星云的 Spring Data JPA学习手册
- 0x01 为什么要学习Spring Data JPA?
- 0x02 如何集成Spring Data JPA?
- 0x03 Spring Data JPA 核心技术
- 3.1 Spring Data JPA 是如何实现Repository的?
- 3.3.1 Repository
- 3.1.2 CrudRepository
- 3.1.3 PagingAndSortingRepository
- 3.1.4 JpaRepository
- 3.1.5 自定义Repository
- 3.2 Spring Data JPA 是如何实现接口的?
- 3.3 如何正确使用Spring Data JPA ?
- 0x04 项目信息
- 0x05 参考资料
这篇博文主要讲解 Spring Data JPA 技术的知识。
0x01 为什么要学习Spring Data JPA?
在码农的世界里有一句话,码农从来不做没有目的的事情
那么为什么我们要学习Spring Data JPA 呢?
试想下,我们是否曾经有过这样的烦恼?
当我们开发设计一款应用的时候,我们是不是第一步往往要手动创建业务实体类,然后再创建表?
假设我们之前用的数据库是MySQ,后来换成了Oracle,SQL语法有差异,你要手动修改所有的SQL么?
程序部署每次换一个地方,我们是不是都要先手动根据实体类建立数据库或导入SQ语句?
如果你有以上这样的苦恼, 那么来跟我一起来学习下Spring Data JPA吧~
- Spring Data JPA 可以帮我们在实体类和数据库表之间建立一个映射
- Spring Data JPA 可以帮我们在程序启动的时候完成数据库和表的创建
- Spring Data JPA 可以帮我们在程序启动的时候插入一些测试数据
- Spring Data JPA 可以帮我们屏蔽切换不同数据库带来的语法差异
1.1 什么是Spring Data JPA?
在知道Spring Data JPA能干什么之后,也许此时的你已经心动了。
- 如果你喜欢上了一个人,那就要努力去追求她,怎么追呢?首先你要了解她,分析她,知道她的习惯。
- 如果你喜欢上了一个技术,那就要努力去学习它,怎么学呢?首先你要了解它,分析它,知道它的规则。
那么就让我们一起来了解下什么是Spring Data JPA吧。
那么什么是Spring Data JPA 呢?
- Spring Data JPA 是Spring Data 庞大家族的一员,它帮助我们简化了基于JPA的 repositories (存储库)的开发。
那传说中的JPA ,Spring Data JPA 和Hibernate 又是什么关系呢?
JPA和Spring Data JPA 和 以及Hibernate的关系如下图所示: 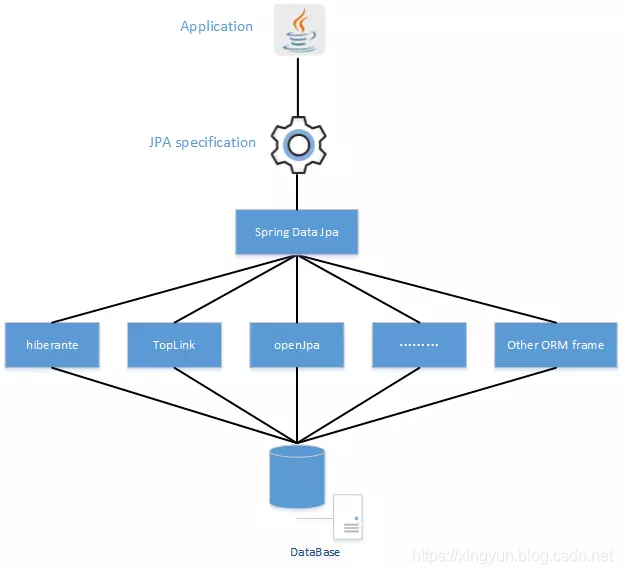
正如上图所示
- JPA 是Java Persistence API 的英文缩写,中文名Java持久层API.
- 值得注意的是JPA 是Java 持久化规范,并不是持久层框架。
- Spring Data JPA (Java Persistence API) 也不是ORM框架,而只是一种ORM规范(标准接口)和对JPA规范的抽象
- Spring Data JPA 实现了JPA规范并默认使用Hiberante作为底层实现,如果想,也可以把Hiberante 换成其他ORM框架,比如
TopLink等。- Sun引入新的
JPA ORM规范其实出于两个原因:
- 其一,为了简化持久层开发以及整合ORM技术;
- 其二,结束
Hibernate、TopLink、JDO等ORM框架各自为营的局面,实现天下归一的目的
Tips: 秦始皇统一度量衡,因此天下大兴,ORM框架也一样。
1.2 JPA的核心思想
那么 JPA 规范到底规定了什么?
