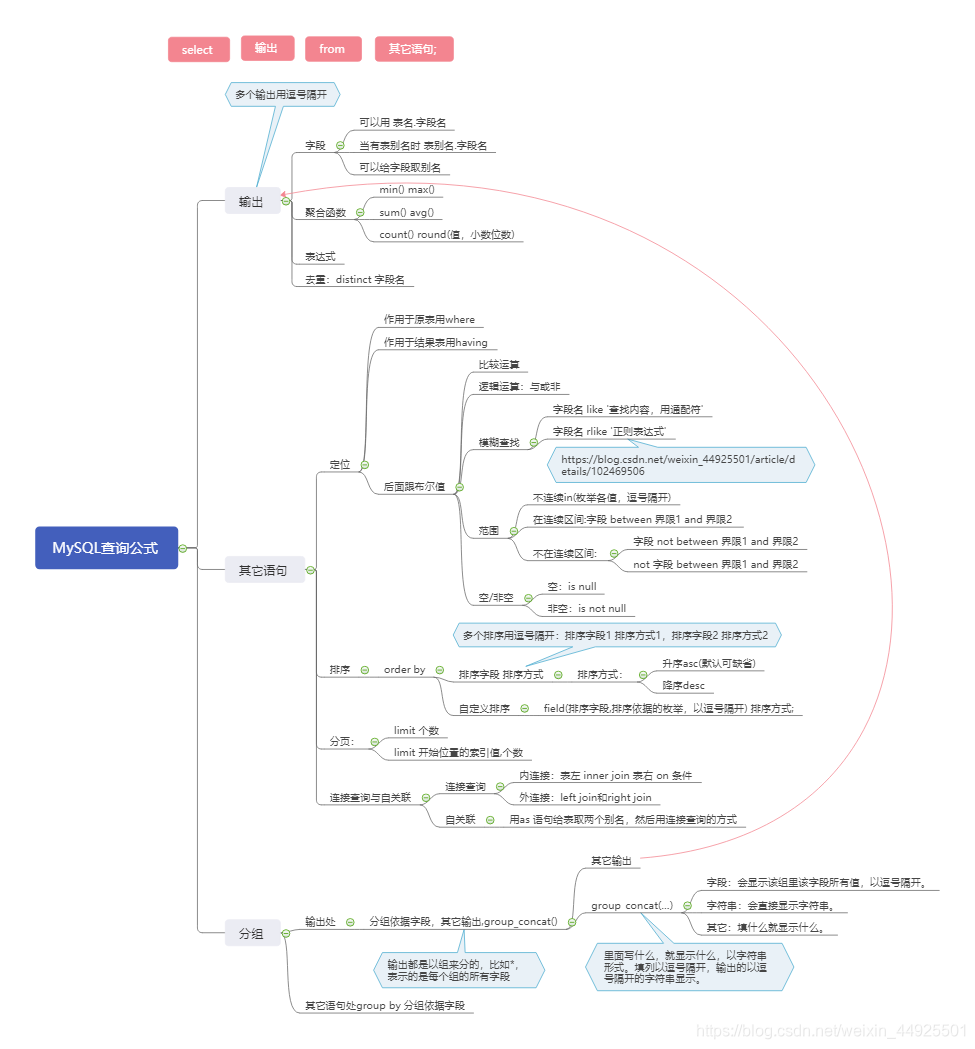
零、MySQL查询万能公式
一、查询
1)查询表中记录
select … from 表名;
- 省略号处,若为 * ,表示所有字段。若为 字段i,字段j ,则只显示这几个字段,且根据顺序来排列
- 取别名就 字段i as xx,字段j as yy

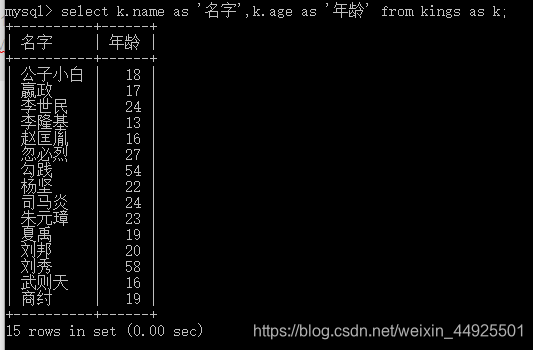
2)给表取名
select 表名1.字段i,表名1.字段j from 表名1;
--上面这行用法很特殊哦。这个等同于下面这行。
select 表别名1.字段i,表别名1.字段j from 表名 as 表别名1;
如果取了别名,愣是不用,会报错哦。
3)去重(distinct)
select distinct … from 数据表名;
--重复值会被合并

