作者: Fanjin Zhang
开放学术图谱(OAG)是一个大型学术知识图谱。它连接了两个亿级学术图谱:微软学术(Microsoft Academic Graph,MAG)[1] 和AMiner [2]。
Paper: http://keg.cs.tsinghua.edu.cn/jietang/publications/KDD19-Zhang-et-al-Open_Academic_Graph.pdf
Code: https://github.com/zfjsail/OAG
Data: https://www.aminer.cn/oag2019
Slides: http://keg.cs.tsinghua.edu.cn/jietang/publications/kdd2019-Zhang-et-al-OAG.pptx
开放学术图谱(OAG)是一个大型学术知识图谱。它连接了两个亿级学术图谱:微软学术(Microsoft Academic Graph,MAG)[1] 和AMiner [2]。2017年8月,清华大学和微软研究院联合发布了OAG v1,其中包含来自MAG的166,192,182篇论文和来自AMiner的154,771,162篇论文,以及64,639,608对链接(匹配)关系。2019年2月,新发布的OAG v2包含了更多类型数据(作者,出版地点,论文)以及相应的匹配关系。OAG是迄今为止最大的公开学术图谱。
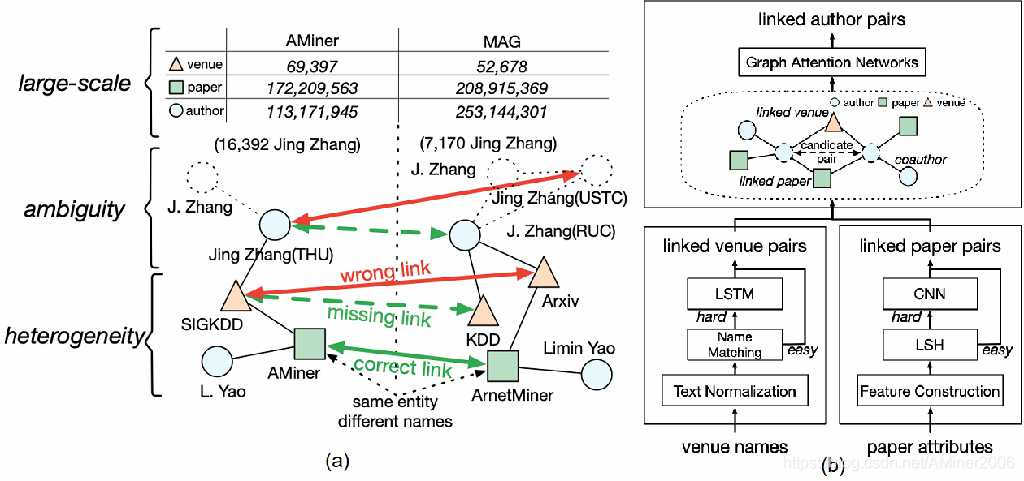 图1:(a) OAG问题定义和挑战,(b) 匹配框架LinKG
图1:(a) OAG问题定义和挑战,(b) 匹配框架LinKG
构建亿级开放学术图谱是一项极具挑战的研究工作。图1(a)展示了OAG面临的问题和挑战。OAG的目标是匹配不同数据源中指代相同的实体,它主要面临以下几个挑战:(1) 实体异构。不同数据源中的相同实体可能表示形式不同,如作者姓名格式不同:如Quoc Le 和Le, Quoc;发表地点有全称或缩写等多种形式。(2) 实体歧义。同一名称可以表示多个实体,这也给图谱连接带来了很大困难。例如:AMiner中有超过10,000个叫Jing Zhang的学者,而MAG中也有7,000多个;论文匹配也存在这样的问题,如在KDD 2016中收集了两篇题为“robust influence maximization”的不同论文。(3) 大规模匹配。以已经公布的论文数据为例,AMiner和MAG各自有约1.7亿和2亿篇论文,因此需要设计一个高效的匹配框架。
为此,我们设计了一个统一的框架LinKG来解决以上挑战。LinKG包括三个匹配模块,用于匹配不同类型的实体:出版地点,论文和作者。在每个模块中,我们针对每种类型实体不同的匹配难点设计了不同的算法。图1(b)展示了LinKG的框架。(1) 出版地点匹配:对于出版地点匹配,考虑到匹配效率和效果,我们主要利用了出版地点全名信息。在出版地点匹配任务中,我们发现全名中单词的相对顺序比较重要,而且相同的出版地点可能有不同长度的表示(多前缀或后缀),因此我们提出采用基于长短时记忆网络(LSTM)的方法来匹配出版地点。(2) 论文匹配:对于论文匹配,我们利用了论文的多种属性,例如论文题目和作者列表。由于每个数据源中的论文数量都达到了上亿级别,我们首先利用局部敏感哈希(LSH)进行快速匹配;对于用哈希匹配不上的论文,我们对两篇论文的属性构造相似度矩阵,利用卷积神经网络(CNN)进行精确匹配。 (3) 作者匹配:作者匹配相比于其他类型的实体匹配更有挑战性,因为作者姓名的歧义性可能很严重。因此我们利用了前两个模块得到的匹配结果来帮助作者匹配。对于每个作者,我们构造一个局部子图,该子图包括她的论文,发表论文的出版地点,和合作者等。对于每对候选匹配作者,我们提取她们的局部子图,已经匹配上的实体会使得这两个子图连通。然后,我们提出采用异构图注意力网络(heterogeneous graph attention network,HGAT)在子图上学习每对候选作者是否匹配。我们做了大量实验来验证每个模块采用的方法在相应问题上具有优越性。该框架中方法的详细介绍参见 [3].
基于框架LinKG,我们已经生成和发布了开放学术图谱(OAG)。OAG v2现在包括91,137,597条论文匹配关系,29,841条出版地点匹配关系,1,717,680条作者匹配关系。对于作者匹配,学者们只考虑了论文数不少于5的作者。将论文数量较少的作者排除后,AMiner中有6,855,193位作者,MAG中有13,173,936位作者。我们评估了少部分匹配关系(每种实体大约1,000个实体对),出版地点,新匹配论文(不包括OAG v1),作者匹配准确率分别为99.26%, 99.10%和97.41%。OAG可以用于多种研究课题,如:网络数据挖掘(论文引用关系网络,作者合作关系网络等),文献内容挖掘,同名作者消歧和学术图谱对齐等。
 实验结果以及和其他方法对比
实验结果以及和其他方法对比
参考文献
[1] Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. ArnetMiner: Extraction and Mining of Academic Social Networks. In Proceedings of the Fourteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD’2008). pp.990-998.
[2] Arnab Sinha, Zhihong Shen, Yang Song, Hao Ma, Darrin Eide, Bo-June (Paul) Hsu, and Kuansan Wang. 2015. An Overview of Microsoft Academic Service (MAS) and Applications. In Proceedings of the 24th International Conference on World Wide Web (WWW ’15 Companion). ACM, New York, NY, USA, 243-246.
[3] Fanjin Zhang, Xiao Liu, Jie Tang, Yuxiao Dong, Peiran Yao, Jie Zhang, Xiaotao Gu, Yan Wang, Bin Shao, Rui Li, and Kuansan Wang. OAG: Toward Linking Large-scale Heterogeneous Entity Graphs. In Proceedings of the Twenty-Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19).