- JPA 的核心设计思想和
Hibernate是一致的,致力于以一种面向对象的语法来操作SQL.- JPA 提出了
repository support(存储库支持)的设计思想,简单点来讲就是说对常用的增删改查以及分页查询排序等提供了默认实现,以简化Java 持久层的开发。- 业务实体类和数据库表之间通过
@Column@Table等注解建立映射- 支持
@Query注解编写原生的SQL
以一种面向对象的语法(JPQL语言)来操作SQL
如果你不太理解什么叫做以一种面向对象的语法来操作SQL,那么看下下表应该就明白了
下表描述了JPA支持的关键字以及包含该关键字的方法转换为:
| Keyword | Sample | JPQL代码段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
1.3 Spring Data JPA 1.11 新变化
Spring Data JPA 1.11 版本改动如下:
- 改进了与Hibernate 5.2 的兼容性
- 增加了Query by Example.任意匹配模式的支持 (根据传入对象,多条件查询)
- 分页查询执行优化
- 支持自定义扩展repository.
0x02 如何集成Spring Data JPA?
在我看来,技术应该是免费的,共享的,技术是用来解决问题的,用技术解决企业的需求问题才是应该需要付费的。
我们已经大致了解了Spring Data JPA 的相关概念和为什么要学习它以及它解决了什么问题,那么Spring Boot 和Spring Data JPA 应该如何集成呢?
我们只需要在我们项目的pom.xml 中添加如下依赖即可:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
其次,值得注意的是, 如果使用最新版的Spring Data JPA有两个最低要求
- JDK8+
- Spring Framework 5.1.9.RELEASE +
对于一些比较大的项目,往往会引入很多依赖,其中某个依赖中可能会由于传递依赖引入不同的Spring data JPA 版本
如果你想解决这种兼容性问题,那么我们需要在pom.xml中添加如下依赖即可<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-releasetrain</artifactId> <version>Lovelace-SR10</version> <scope>import</scope> <type>pom</type> </dependency> </dependencies> </dependencyManagement>
0x03 Spring Data JPA 核心技术
Spring Data repository (repository)抽象的目的是为了减少各种持久性存储实现需要写的增删改查,分页以及排序等模板代码。
3.1 Spring Data JPA 是如何实现Repository的?
接下来我们来学习下Spring Data JPA 是如何实现Repository的?
这里我们可以思考下,如果让你去设计实现增删改查,分页以及排序模板代码,你会怎么设计?
我觉得如果是我的话,如果想要做到上面那样的需求,按照我的理解
- 首先我们至少需要指明一个实体类然后通过反射获取实体类的成员属性
- 之后指定主键是哪一个,以及指明主键ID的类型
Spring Data JPA 是这么设计的,它设计了很多接口类
- 最顶级接口
Repository- 返回带游标结果的接口
CrudRepository- 处理分页和排序的接口
PagingAndSortingRepository- 返回Java 对象的接口
JpaRepository- 返回MongoDB 对象的接口
MongoRepository
接下来我们详细介绍下这几个接口类
3.3.1 Repository
正如我们刚才看到的那样,Repository 是Spring Data JPA中最顶级的接口,在这个接口类中并没有定义任何接口方法。
import org.springframework.stereotype.Indexed;
@Indexed
public interface Repository<T, ID> {
}
- 关于
@Indexed
- 该注解只是一个标识索引注解,官方文档上没找到对它的详细解释
- 但是想想也应该明白,它应该只是用来区分当前类是普通接口类还是Spring Data JPA Repository (存储库) 接口类的一个注解。
- 而且有了这个注解,我们也可以很方便通过扫描包的方式找到该类型的接口。
- 关于
<T, ID>
- 虽然这个方法没有定义任何接口方法,但是它做了一个最顶级的抽象,T 泛型,代指任意持久化类,ID 泛型,任意对象类型,代指主键ID类型
- 我们知道对于一张表来说,最重要的就是表的各个字段名称和类型属性,以及表的主键信息,一旦我们获取了T,和ID,我们就可以通过反射来获取这些信息,然后鼓捣做一些事情。
如果只有上面这个接口的功能,很明显是远远不够的。
因此Spring Data JPA 还提供了另外一个类CrudRepository
