在高维数据分析过程中,为了筛选出与目标结局相关的变量,通常会用到回归分析,但是因为自变量较多,往往要进行多次回归。这就是统计编程语言发挥作用的时候了
有些大神们认为超过3次的复制粘贴就可以考虑使用循环了,当然个人“承受能力较强”,在分析过程中还是经常会用复制粘贴来解决相当一部分的问题。但是当变量太多需要多次复制粘贴,并且还要对不同的过程设置不同的编号真的太麻烦了。比如有100个X,就要命名100个模型,从fit1到fit100,显然可操作性太差了。
所以循环必须派上用场,接下来将总结一下在R中使用循环来进行回归分析的几个常用方法。
我们以R自带的state.x77数据集为例进行介绍。 由于原始数据集是矩阵,先转变成数据框,再以一个简单的名字命名。数据结构如下:
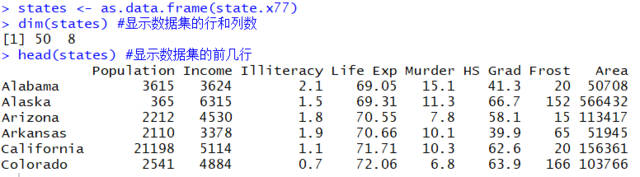
行代表50个不同的州,列是8个不同的变量:Population:人口数;Income:收入;Illiteracy:文盲率(百分比);Life Exp:期望寿命;Murder:凶杀案发生率(每10万人);HS Grad:高中毕业率;Frost:气温低于冰冻的天数;Area:每平方英里的陆地面积。
我们以凶杀案发生率(Murder)为因变量,看哪些因素跟案件发生率有关。
1.根据变量所在的列号进行循环

开始循环之前先建立一个空的向量result1用以在循环过程中储存提取的结果。
模型中states[,i]表示逐个选择states数据框的第1-4个变量,进行线性回归分析。
coef(summary(fit))[2,c(1,2,4)]用以提取目标变量回归分析结果的beta,SE,和p值。提取之后通过colnames(states)[i]加上相应变量的变量名。最后在循环过程中通过rbind将结果合并在一个数据框result1中,结果如下:

可以通过write.csv()等函数将结果输出到本地文件夹中。
这种循环方法适用于变量在数据框中是连续排列的。
2.根据变量名进行循环

如果目标变量在数据框中不是连续的,可以使用这个方法,先建立一个目标变量名的向量,然后在回归方程中加上substitute函数,分别将提前建立的变量名替换到方程中,建立变量名的循环。
这里注意了:一定要使用substitute函数,不能直接将states[,as.name(vars[i])]放入方程中,有兴趣的读者可以查一下substitute函数的用法。
结果如下:

3.使用apply函数进行循环

先自定义一个线性回归函数,可以直接提取出回归结果中的beta,SE,和P值。然后用apply函数(也可以使用sapply等函数)将此自定义的函数分别使用于数据集选定的列。再通过转置函数t( )使结果更具有可读性。
结果如下:
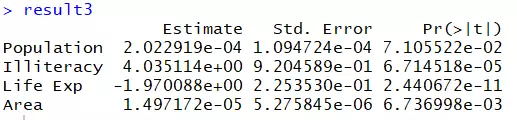
该方法既适用于目标变量在数据框中是连续排列的,也适用于不连续排列的情况。
4.使用purrr包的map函数进行循环

该方法与apply族函数的思路相似,不同的是purrr包是Hardley大神tidyverse的核心包之一,速度非常快,特别适用于数据较大,变量较多的数据集。
同样需要先自定义一个线性回归函数,然后通过map函数适用于数据集选定的列。
得到结果如下:
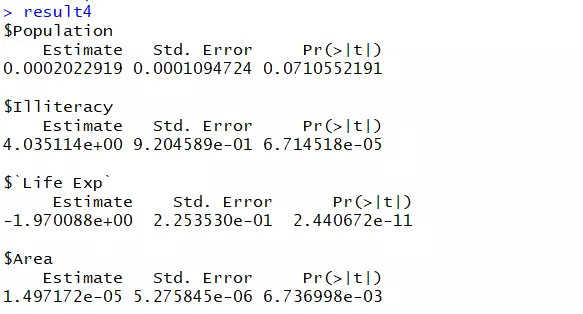
发现不太适合直接导出,没关系,加上as.data.frame和转置函数t()就可以了,结果如下:
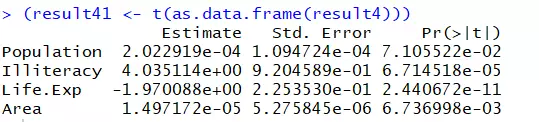
以上是在R语言中用循环做回归分析的常用方法,其中有些细节可以根据自己的需要进行调整,比如提取结果中的其他变量。
这些循环方法也适用于其他回归模型,比如常用的logistic回归。另外我在自己的数据集中测试了不同方法的耗时情况,几次测试map函数都是最省时的,for循环和apply函数在我的数据上表现相差不大。