在GPU避免分支的方法
Authored by Brandon Fogerty(XR Graphics Engineer at Unity Technologies.) with Additional Organized by JP.Lee(李正彪)[email protected]

概要
这边来稿文章中,希望了解如何编写GPU着色器友好型代码,以避免和分支相关的性能费用。
"分支"有着什么意义?
使用明确的 if / then随时都可以产生分支。编译器遇到条件会作出命令。GPU可去的地方有两处。
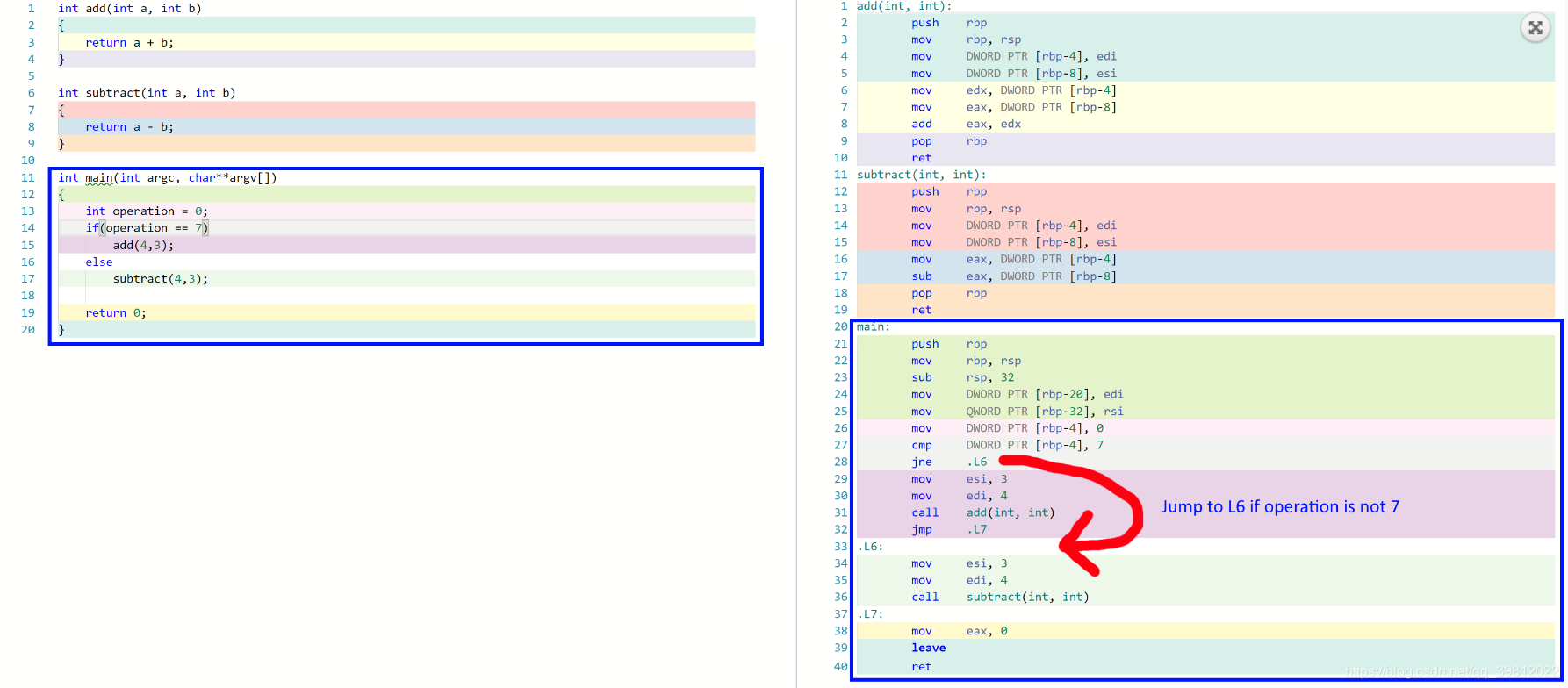
因此需要决定要使用哪种代码路径。以下示例展示了在汇编GPU里面运行的示例。
运算变量设置为幻数7,则添加该数字。否则的话要减掉。
为什么要避免分支?
为了增加CPU使用率,大多数计算机都尝试在管线上执行尽可能多的任务。汇编指令按顺序执行,CPU会尝试在尽可能多的CPU内核上执行尽可能多的指令。举个简单的例子。
想象一下,在Twilight Zone内,我们就是世界上最高效的程序员!