3.1.2 CrudRepository
CrudRepository 这个接口类继承自Repository接口,不仅拥有父类的功能,它还增加数据库几乎常用的增删改查的所有方法。
import java.util.Optional;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);//保存一个对象
<S extends T> Iterable<S> saveAll(Iterable<S> var1);//保存多个对象
Optional<T> findById(ID var1);//根据主键ID查找一个对象
boolean existsById(ID var1);//根据主键ID查找一个对象是否存在
Iterable<T> findAll();//查找所有对象
Iterable<T> findAllById(Iterable<ID> var1);//根据Id集合查找所有符合条件集合
long count();//统计当前实体类中拥有的对象
void deleteById(ID var1);//根据主键ID删除一个对象
void delete(T var1);//根据一个对象删除该对象
void deleteAll(Iterable<? extends T> var1);//根据多个对象删除多个对象
void deleteAll();//删除所有对象
}
- 使用了
@NoRepositoryBean注解的接口,就不会在运行时为其自动生成实现类。- 这个接口返回的对象集合是带迭代器的结果。
3.1.3 PagingAndSortingRepository
PagingAndSortingRepository 接口继承自CrudRepository ,不仅拥有父类的全部功能还增加了分页和排序的功能
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1);
Page<T> findAll(Pageable var1);
}
对于Pageable 这个对象我们可能刚开始比较陌生,那么如何使用呢?
调用方法如下所示:
PagingAndSortingRepository<User, Long> repository = // … get access to a bean
Page<User> users = repository.findAll(PageRequest.of(1, 20));
3.1.4 JpaRepository
JpaRepository 接口继承自PagingAndSortingRepository,不仅拥有以上三种接口的所有功能,还将CrudRepository接口中的返回的迭代器集合变成了更加友好的Java对象集合,除此之外还增加了一个新功能 Example 方式查询。
框架源码如下:
import java.util.List;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.data.repository.query.QueryByExampleExecutor;
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();//查找所有对象返回一个更友好的Java集合对象
List<T> findAll(Sort var1);
List<T> findAllById(Iterable<ID> var1);
<S extends T> List<S> saveAll(Iterable<S> var1);
void flush();
<S extends T> S saveAndFlush(S var1);
void deleteInBatch(Iterable<T> var1);
void deleteAllInBatch();
T getOne(ID var1);
<S extends T> List<S> findAll(Example<S> var1);
<S extends T> List<S> findAll(Example<S> var1, Sort var2);
}
其他的比较简单就不废话了,咱们来聊聊什么是Example 方式查询。
如果我们打开QueryByExampleExecutor.java可以看到如下内容
public interface QueryByExampleExecutor<T> {
<S extends T> Optional<S> findOne(Example<S> var1);
<S extends T> Iterable<S> findAll(Example<S> var1);
<S extends T> Iterable<S> findAll(Example<S> var1, Sort var2);
<S extends T> Page<S> findAll(Example<S> var1, Pageable var2);
<S extends T> long count(Example<S> var1);
<S extends T> boolean exists(Example<S> var1);
}
这种新型的方式该怎么用呢?
