去的osd加入到peer_missing_requested中。
2)如果peer_missing_requested为空,表示没有需要拉去日志的osd。则直接进入到Active状态。
3)如果peer_missing_requested不为空,则等待副本osd返回pg_log的信息。当副本信息返回的时候会投递MLogRec事件,调用boost::statechart::result PG::RecoveryState::GetMissing::react(const MLogRec& logevt)。其中调用proc_replica_log来处理返回的副本pg_log。并且peer_missing_requested删除对应的osd。当peer_missing_requested为空,说明所有副本osd的pg_log信息都返回了,则进入到Active状态。重点看proc_replica_log如何处理副本osd的pg_log信息
| lower_bound |
Fromiter 分歧日志 |
分歧日志 |
|||
| 副本日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
| 权威日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
| lower_bound |
Fromiter |
||||
| 副本日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
||
| 权威日志 |
(20,2)obj1 |
(20,3)obj2 |
(20,4)obj3 |
(20,5)obj2 |
(20,6)obj2 |
a.先通过对比副本日志和权威日志的信息,找到lower_bound和fromiter。可能出现的场景为上面2种。如果有分歧日志,则处理分歧日志。
b.值得注意的是本以为副本osd的Missing信息应该是在proc_replica_log中来获得,但是实际上并没有。
Active流程
主要流程在PG::activate中完成。
1)更新pg_info的信息,主要是last_epoch_started字段为当前的epoch。last_update_ondisk为last_update,如果pg的missing为空则last_complete为last_update
2)如果是主osd还需要激活从osd。1.如果从osd的last_update等于主osd的last_update。说明这个从osd是clean的,加入到activator_map中,后续在do_infos中发送pg_info来激活。2.需要backfill的osd发送最新的pg_info和pg_log_entry,peer_missing清空。3.需要recovery的osd,发送最新的pg_info和丢失的pg_log_entry,更新peer_missing。
3)设置missing_loc,调用add_active_missing将missing和peer_missing的oid加入到needs_recovery_map中。needs_recovery_map只保存了missing的object和pg_missing_t::item的对应关系。最终我们还需要missing的object和osd之间的关系。遍历所有osd,调用add_source_info,来设置missing_loc。
4)当收到副本osd的回复后,触发MInfoRec事件,调用boost::statechart::result PG::RecoveryState::Active::react(const MInfoRec& infoevt)。每回来一个osd的信息peer_activated插入osd信息,当peer_activated等于actingbackfill,调用all_activated_and_committed,表示收到所有osd的返回信息。投递AllReplicasActivated事件。
5)boost::statechart::result PG::RecoveryState::Active::react(const AllReplicasActivated &evt)处理所有副本返回的事件。清理和设置pg的状态。设置history.last_epoch_started等于pg的last_epoch_started。调用check_local来检查已经被删除的对象是否还在。调用ReplicatedPG::on_activate来触发recovery或者backfill流程。