用两行代码写了电子游戏!
CPU会尽可能在每一个CPU内核上各执行一个,共计两个光荣的指令。
这是计算机能够更有效的运行代码。
但是在分支时,计算机可能会花时间准备未运行的代码结果。从结论上看处理器时间被浪费,影响了游戏或应用程序的应答能力。
CPU 侧分枝误诊通常会导致周期遗漏超过40次。– Charles Sanglimsuwan (集成开发人员相关工程师)
运气不错,最新的CPU处理器速度惊人,实际分支预测出色,因此分支错失几乎不会有问题。
但是GPU仍然存在性能问题。
GPU尝试并行解决大量计算,因此大部分GPU不支持分支预测
GPU为什么会发生性能问题?
GPU为生成美丽的图像,喜欢并行进行很多工作!
GPU为进行多种固有的结果计算,进行了精心设计,解决了通过单一滤镜(例如:着色器程序)实施的多种输入和相关的问题。
这就是渲染经常使用GPU(Graphics processor units)的原因。通过几个Shader程序运行位置,法线,贴图坐标等具有不同属性的固有顶点,该Shader程序输出在画面上表现的大量固有像素颜色。
举个例子,显示器是1080 × 960这样的一般HD像素的情况下,GPU在一组输入时,将计算1080 × 960 = 1,036,800个的固有像素颜色值!
那是很多的计算结果!
想象一下在1080x960的高清游戏体验。游戏尝试每秒渲染60个固有的图像或帧。因此GPU在1秒之内需要计算1080x960x60以上的固有像素颜色值!
结论上看一秒之内可以计算62,208,000个固有像素值!
撰写本文的节点,NVDIA最现金的GPU是GeForce RTX 2080 Ti。它有着比英特尔最先进的CPU处理器i9-7980XE更多4,352个Cuda内核,18个内核。
非常大的差异吧?
GPU有大量的处理内核,但是与最新的CPU相比,其核心处理数量仍不足百万。
至少目前还没有!显卡在物理上太大了,可能会很昂贵。
因此,GPU将尝试对要解决的问题类型进行特定假设。GPU充分利用SIMD。SIMD表示单个命令的多种数据。SIMD允许以并行方式为多个输入运行计算。SIMD通常希望输入和输出位于相邻的内存块中。因此SIMD操作不必加载每个输入并单独保存每个结果,而是加载输入并将结果保存为单个加载/保存操作,从而减少昂贵的内存加载和保存。SIMD的使用要求内存布局严格,并在应用程序设计中维持更好地内存缓存一致性上有积极作用。SIMD在CPU和GPU均可使用.
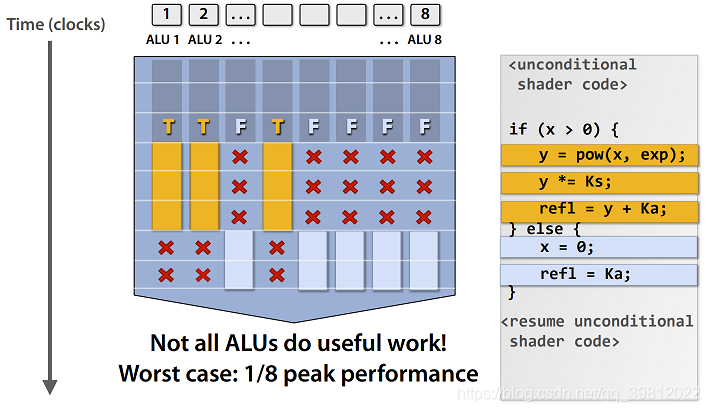
在CPU使用SIMD的示例可参考此处。与CPU程序不同,GPU程序几乎始终使用SIMD。为了充分利用SIMD,GPU通常每个内核都有很多ALU。ALU是算术逻辑设备的缩写。ALU执行数学命令。举个例子,使用“add 4, 3”命令计算结果7。因此,单一内核上有8个ALU的话,就可以同事并行运行8个计算。即,单一GPU内核有8个ALU,则单个GPU内核则可以同事计算8个像素值!但是,着色器阶段使用动态分支会发生什么呢?核心是必须执行所有代码路径,并最终丢弃不满足条件的代码路径。这意味着ALU会浪费时间执行任何未使用的操作。也就是说渲染图像需要更长的时间。
使用示例:
在Unity里,使用立体shader以保证双眼能够准确渲染。左眼以绿色表示渲染,右眼渲染的显示为红色。下面是使用立体shader渲染双眼锁渲染的单个球体。
针对此的纯接近方式是基于unity_StereoEyeIndex变数的条件方法。
Shader "XR/StereoEyeIndexColor"
{
Properties
{
_LeftEyeColor("Left Eye Color", COLOR) = (0,1,0,1)
_RightEyeColor("Right Eye Color", COLOR) = (1,0,0,1)
}
SubShader
{
Tags { "RenderType" = "Opaque" }
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
float4 _LeftEyeColor;
float4 _RightEyeColor;
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 vertex : SV_POSITION;
UNITY_VERTEX_OUTPUT_STEREO
};
v2f vert (appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_INITIALIZE_OUTPUT(v2f, o);
UNITY_INITIALIZE_VERTEX_OUTPUT_STEREO(o);