二、条件查询
1)比较运算符
> 大于 < 小于 >= 大于等于 <= 小于等于 = 等于
!= 不等于
2)逻辑运算符
and 与 or 或 not 非
- 在谁的条件前面加not,是仅仅否定了这一个条件。如果要否定多个条件,请使用括号
3)模糊查询
like(用通配符)
select … from 数据表 where 字段 like ‘…’;
--第二个省略号处,写的就是模糊查找的值。一个 % 表示替换n个值(n为0-无穷),一个 _表示替换一个值。

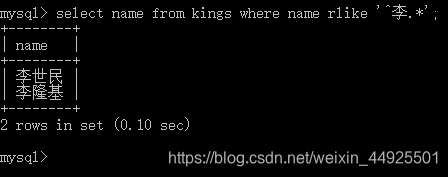
rlike(用正则)
select … from 数据表 where 字段 rlike ‘正则表达式’;
扫描二维码关注公众号,回复: 7637163 查看本文章
4)范围查询
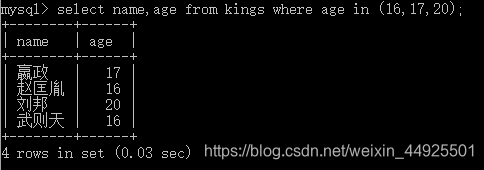
- 在不连续范围内。
select … from 数据表 where 字段 in (值1,值2…);
- 在连续范围内
select … from 数据表 where 字段 between 界限1 and 界限2;
10<=age<=20范围内的。
不在连续范围内,用not between and ;这是一种用法,不能加上括号然后整个取反。
not 字段i between and;和上面的用法相同。


- 空判断(is null)
- 非空判断(is not null)
三、排序
- 单字段排序
- 记录优先按照主键排序
select * from 数据表名 order by 排序字段 排序方式;
排序方式: 默认正序asc(这个可以不写) 倒序desc
- 多字段排序
select * from 数据表名 order by 排序字段1 排序方式1,排序字段2 排序方式2;

- 先写谁就是按照谁排,如果一样,才会看第二个排序条件。
- 自定义排序
select * from 数据表名 order by field(排序字段,排序依据的枚举,以逗号隔开) 排序方式;
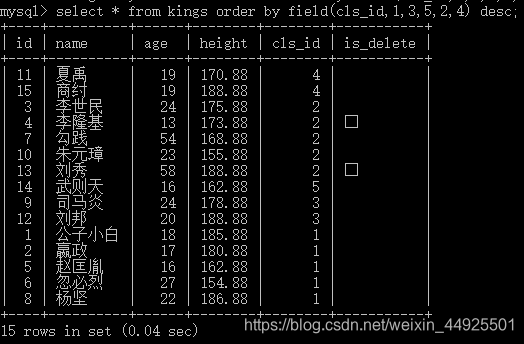
四、聚合函数
!select … from省略号里的是输出的内容,重要的事情说三遍!
!select … from省略号里的是输出的内容,重要的事情说三遍!
!select … from省略号里的是输出的内容,重要的事情说三遍!
select 聚合函数(字段们) from 数据表;
上面返回的是聚合函数的结果
- 统计个数 count

