版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
html表格标签
| 标签 | 描述 |
|---|---|
| <table> | 表格 |
| <th> | 表格的表头 |
| <tr> | 表格的行 |
| <td> | 表格单元 |
| <caption> | 表格标题 |
| <colgroup> | 表格列的组 |
| <col> | 用于表格列的属性 |
| <thead> | 表格的页眉 |
| <tbody> | 表格的主体 |
| <tfoot> | 表格的页脚 |
极简版
font size=“5”
def save_html(ls_of_ls, prefix):
fname = prefix + '.html'
with open(fname, 'w', encoding='utf-8') as f:
f.write('<html><head><meta charset="UTF-8"></head><body><table border="1">\n')
for ls in ls_of_ls:
f.write('<tr>')
for i in ls:
f.write('<td><font size="5">{}</font></td>'.format(i))
f.write('</tr>\n')
f.write('</table></body></html>')
ls_of_ls = [['笑菊花', '深扣菊花舔指笑,菊花一闪误终身'], ['菊花红', '接天莲叶无穷碧,硬日菊花别样红']]
save_html(ls_of_ls, '菊花')

详细版(+列名)
def save_html(table, prefix):
fname = prefix + '.html'
with open(fname, 'w', encoding='utf-8') as f:
f.write('<html><head><meta charset="UTF-8"></head><body>\n')
f.write(table)
f.write('</body></html>')
def make_table(ls_of_ls, fields=None):
th = '<tr>%s</tr>\n' % ''.join('<th>{}</th>'.format(i) for i in fields) if fields else ''
tr = '\n'.join(
'<tr>' + ''.join('<td>{}</td>'.format(i) for i in ls) + '</tr>'
for ls in ls_of_ls)
return '<table border="1">\n%s\n</table>' % (th + tr)
ls_of_ls = [['笑菊花', '深扣菊花舔指笑,菊花一闪误终身'], ['菊花红', '接天莲叶无穷碧,硬日菊花别样红']]
fields = ['title', 'article']
save_html(make_table(ls_of_ls, fields), '菊花')

<html><head><meta charset="UTF-8"></head><body><table border="1">
<tr><td><font size="5">笑菊花</font></td><td><font size="5">深扣菊花舔指笑,菊花一闪误终身</font></td></tr>
<tr><td><font size="5">菊花红</font></td><td><font size="5">接天莲叶无穷碧,硬日菊花别样红</font></td></tr>
</table></body></html>
更详细版(+跨行)
td rowspan=“3”
def save_html(table, prefix):
fname = prefix + '.html'
with open(fname, 'w', encoding='utf-8') as f:
f.write('<html><head><meta charset="UTF-8"></head><body>\n')
f.write(table)
f.write('</body></html>')
def make_table(tb, fields=None):
th = '<tr>%s</tr>\n' % ''.join('<th>{}</th>'.format(i) for i in fields) if fields else ''
return '<table border="1">\n%s\n</table>' % (th + tb)
def make_tr_by_ls(ls_of_ls):
return '\n'.join(
'<tr>' + ''.join('<td>{}</td>'.format(i) for i in ls) + '</tr>'
for ls in ls_of_ls)
def make_tr_by_dt(dt_of_ls):
# tr = ''
# for k, v in dt_of_ls.items():
# le = len(v)
# for i in range(le):
# tr += '<tr>'
# if i == 0:
# tr += '<td rowspan="%d">%s</td>' % (le, k)
# tr += '<td>%s</td>' % v[i]
# tr += '</tr>\n'
# return tr.strip()
return '\n'.join(
'<tr>%s<td>%s</td></tr>' % ('<td rowspan="%d">%s</td>' % (len(v), k) if i == 0 else '', v[i])
for k, v in dt_of_ls.items()
for i in range(len(v)))
dt_of_ls = {'苹果': ['苹果醋'], '华为': [], '小米': ['小米粥', '小米蛋', '小米肠']}
fields = ['title', 'article']
tr = make_tr_by_dt(dt_of_ls)
tb = make_table(tr, fields)
save_html(tb, '手机')