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i);
if(unity_StereoEyeIndex == 0)
{
return _LeftEyeColor;
}
return _RightEyeColor;
}
ENDCG
}
}
}
分段shader的集合输出如下:
Shader hash 084f3be2-e9e6b34f-66f52d0a-1b95fab0
ps_4_0
dcl_constantbuffer cb0[2], immediateIndexed
dcl_input_ps_siv v1.x, rendertarget_array_index
dcl_output o0.xyzw
0: if_z v1.x
1: mov o0.xyzw, cb0[0].xyzw
2: ret
3: endif
4: mov o0.xyzw, cb0[1].xyzw
5: ret
注意从0行开始的分支。分段shader stage上指定的内核将强制所有ALU执行两个条件结果。
但是不满足条件的结果将被丢弃。这种情况,可能是一部分ALU执行了被浪费的操作。我们刚刚让几种ALU很伤心,现在他们提出了他们为什么需要存在。
不要让可怜的小ALU做很忙的工作了。(✖╭╮✖)
你肯定不喜欢浪费时间吧?用ALU做一些游泳的事情吧。
如果能够去掉条件部,可以减少浪费,让ALU更有效率,更加幸福!
以下示例演示了分段着色器的实现方式:
Shader "XR/StereoEyeIndexColor"
{
Properties
{
_LeftEyeColor("Left Eye Color", COLOR) = (0,1,0,1)
_RightEyeColor("Right Eye Color", COLOR) = (1,0,0,1)
}
SubShader
{
Tags { "RenderType" = "Opaque" }
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
float4 _LeftEyeColor;
float4 _RightEyeColor;
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 vertex : SV_POSITION;
UNITY_VERTEX_OUTPUT_STEREO
};
v2f vert (appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_INITIALIZE_OUTPUT(v2f, o);
UNITY_INITIALIZE_VERTEX_OUTPUT_STEREO(o);
o.vertex = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i);
return lerp(_LeftEyeColor, _RightEyeColor, unity_StereoEyeIndex);
}
ENDCG
}
}
}
没有明确的条件,仔细看下HLSL组件输出。
Shader hash 7f0a4d98-21be8f11-77007603-2899b3a0
ps_4_0
dcl_constantbuffer cb0[2], immediateIndexed
dcl_input_ps_siv v1.x, rendertarget_array_index
dcl_output o0.xyzw
dcl_temps 2
0: utof r0.x, v1.x
1: add r1.xyzw, -cb0[0].xyzw, cb0[1].xyzw
2: mad o0.xyzw, r0.xxxx, r1.xyzw, cb0[0].xyzw
3: ret
再一次确认也是!没有分支!
我们现在使用的不是明确的条件部,而是Lerp。
lerp在两个值之间执行线型插值。
Lerp本质上是:
float lerp( float a, float b, float t)
{
return (1.0f-t)*a + t*b;
}
如组件输出所示,lerp会转换一些比乘法和分支更好地附加输出。基本上会向lerp函数提供两个任意值,传递第三个参数"t value"。t值一般是易于操作的空间数0.0和1.0之间的数字。
t值为0.0,结果为a。如果t值为1,则结果为b。
t值介于0.0和1.0之间的话,结果将在a和b之间线性显示。
对于我们来说,我们知道unity_StereoEyeIndex是左眼或者右眼分别是0或者1。
因此,这可以很好的操作,并可以避免明确的分支。
避免分支的其他方法是什么?