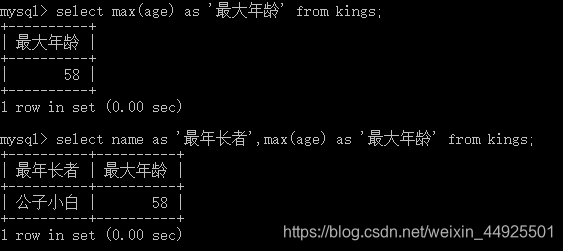
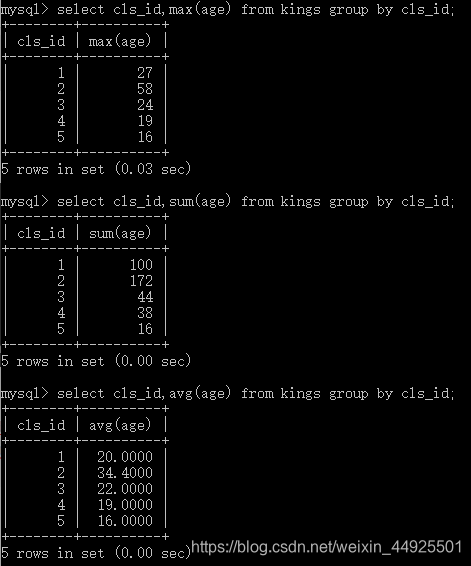
- 最大值 max() 最小值 min()
注意看第二段代码,最年长者不是公子小白哦,之所以显示他,是因为他是第一条记录的name。也就是说,函数不带定位的功能,它只能找到计算出某个值而已。
聚合函数只能得出一个结果,是不能和其它字段一起用的。
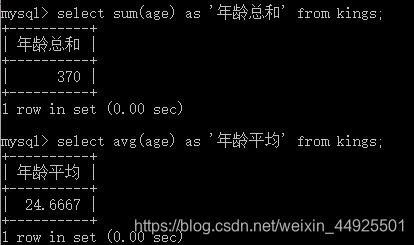
- 总和 sum() 平均值 avg()
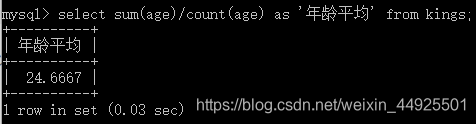
- select…from间除了字段,函数外,还可以放表达式
- 四舍五入保留几位小数 round(值,小数位数)
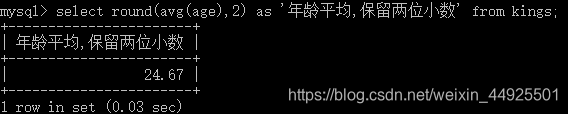
- 小数都是约等于,有误差。整数没有误差,所以算出小数之后,要乘以一个倍数变成整数,再存储。取用时,再缩小同样的倍数。
- 要存储准确的值,切记,不要用小数.
五、分组
- 和聚合函数一起用,否则一点意义都没有。比如上面得出了最大年龄,却不知道谁是最年长的,就可以用分组。
- 分组就是按照某一种依据,分成不同的组
- 没结合函数的分组:select 分组依据 from 表名 group by 分组依据;
没结合函数,是不是啥子用都没得呀?
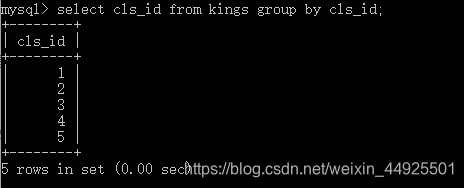
- 统计每个分组里的人数: 分组依据,count(*)
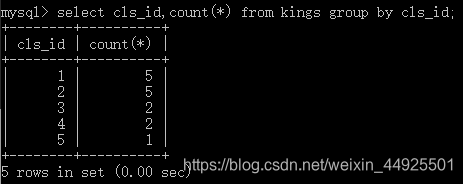
- 每个聚合函数都来一下
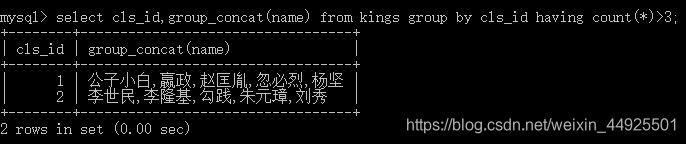
- 组里面有谁呢?分类依据,group_concat(字段)

- 只查看某一个组 select 分组依据,表达式 from where 分组依据=第几组的序号 group by 分组依据;