我这里贴一段示例代码大家看下应该就明白了
import com.xingyun.springbootwitheasyshopsample.dao.repository.UserRepository;
import com.xingyun.springbootwitheasyshopsample.model.User;
import com.xingyun.springbootwitheasyshopsample.model.dto.UserDto;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
/**
* @author 星云
* @功能
* @date 9/22/2019 11:45 AM
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
UserRepository userRepository;
@Override
public Page<User> getPage(Pageable pageable) {
//这里直接使用Jpa提供的分页查询功能
return this.userRepository.findAll(pageable);
}
@Override
public List<User> showAllUser() {
return userRepository.findAll();
}
@Override
public User load(Long id) {
//封装查询条件
User findUser=new User();
findUser.setId(id);
//转换成查询对象
Example<User> findUserExample=Example.of(findUser);
//获取查询结果
Optional<User> resultUserWithOptional=this.userRepository.findOne(findUserExample);
if(resultUserWithOptional.isPresent()){
//获取业务实体类
return resultUserWithOptional.get();
}else{
return null;
}
}
@Override
public User save(UserDto user) {
User queryUser=new User();
queryUser.setId(user.getId());
//转换成查询对象
Example<User> checkUserExample=Example.of(queryUser);
//获取查询结果
Optional<User> findUserWithOptional=this.userRepository.findOne(checkUserExample);
//返回用户
User checkUser;
if(findUserWithOptional.isPresent()){
//返回用户
checkUser=findUserWithOptional.get();
}else{
//如果对象为空
//创建一个对象
checkUser=new User();
//设置要保存的对象属性
checkUser.setAvatar(user.getAvatar());
checkUser.setNickName(user.getNickName());
}
return this.userRepository.save(checkUser);
}
@Override
public void delete(Long id) {
//根据Id 删除某一个用户
this.userRepository.deleteById(id);
}
}
看明白了么?这种方式使得多条件查询变得更加灵活。
我们可以传一个对象,只要对象的某个值不为空,就按照该属性作为条件进行查找。
我觉得这种实现方式很类似MyBatis 中的这种if 条件语句写法
示例代码如下:
<select id="selectAllUserInfoByCondition"
parameterType="map"
resultMap="userInfoMap">
SELECT
<include refid="userInfoFieldSQLId"/>
FROM t_user_info
<where>
<if test="userInfoAccount!=null and ''!=userInfoAccount">
AND USER_INFO_ACCOUNT = #{userInfoAccount}
</if>
<if test="null!=userInfoPassword and ''!=userInfoPassword ">
AND USER_INFO_PASSWORD= #{userInfoPassword}
</if>
<if test="null!=userInfoAge and 0!=userInfoAge ">
AND USER_INFO_AGE= #{userInfoAge}
</if>
<if test="null!=userInfoSex ">
AND USER_INFO_SEX= #{userInfoSex}
</if>
<if test="null!=userInfoId and 0L!=userInfoId ">
AND USER_INFO_ID= #{userInfoId}
</if>
</where>
</select>
关于返回MongoDB 对象的接口
MongoRepository不属于本节课的内容暂时跳过。
3.1.5 自定义Repository
上面中我们讲解了Spring Data JPA 已经提到了如下几种 Repository
Repository- 返回游标的接口:
CrudRepository- 处理分页和排序的接口:
PagingAndSortingRepository- 返回Java 对象的接口:
JpaRepository- 返回MongoDB 对象的接口:
MongoRepository
现在假如我们有这一种场景,有两个类中有一些公共的接口需要实现,那么应该怎么做呢?
- 定义一个接口但是要用
@NoRepositoryBean注解
@NoRepositoryBean
interface MyBaseRepository<T, ID extends Serializable> extends Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
- 使用这个注解不会在运行时自动生成这个MyBaseRepository接口的实现类
- 其次,值得注意的是,
ID extends Serializable必须有这一句。
然后编写我们自己的类继承自这个公共类
interface UserRepository extends MyBaseRepository<User, Long> {
User findByEmailAddress(EmailAddress emailAddress);
}
Spring Data JPA 会按照我们上面刚才的方法找到这个类,然后为这个类在运行时实现接口类的方法。
如果不想使用Spring Data JPA 自动帮我们实现实现类,那么我们也可以这么做
- 定义一个接口
interface CustomizedUserRepository {
void someCustomMethod(User user);
}
- 自己编写代码实现类
class CustomizedUserRepositoryImpl implements CustomizedUserRepository {
public void someCustomMethod(User user) {
// Your custom implementation
}
}
最后编写调用注入的接口层
interface UserRepository extends CrudRepository<User, Long>, CustomizedUserRepository {
// Declare query methods here
}
3.2 Spring Data JPA 是如何实现接口的?
思考:
- 学习到这里我不知道你是不是有些疑惑,我们刚才只是定义了接口,这些接口的实现类在哪里?
- 这事我们没做,那么肯定是Spring Data JPA偷偷把这个活干了,那么Spring Data JPA 是如何实现Repository 接口类的呢?
我们打开Spring Data JPA 源码来看看,可以看到JpaRepository接口的实现类是这么做的。
- 首先定义一个实现类扩展接口
JpaRepositoryImplementation<T, ID>
源码如下:
public interface JpaRepositoryImplementation<T, ID> extends JpaRepository<T, ID>, JpaSpecificationExecutor<T> {
...