默认情况下,我们希望得到的是将条件转换为数学方程式。为了帮助实现这个目标,我们继续介绍HLSL硬件加速功能。
step(y,x)
x 参数比y参数大或者一样的话,1;反之则是0。
lerp(x,y,t)
线性插值结果。
min(x,y)
x或者y参数中最小的值。
max(x,y)
x 或者y参数中最大的值。
Lerp尝试在某些条件下返回两个不同的任意值时最方便。
这一步骤对于Boolean运算非常有用。如果这是真的,你可能还会想要返回一些东西,例如假设你有以下功能:
// The enable parameter should be either 0 or 1
// If enable is 1, then the color blue is returned. Otherwise the color black is returned.
// If you add the result of AddBlueTint to your final color and black is returned,
// your original color will remain unchanged.
float3 AddBlueTint( float enable )
{
return step(0.5, enable) * float3(0,0,1);
}
float3 finalColor = someColor + AddBlueTint(1.0);
也可以修改立体声shader并使用step代替lerp。
fixed4 frag (v2f i) : SV_Target
{
UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i);
return step(unity_StereoEyeIndex, 0.5) *_LeftEyeColor + step(0.5, unity_StereoEyeIndex) * _RightEyeColor;
}
那样的话,HLSL汇编如下所示:
Shader hash e56cb1bf-ce5441de-72c92b9d-336cc956
ps_4_0
dcl_constantbuffer cb0[2], immediateIndexed
dcl_input_ps_siv v1.x, rendertarget_array_index
dcl_output o0.xyzw
dcl_temps 2
0: utof r0.x, v1.x
1: ge r0.y, r0.x, l(0.500000)
2: ge r0.x, l(0.500000), r0.x
3: and r0.xy, r0.xyxx, l(1.000000, 1.000000, 0.000000, 0.000000)
4: mul r1.xyzw, r0.yyyy, cb0[1].xyzw
5: mad o0.xyzw, r0.xxxx, cb0[0].xyzw, r1.xyzw
6: ret
再一次…
没有分支!SIMD shader汇编命令"ge"不是分支。基本条件下,HLSL阶段命令在shader汇编中进行转换。ge是计算输入值是否大于或等于其他输入值的命令,并根据结果返回值1或者0。使用多阶段函数,可以根据输入值是都在特定范围内儿返回结果。这一般称为"脉冲功能"(“pulse function” : The pulse function may also be expressed as a limit of a rational function)
例如可以考虑以下条件:
if(value >= 0.5 && value <= 1.0)
