参考原文:https://www.cnblogs.com/llzhang123/p/9037449.html、https://blog.csdn.net/yu757371316/article/details/79303321
1、为什么要进行分库分表
分库分表能有效的缓解单机和单库带来的性能瓶颈问题和压力,突破IO,硬件资源,连接数的瓶颈。
同时也带来了一些问题。
2、分库分表的方法
-
垂直分表:
可以把一个宽表的字段按照访问的频次、是否为大字段的原则拆分为多个表
好处:业务清晰,还能提升部分性能
坏处:如果业务需要表间连查,性能方面得不偿失
-
垂直分库
可以把多个表按照业务耦合松紧归类,分别存放在不同的库
好处:这些库可以分布在不同服务器上,从而使得访问压力被多服务器负载,大大提升性能,同时能提高整体架构的清晰度,不同的业务可根据自己情况定制优化方案。
坏处:因为可能出现跨库操作(如跨裤jion,分布式事务),需要解决所以的这些复杂问题。
-
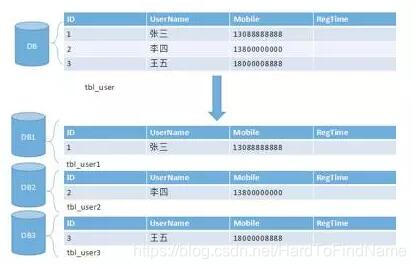
水平分库(分库分表)
可以把一个表的数据按照数据行分到多个不同的库,每个库只有这个表的部分数据。
好处:这些库可以分布在不同的服务器,从而使得访问压力被多服务器负载,大大提升性能。
坏处:它不仅需要解决跨库带来的所以复杂的问题,还要解决数据路由的问题。
-
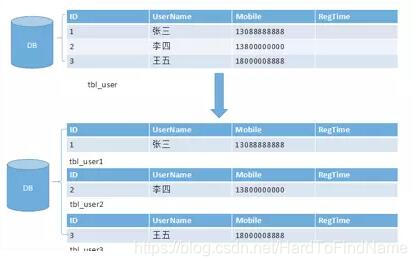
水平分表(库内分表)
可以把一个表的数据按数据行分到同一个库的多张表中,每个表只有这个表的部分数据,这样做能小幅度提升性能,它仅仅作为水平分库的一个补充优化。
3、带来的问题
-
事务一致性问题
由于分库分表把数据分布在不同的数据库甚至是不同的服务器上,不可避免会带来分布式事务问题。 -
跨节点关联查询
未分库前,表间可直接通过jion操作进行关联查询,但是垂直分库后,数据表可能不在同一个数据库甚至不在同一个服务器,无法进行关联查询。 -
跨节点分页、排序函数
未分库前,查询可以使用limited和order by进行分页和排序,但是水平分库后,以前同一张表的数据可能不在同一个数据库甚至不在同一个服务器,无法直接使用limited和order by进行操作。 -
主键避重
分库分表后,水平拆分后的表的主键在主键递增过程中可能出现相同的主键值,会导致根据一个主键查出多个记录的现象。 -
公共表
在实际的应用场景中,参数表、数据字典都是数据量较小,变动少,而且属于高频联合查询的依赖表,它们无法进行单一归类。
4、问题解决
- 跨节点关联查询
使用冗余字段,提升性能避免jion进行跨节点关联查询,但是要求依赖字段较少。 - 公共表
可以将这类表在每个数据库都保存一份,所以对公共表的更新操作都同时发给所以的分库执行。 - 主键避重
不使用自增主键,使用全局主键,例如使用UUID生成唯一主键,保证没有重复主键出现,可以使用雪花算法生成有意义的全局主键。 - 跨节点分页、排序函数
进行多次查询后,将结果合并再进行分页、排序
分布式事务根据业务自己进行解决。。。。。。sharding-jdbc无法解决分布式事务