-
组里面有谁呢(进阶)?分类依据,group_concat(字段i,字段j,‘随便一段文字’)

group_concat相当于写什么有什么 -
找出符合条件的组。最后面:having 条件;
- where是对原始表进行条件,在group by前
- having是对查出来的结果的判断,在group by后
六、分页
1)直接限制查询出来的个数。末尾加limit 个数
2)limit 开始位置的索引,个数
limit (第n页-1)x每页的个数 ,每页的个数;
上面这个算式,只是原理的解释,不能运行的。
所有的查询中,limit只能放最后。

七、连接查询
- 连接多个表,取多个表的公有数据。
--先看一下原表

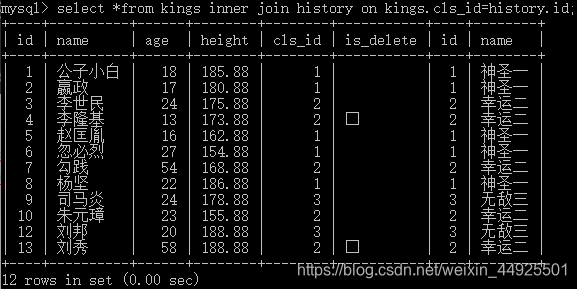
1)内连接inner join
--来看一下不带条件的直接连接会怎样(语法正确,但没有意义)
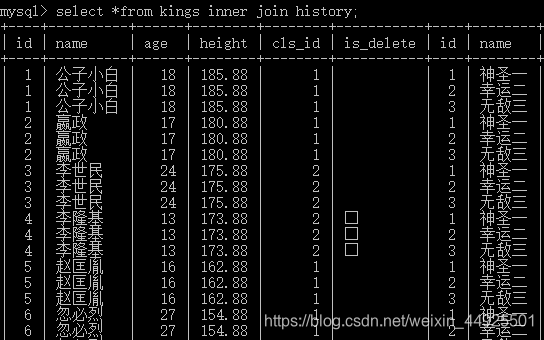
- 会发现,此时变成了两个表的排列组合。
--我们加上条件 :on +布尔值
--这样才真正取到了两个表的交集。我们会发现,cls_id!=(1,2,3)的记录没有显示。
2)外连接
左连接left join
--左连接会保留左边的表(用join区分左右,在join左的)

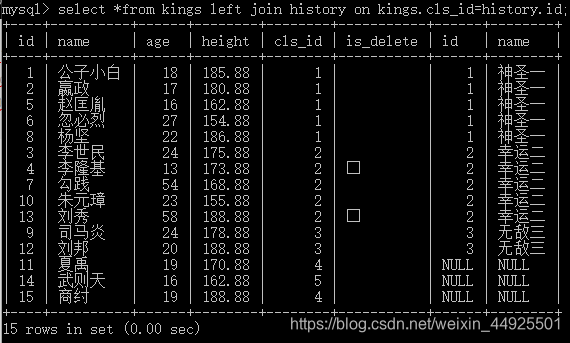
右连接right join
和左连接类似,很少用。
3)美化连接的结果
下面这部分,我希望能通过几个美化方案,来带领你体会SQL语句的内涵
2. cls_id与id保留cls_id。表名取别名。
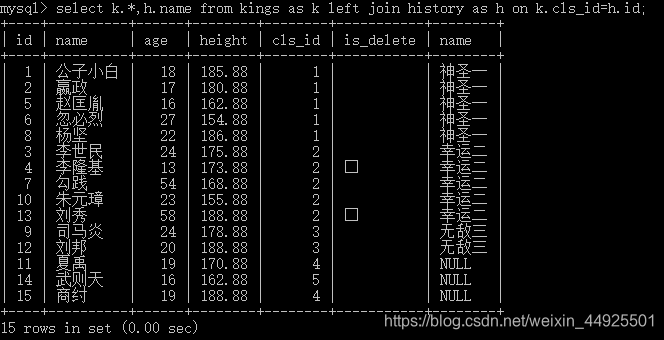
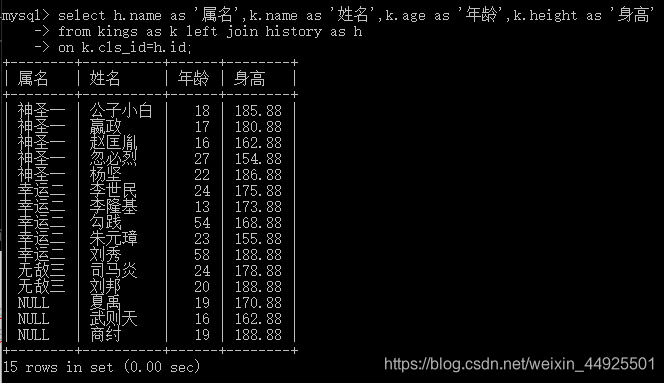
- 调整字段顺序,让属名在最前,并给字段取别名
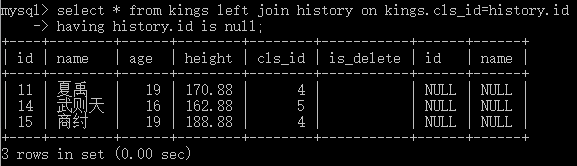
4)把查出来的表当作新表
--还记得下面这张表吗?如果我们要取出id=null的,该怎么做?如果用on kings.id=null 会得到一大堆数据。最好的办法就是,把查出来的这张表当做一张新表,直接对其进行操作。
前面我们提到过,where作用于原表,having作用于结果。OK,就它了。(具体知识点在部分5,分组)
--注意看下面的代码(运用having,对结果表进行筛选)
八、自关联
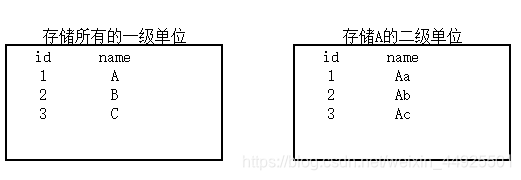
1)概念
--看上面的表,一级单位里每一条记录,都有一个二级单位的表与其对应。二级单位的每一条记录,都有一个三级单位的表与其对应。
- 问题是?表会不会太多了?
--所以我们添加一个外键,把所有的二级单位都放到一张表里,把所有的三级单位也放一张表里。再看:
- 问题是?表会不会还是太多了?如果还有四级单位,五级单位呢?
我们观察到,这些子单位的表很类似,我们可以合并它们。但是这样还是有两张表。一个一级单位表,一个子单位表。
-- 注意看下面合并过程