{
return float3(0,0,1);
}
使用2 阶段功能构成的脉冲功能。
float pulse(float value, float minValue, float maxValue)
{
return step(minValue,value) - step(maxValue, value);
}
float3 finalColor = float3(0,0,1) * pulse(0.4, 0.1, 0.5);
可以使用最小值/最大值去选择两个值中大或较小的值。这样的内置功能都转换为硬件加速功能或者与lerp相同的硬件加速功能。即,这些方法通过显卡的硅胶中烤制的逻辑回路进行转换或被转换。
删除条件的更多方法请关注Orange Duck的以下文章。GPU内核即工作方式的详细内容请参考一下UC Davis的演示。
附录. 1
GPU 运算方式
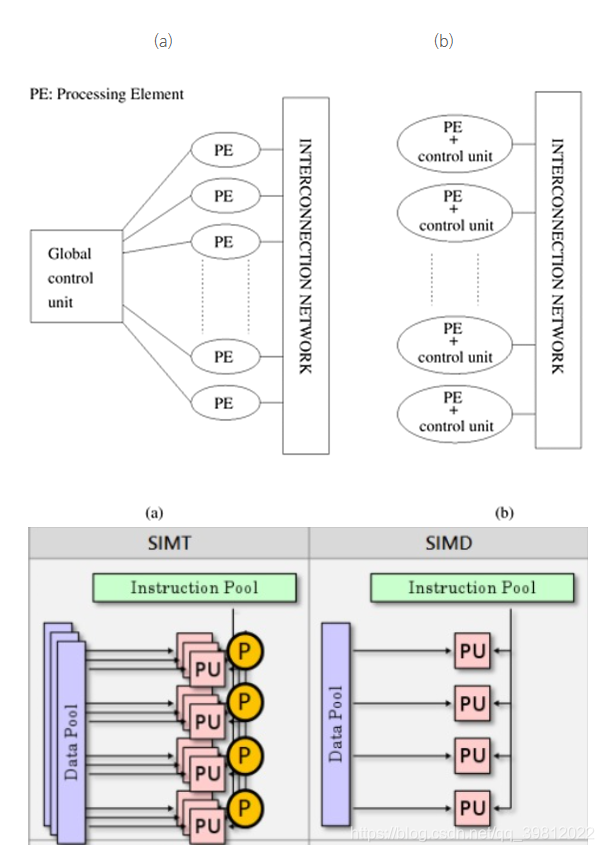
- SIMD, MIMD, SIMT
(a) SIMD(Single Instruction, Multiple Data): 用一个命令加工多个数据的计算。
(b) MIMD(Multiple Instruction, Multiple Data): 几个处理器内核运行各自独立的程序(命令 列),并各自处理数据。
© SIMT(Single Instruction, Multiple Thread): 用一个命令(NVIDIA GPU时)并行运行32个线程
*P(Predicate): 有一个寄存器用于记住上述的比较命令条件代码,使用各个命令的Fredicate比特和条件代码的匹配/不匹配控制是否忽略在运算其中执行命令。
SIMD
- 因为涉及到4各元素的向量,所以用相同的指令将4个运算器结合在一起的方法很有效。
- 如果只输入一个元素,运算器4个里面只会运行1个,剩余3个空闲,效率低。
- 另外,必须让按照一般顺序运行的程序执行不同的向量运算。
- 用CUDA或OpenCL编写程序时,SIMD用矢量化或详细的指令执行顺序等是编译器负责的,因此不需要程序员考虑。编译器无法保证可以生成所有的SIMD代码,可能会使性能降低。
- 命令供应是一个整体,各运算器都不需要命令供应,因此所需的晶体管数量很少,对比MIMD,面积要更小。
需要的硬件数量: MIMD > SIMT > SIMD
运行自由度: MIMD > SIMT > SIMD
GPU有从运行SIMD转变为运行SIMT的趋势。
- 一般情况下,CPU和GPU都有各自的内存。
- 通过DMA(Direct Memory Access)引擎,在两个内存之间传送数据。
- 这样的情况下,每次数据传送都需要在内存之间复制数据,但也会发生与‘深层复制’的情况一样的问题。
- 因此制作共同内存的空间成为了GPU制造商的重要研发目标。
CPU => 需要大容量内存(CPU数十GB / GPU数GB)
GPU => 需要高带宽内存以支持高计算性能
4. GPU的3D图像处理需要大量计算,因此GPU需要搭载比通用CPU更多的浮点运算器
因此产生了将这样的运算能力运用到科技计算的需求,GPU的适用范围更广了。
e.g.) 利用生物分子系统功能控制,建立个新的制约基础时
- 生物体组织等按照分子原子的水平模型化
- 模拟与药物的互动产生怎样的结果
- 原子层面上,为计算移动的力量,因为原子数量大,需要大量的计算
诸如科技计算,图像识别,语音识别等研究趋势将数据分成更小的单位进行分析,精密度准确度也越来越高。
因此需要更多的计算,使用GPU的并行计算已经成为处理的重心。
附录 2.