}
- 然后定义一个最简单的默认的实现类
SimpleJpaRepository.java
源码如下:
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
...
}
- 一旦检测该接口是
Spring Data JPA Repository就自动默认使用该实现类- 具体的一些细节就不展开细讲了,有兴趣可以自己打开看看,我只负责抛一个砖,至于砸到你头上是起一个疙瘩,还是能引出来一块玉,全看个人造化。
笑.svg
3.3 如何正确使用Spring Data JPA ?
3.3.1 定义一个继承Repository类型的接口
使用的第一步,我们需要定义一个继承Repository类型 的接口
当然这个接口我们可以使用Repository
interface PersonRepository extends Repository<Person, Long> {
}
也可以使用CrudRepository
interface PersonRepository extends CrudRepository<Person, Long> {
}
甚至也可以是JpaRepository
interface PersonRepository extends JpaRepository<Person, Long> {
}
不过我觉得最好使用最后一种JpaRepository ,功能最多,返回的不是迭代器对象,而是
List<Object>,并且提供了Example多条件复合查询。
3.3.2 声明遵循JPQL语法的自定义接口方法
然后如果默认的接口中的方法不能满足我们的需要,我们也可以自定义遵循JPQL语法的接口方法
interface PersonRepository extends JpaRepository<Person, Long> {
List<Person> findByLastname(String lastname);
}
多学一招,如果想使用原生的SQL,也可以使用@Query注解
public interface UserRepository extends JpaRepository<User,Long> { @Query("select u from User u where u.emailAddress = ?1",nativeQuery = true) User findByEmailAddress(String emailAddress); }
?1为占位符,会将?1用第一个参数的值替换掉
- 如果是带分页的那种写法是这样
public interface UserRepository extends JpaRepository<User, Long> { @Query(value = "SELECT * FROM USERS WHERE LASTNAME = ?1", countQuery = "SELECT count(*) FROM USERS WHERE LASTNAME = ?1", nativeQuery = true) Page<User> findByLastname(String lastname, Pageable pageable); }
3.3.3 开启查找Repository
接下来,我们需要告诉Spring Data JPA 哪些是普通的接口类,哪些是Spring Data JPA Repository接口类。
3.3.3.1 方式一 使用@Repository注解标记为Repository
@Repository
interface PersonRepository extends JpaRepository<Person, Long> {
List<Person> findByLastname(String lastname);
}
Spring Data JPA 支持使用Java Config 来开启包扫描
为此,我们需要创建一个Java Config 类,然后使用@EnableJpaRepositories注解
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@EnableJpaRepositories
@Configuration
public class JpaConfig {
}
- 请注意,我们这里
@EnableJpaRepositories注解并没有显式配置程序包,因为默认情况下Spring Data JPA 会查找使用了@Repository注解的接口类
3.3.3.2 方式二 Java Config类中使用@EnableJpaRepositories查找Repository
方式一那种写法其实存在个缺点,如果我们的项目中一个类继承了JpaRepository,另外一个类继承了MongoRepository,那么程序启动可能就会报错,因此我们最好指明使用Jpa存储库的包路径,像下面这样:
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@EnableJpaRepositories(basePackages = "com.acme.repositories.jpa")
@Configuration
public class JpaConfig {
}
3.3.3.3 方式三 使用XML 配置方式查找Repository
如果不喜欢用上面的 Java Config 方式,也可以使用传统的xml配置方式
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
https://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.repositories"/>
</beans
3.3.4 调用Repository
最后我们开始调用我们的Repository(存储库)方法
示例代码如下:
class SomeClient {
private final PersonRepository repository;
SomeClient(PersonRepository repository) {
this.repository = repository;
}
void doSomething() {
List<Person> persons = repository.findByLastname("Matthews");
}
}
但是我们其实一般都不这么用。。。
个人感觉比较优雅的一种方式是这种:
class SomeClient {
@Autowired
PersonRepository repository;
void doSomething() {
List<Person> persons = repository.findByLastname("Matthews");
}
}
0x04 项目信息
0x05 参考资料
本节完~
下篇预告,Spring Boot with Spring Data JPA Sample
- 交流即分享,分享才能进步 by 星云
- 如果你喜欢我的博文,欢迎点赞+关注~