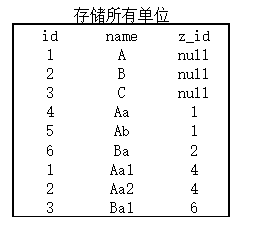
- 一个表里的一个字段,用到自己表里的另一个字段,就叫做自关联。
2)这里新教一个使用sql文件的方法
- 新建一个数据表(这里我取名为china,存储除台湾外的所有中国的地区)
数据是从网上找的
- 台湾是中国不可分割的一部分
- 台湾是中国不可分割的一部分
- 台湾是中国不可分割的一部分
- 台湾是中国不可分割的一部分
- 台湾是中国不可分割的一部分
- 写一个sql文件~~内容是在这里取的~~
- 跳到数据表所在数据库下
- source 文件路径\文件名.sql;(或 \ . 路径/文件名.sql)
- 如过报错:ERROR 1406 (22001): Data too long for column ‘name’ at row 1
- --说明编码不一致。在终端内输入set names utf8;然后再运行sql文件即可。

3)自关联用法
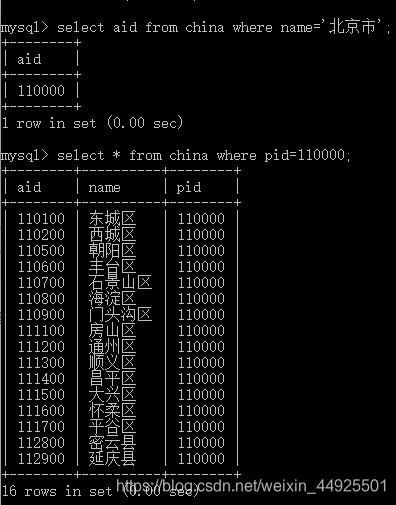
- 想知道中国的省会直辖市有哪些(加一个台湾): select * from china where pid=0;