Warp Execution
Warp是执行GPU Instruction的最基本单位。Warp的所有Thread只执行一个相同的Instruction。但是Warp的各Thread都可以读取不同的数据值。因此可以认为Warp的每个Thread使用相同的Instruction不同的数据值来执行运算。这种运算方法被称为SIMD (Single Instruction Multiple Data) 或者SIMT (Single Instruction Multiple Thread)。
SIMD和SIMT有一点差异。SIMD可以看做是执行Vector运算。要执行SIMD运算,为了执行Vector运算需要Instruction。而SIMT则是在编写程序时,根据一个Thread来编写。而且硬件是将几个Thread组合在一起来执行运算。
从Volta Architecture开始,Warp的Thread可以执行相互独立的运算。没有详细的阅读Volta Architecture,所以操作方法不是很清楚下次打算整理一下Volta或Turing Architecture(出处1, 2)
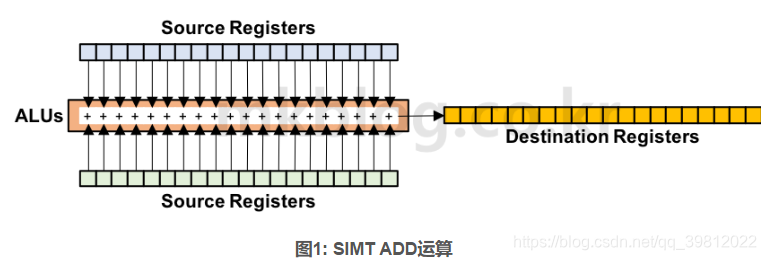
图1显示了使用SIMT运算方法执行ADD运算。32个Thread有独立的存储空间(Register)。为了执行ADD运算,每个Thread从两个Source Register加载Data值。执行ADD运算之后得到的结果存储在其他32个Destination Register。结果上看一个Warp将访问64个Source Register,并将运算结果值存储在32个Register里面。Warp的所有Thread都为了执行同样的运算,之家在一个Instruction。准确的说,在被调度时要执行相同的运算的Instruction执行了Broadcasting,同时所有的Thread执行被Broadcasting的一个Instruction。
通常一个SM (Streaming Multiprocessor)有48个64个的Warp。每个SM一般有数十数百个的运算器(ALU),可同时进行2~4个Warp Instruction。每个SM的Warp总数,ALU个数等因GPU Architecture的不同而略有不同。GPU与CPU一样使用Pipeline执行Instruction。通常GPU由5个Pipeline Stage组成,分别是Instruction Fetch, Decode, Issue, ALU&Memory, Writeback格式。(出处 3)
从Turing GPU Architecture开始 Integer, Floating运算器已经分离了。以前Architecture的情况下,Integer, Floating Point运算都在一个ALU里面执行了。
GPGPU-Sim是对NVIDIA GPU进行建模的计算器Architecture模拟器。用C, C++写的。虽然模拟器陈旧,但是因为没有比这个更好地选择,所以很多研究室都是用相应模拟器编写论文。
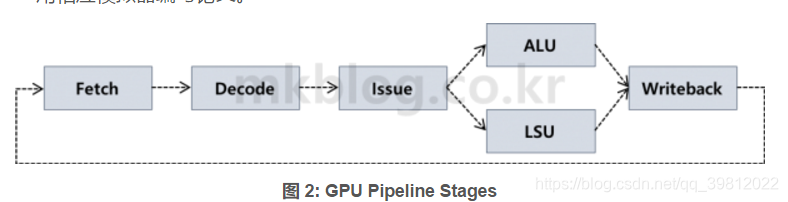
图2展示了5个Pipeline Stage。以下是对各Stage的说明。
Fetch: Fetch阶段使用PC (Program Counter)的值加载Instruction。最近的GPU,与CPU一样使用64-Bit Instruction。Fetch Instruction的顺序是Round-Robin方式。用Warp 0, 1, 2, ….的顺序Fetch Instruction。
Decode: Decode阶段是为执行在内存里面加载的Instruction执行ALU/Memory运算而查找运算Type及需要的Register的阶段。 Decode Instruction存储在Instruction Buffer中。GPU由不同的逻辑计算,如Integer, Floating Point, Special Function, Memory。
Issue: 是用运算器发送Decode Instruction的阶段。在此阶段中,运算所需的数据值在Source Register读取。在Source Register读取的值发送到ALU,ALU将执行运算。一般情况下,Instruction Fetch/Decode的速度(?)因为比Instruction Issue的速度快,所以到了这个阶段Decode的(可能的Issue)Warp个数多的概率会很高。所以Warp Scheduler选择Issue的Warp。众所周知Warp Scheduling技术有Round-Robin (RR)和Greedy-Then-Oldest (GTO)方式。SM平均有2~4个Warp Scheduler,所以每个周期会进行2~8个Warp Instruction Issue。Issue Instruction可在ALU/LSU执行运算。根据运算类型,Instruction会在数十个周期内需要数百周期的运算时间。
RR Warp Scheduling是从几个Warp中用ALU组成的Warp的顺序,依次选择的方法。例如,假设SM中有24个Warp,并且所有Warp都已经准备好了运行Instruction。Warp 0, Warp 1, …, Warp 23在ALU里面依次出现一个Instruction,是Issue的形态。
GTO Warp Scheduling方法已经执行了在Warp 0号可执行Instruction。如果没有准备好的Warp 0的可执行Instruction(Stall发生的情况),则选择下一个准备好的Warp来进行Instruction Issue。下一个选择的Warp选择现在Stall Warp的下一个ID的 Warp。例如,Warp 3号没有可执行的 Instruction,则4号Warp Instruction将成为Issue。
ALU&Memory: 使用从Source Register读取的值执行运算。根据Instruction类型,使用Load/Store Unit (LSU), ALU, Special Function Unit (SFU)运算器。ALU执行Integer, Floating Point运算。SFU执行一些有些复杂的指令,如Sin, Cos等。LSU执行内存运算。…
Writeback: 是将在ALU, LSU, SFU运算的值存储在Destination Register的阶段。
GPU执行上述5个阶段的Warp Instruction。一般Computer Architecture书里面介绍的5阶段Pipeline Stage和它几乎相同。
出处
https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
http://www.gpgpu-sim.org/
附录3.