<html><head><meta charset="UTF-8"></head><body><table border="1">
<tr><th>title</th><th>article</th></tr>
<tr><td rowspan="1">苹果</td><td>苹果醋</td></tr>
<tr><td rowspan="3">小米</td><td>小米粥</td></tr>
<tr><td>小米蛋</td></tr>
<tr><td>小米肠</td></tr>
</table></body></html>
更更详细版(列数>2)
def save_html(table, prefix):
fname = prefix + '.html'
with open(fname, 'w', encoding='utf-8') as f:
f.write('<html><head><meta charset="UTF-8"></head><body>')
f.write(table)
f.write('</body></html>')
def make_table(tb, fields=None):
th = '<tr>%s</tr>\n' % ''.join('<th>{}</th>'.format(i) for i in fields) if fields else ''
return '<table border="1">\n%s\n</table>' % (th + tb)
def make_tr_by_dts(dt_of_lss):
# tr = ''
# for k, v in dt_of_lss.items():
# le = len(v)
# for i in range(le):
# tr += '<tr>'
# if i == 0:
# tr += '<td rowspan="%d">%s</td>' % (le, k)
# for j in v[i]:
# tr += '<td>%s</td>' % j
# tr += '</tr>\n'
# return tr.strip()
return '\n'.join(
'<tr>%s%s</tr>' % ('<td rowspan="%d">%s</td>' % (len(v), k) if i == 0 else '',
''.join('<td>%s</td>' % j for j in v[i]))
for k, v in dt_of_lss.items()
for i in range(len(v)))
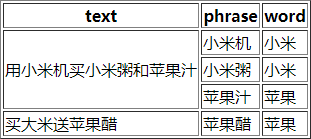
fields = ['text', 'phrase', 'word']
dt_of_lss = {
'用小米机买小米粥和苹果汁': [('小米机', '小米'), ('小米粥', '小米'), ('苹果汁', '苹果')],
'买华为送大米': [],
'买大米送苹果醋': [('苹果醋', '苹果')],
}
tr = make_tr_by_dts(dt_of_lss)
tb = make_table(tr, fields)
save_html(tb, '手机')
NLP版(NER)
from jieba import tokenize
replace_html_tag = lambda word: '<font color="red">' + word + '</font>'
replace_word = lambda sentence, word, head, tail: sentence[:head] + word + sentence[tail:]
def save_html(table, prefix):
fname = prefix + '.html'
with open(fname, 'w', encoding='utf-8') as f:
f.write('<html><head><meta charset="UTF-8"></head><body>')
f.write(table)
f.write('</body></html>')
def make_table(tb, fields=None):
th = '<tr>%s</tr>\n' % ''.join('<th>{}</th>'.format(i) for i in fields) if fields else ''
return '<table border="1">\n%s\n</table>' % (th + tb)
def make_tr_by_dts(dt_of_lss):
return '\n'.join(
'<tr>%s%s</tr>' % ('<td rowspan="%d">%s</td>' % (len(v), k) if i == 0 else '',
''.join('<td>%s</td>' % j for j in v[i]))
for k, v in dt_of_lss.items()
for i in range(len(v)))
# NLP
fields = ['text', 'phrase', 'word']
texts = ['买小米机,送了袋小米和苹果', '诺基亚', '买华为送苹果']
entities = {'小米', '苹果'}
dt_of_lss = dict()
for text in texts:
dt_of_lss[text] = []
for sentence in text.split(','): # 切句
for word, head, tail in tokenize(sentence): # 分词+位置
if word in entities: # NER
dt_of_lss[text].append([
replace_word(sentence, replace_html_tag(word), head, tail),
word
])
tb = make_table(make_tr_by_dts(dt_of_lss), fields)
save_html(tb, '手机')
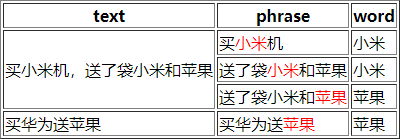
<html><head><meta charset="UTF-8"></head><body><table border="1">
<tr><th>text</th><th>phrase</th><th>word</th></tr>
<tr><td rowspan="3">买小米机,送了袋小米和苹果</td><td>买<font color="red">小米</font>机</td><td>小米</td></tr>
<tr><td>送了袋<font color="red">小米</font>和苹果</td><td>小米</td></tr>
<tr><td>送了袋小米和<font color="red">苹果</font></td><td>苹果</td></tr>
<tr><td rowspan="1">买华为送苹果</td><td>买华为送<font color="red">苹果</font></td><td>苹果</td></tr>
</table></body></html>