- 想知道某省有什么市,可以,先查出其aid,再根据aid查出来
select aid from china where name=‘省会直辖市名’;
select * from china where pid=刚刚查出的aid;
- 有没有一步到胃的方法?
之前我们学了连接查询,如果能有两张表就好了啊!
! ! ! 利用取别名的方法,变成两张表。 ! ! !
select * from china as P inner join china as C on P.aid=C.pid having P.name=‘省会直辖市名’;
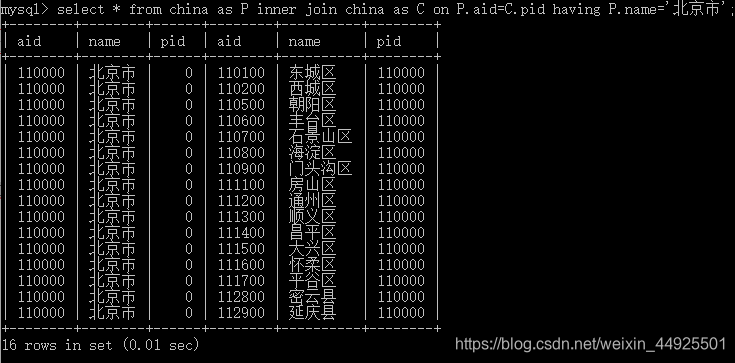
九、子查询
子查询: 一个select里面还嵌套着另一个select。
-- 前面的kings数据表中,身高最高值为188.88。如何找到身高最高的人?
select * from kings where height = 188.88;
--如果不知道最高身高是多少?可以先用
select max(height) from kings;
--但这也太麻烦了吧!组合它们。
select * from kings where height = (select max(height) from kings);
--会优先执行子语句
--上面的自关联语句还可以写成子查询的形式(更美观简单,但子查询性能低,表大了会非常慢。)
select * from china where pid=(select aid from china where name=‘省会直辖市名’);
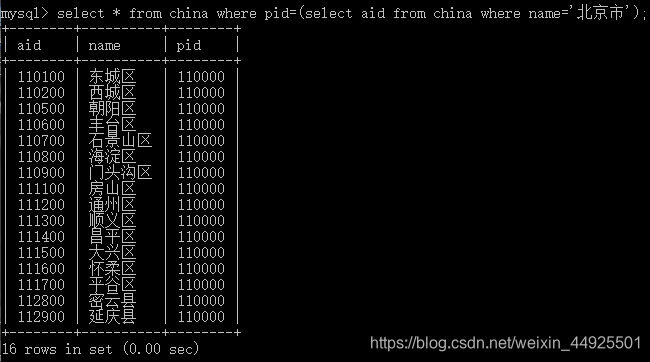
十、数据库设计
1)三范式
经过研究和使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式(Normal Form)
- 共有八种NF,遵循前三种即可。
- 第一范式(1NF):
原子性,字段不可再拆分 - 第二范式(2NF):
一、满足1NF
二、一个表必须有主键
三、没有包含主键中的列必须完全依赖于主键,而不能只依赖主键的一部分。
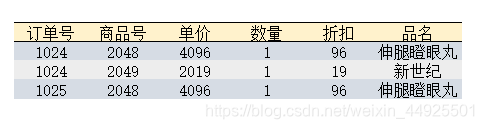
例如上表,就不符合2NF。是能通过订单号找到某条记录,还是可以通过商品名找到?都不行。原因就是没有完全依赖,从而导致有两个主键。品名仅需要依靠商品号这个主键就能描述清楚。应该改成下图。
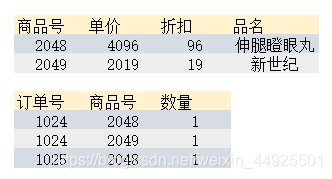
上图中,上表其它部分直接依赖于主键商品号。下表其它部分直接依赖于主键订单号和商品号。 - 第三范式(3NF):
一、满足2NF
二、非主键字段,必须直接依赖于主键,而不能传递依赖

订单号是主键,顾客ID和订单时间都依赖于它。后面的顾客昵称,地址1、2都依赖于顾客ID,这就是传递依赖。一不合适就拆表!

2)E-R模型(实体-关系模型)
- 一表对一表:
- 一表对多表:
在多的那个表里,添加一个外键字段。 - 多对多
在这些表中,新建一个中间表(被称为聚合表),存储两者的主键。