GPU Branch Divergence
GPU将Thread绑定为32或64个,执行一个相同的Instruction。Branch Divergence发生在属于Warp的Thread必须执行不同的操作时。例如,属于Warp的Thread偶数ID必须执行与IF语句相对应的代码,而为奇数ID的Thread必须执行ELSE相对应的代码,就会发生Branch Divergence。以下代码是检查Thread ID是否为奇数,并运行不同代码的示例(未验证)。
__global__ void mkTest(){
int threadID = threadIdx.x
if((threadIdx.x % 2) == 0){
Even number Thread code...
}
else{
odd number Thread code...
}
}
图1表示了发生Branch Divergence的情况下,Warp执行的顺序。简而言之,Warp依次执行IF和ELSE等代码。执行与IF相应的代码运算时,不需要IF运算的Thread运算除外。相反,执行ELSE相应的运算时,不需要ELSE运算的Thread将从运算中除外。不知道运算中去除的正确方法。也有不完全执行运算的方法,相反也有执行运算但是不在Register使用结果值的方法。有效的方法是不执行计算本身。
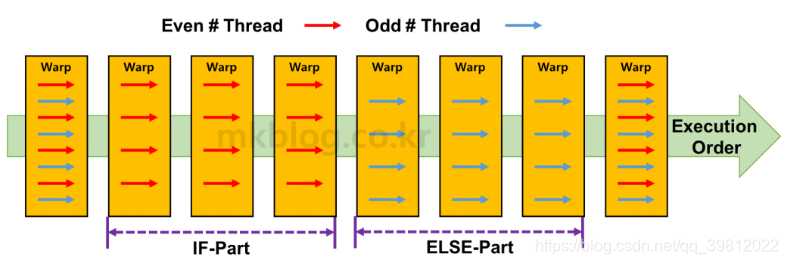
图 1: Branch Divergence发生的情况下,执行Warp的顺序
因此当发生Branch Divergence时,GPU将按序执行IF/ELSE相应的代码。因为Warp的所有Thread不会同时执行运算,所以GPU的Utilization下降。因此在使用GPU编程时,最好减少Branch Divergence。有事是在将IF/ELSE除以Thread ID/Block ID/Grid ID时,最好添加一到两个不同的运算来删除Branch Divergence。GPGPU早期(2010年左右),进行了很多从HW中删除Branch Divergence的研究。例如,当发生Branch Divergence,将Warp的Thread变成其他的Warp Thread。在研究生时期读论文的时候,我觉得这是个很酷的想法。但是,现在回想起来在性能上应该不会有很大的益处。最大的原因是Register值读取的速度急速变慢,所以可能实际性能并不会像论文中说的那么好。此外也有很多在编译阶段解决Branch Divergence问题的研究发布。很多论文发表意味着Branch Divergence对GPU的性能有很大的影响。
根据GPGPU-Sim的说法,使用SIMT Stack硬件逻辑Handling Branch Divergence(出处 1)。每个Warp都有一个名为SIMT Stack的存储空间。SIMT Stack由几个Entry构成。根据论文内容,SIMT Stack由4个Entry构成(出处2)。每个Entry由PC (Program Counter) + 32Bit存储空间构成。如果PC是64 Bit,每个Entry由92 Bit构成。PC后面的32 Bit用于存储True/False值,即属于Warp的Thread是执行还是不执行与PC相对应的Instruction。对于NVIDIA GPU,由于Warp由32个Thread构成,因此使用32 Bit检查Thread的Instruction是否执行。但是如果Warp由64个Thread构成,则使用64 Bit检查是否执行Thread Instruction。
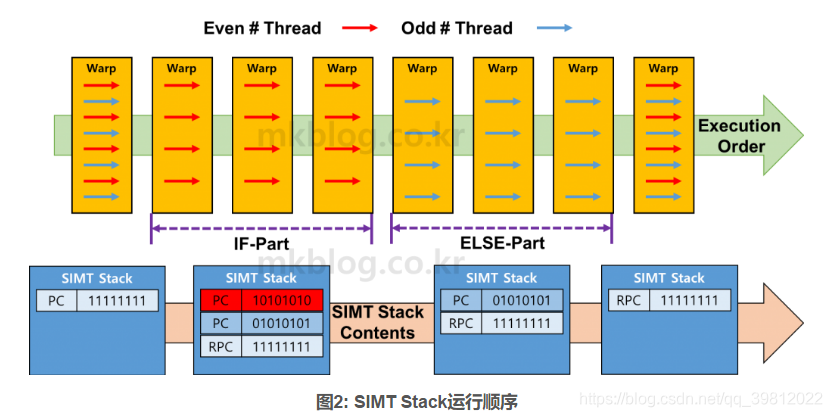
想了一下如何解释运行原理,似乎使用示例进行解释是最有效的。图2展示了Branch Divergence发生的情况下,使用SIMT Stack执行Instruction的方法。为方便起见,我们假设Warp是由8个Thread构成的。如前面示例代码所说,假设偶数ID Thread执行IF语句,奇数ID Thread执行ELSE语句。
Step 1: 在IF/ELSE之前,SIMT Stack有一个Entry。该Entry存储了PC值 + 11111111 值。PC值存储了Warp必须执行的下一个Instruction位置值。随后存储的 “11111111”意味着所有现存的Thread都必须执行与PC相对应的Instruction运算。
Step 2: 如果遇到IF/ELSE语句,总共会生成3个Entry。最上面存储IF语句相应的IF Instruction PC值 + “10101010”值,表示需要进行偶数Thread运算(因为是从0开始,第一个Thread标记为1)。以下Entry存储与ELSE语句Instruction相对应的PC值 + “01010101”值。最后存储完成了与IF/ELSE相对应的Instruction运算的PC 值 (RPC) + “111111111”。IF/ELSE语句完成后,Warp的所有Thread为了再次执行相同的Instruction而合并,称为 “Reconverge”。
Step 3: Stack这个名称可以得知,使用POP运算在SIMT Stack存储的Entry值。首先在SIMT Stack执行POP运算会得出与IF语句相对应的Entry。判断出IF语句相对应的PC值和Warp的Instruction运算是否需要后执行运算。标记为“1”的Thread执行其Instruction运算。反之,标记为“0”的Thread不执行。
Step 4: 与Step 3一样执行以下Entry运算。以下Entry是对应ELSE的Instruction的运算。
如果IF/ELSE的Instruction个数多于1,则更新PC值并将可执行的Thread信息再次保存至SIMT Stack。Stack遵循Last-In-First-Out (LIFO)顺序,因此执行所有相应于IF运算的Instruction运算,并按序执行ELSE相应的Instruction运算。
Step 5: IF/ELSE相应的Instruction全部执行后,SIMT Stack将只剩下具有Reconverge PC (RPC)值的Entry。该Entry被POP,Warp的所有Thread都执行相同的运算。
如上所述,Branch Divergence发生的话,使用SIMT Stack按序执行Instruction运算。发生Branch Divergence时,由于属于Warp的Thread无法执行Instruction,导致GPU的Utilization下降。此外,由于执行了IF/ELSE等相应的所有Instruction,GPU必须要执行的Instruction的个数增加了。总之,最重要的是要确保在编程过成功不发生Branch Divergence。
出处
http://www.gpgpu-sim.org/
Stack-less SIMT Reconvergence at Low Cost
About JP
链接: Website.
在这里插入图片描述

出生在韩国的TA。
1997年开始从事电脑图形视觉化工作后,在这个行业已经有21年经验了。
在多个网络游戏公司引领过美术团队,之前在allegorithmic担任TA负责人,在中国网易盘古工作室担任TA总监,现在是巨人网络TA部门的总负责人。
懒惰的人才有创意”是他坚信并执行的哲学道理。