版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
第一题:当前有一个txt文件,内容如下
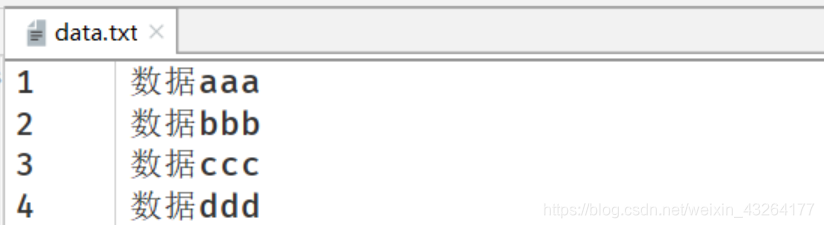
# 要求:请将数据读取出来,转换为以下格式
{'data0': '数据aaa', 'data1': '数据bbb', 'data2': '数据ccc', 'data3': '数据ddd'}
# 提示:
# 可能会用到内置函数enumerate
# 注意点:读取出来的数据如果有换行符'\n',要想办法去掉。
第二题:当前有一个case.txt文件,里面中存储了很多用例数据: 如下,每一行数据就是一条用例数据,
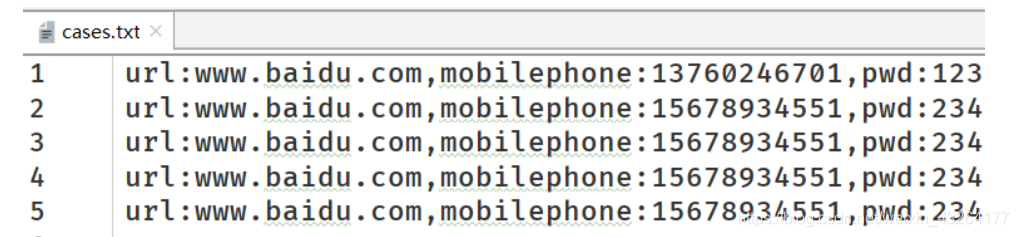
要求一: 请把这些数据读取出来,到并且存到list中,格式如下

要求二:将上述数据再次进行转换,转换为下面这种字典格式格式

提示:按行读取数据,然后使用字符串分割的方法对每一行数据进行分割,组装成字典
第三题:之前作业写了一个注册的功能,再之前的功能上进行升级,要求:把所有注册成功的用户数据放到文件中进行保存,数据存储的格式不限
提示:
每次运行程序,先去文件中读取所有注册过的用户数据,
程序运行完之后,将所有的用户数据再次写入到文件
第四题、写出模块导入的方法(至少两种),写出包导入的方法(至少两种)
# @time:2019/10/26 22:27
# @Author:coco
# @File:zy_08day.py
# @software:PyCharm
# # 第一题
# def work1():
# # 第一步:读取数据,每一行作为一个元素放到列表中
# with open('data.txt', encoding='utf8') as f:
# datas = f.readlines() # 按行去读,把每一行都读出来
# print(datas)
# # 第二步:将数据转换为字典
# dic = {}
# # 通过enumerate去获取列表中的数据和下标
# for index, data in enumerate(datas):
# print(index, data)
# # 构造数据的key和value
# key = 'data{}'.format(index)
# value = data.replace('\n', '')
# # 加入到字典
# dic[key] = value
# return dic
#
#
# res=work1()
# print(res)
# 第二题
# def work2_1():
# # 第一步:读取数据,每一行作为一个元素放到列表中
# with open('cases.txt', 'r', encoding='utf8') as f:
# datas = f.readlines()
# # print(datas)
# # 第二步:将数据转换为列表
# # 创建一个空列表
# cases = []
# # 遍历出每一行数据
# for i in datas:
# print(i)
# # 将该数据使用split进行分割,得到一个列表,
# itme = i.split(',')
# print(itme)
# # 创建一个空字典,用例存放该行数据
# dic = {}
# # 遍历分割后的列表
# for j in itme:
# # print(j)
# # 将遍历出来的数据,按:分割,得到key和value的值,然后加入到字典中
# key = j.split(':')[0]
# value = j.split(':')[1].replace('\n','')
# dic[key] = value
# # 将该数据加入到列表中
# print(dic)
# cases.append(dic)
# # 完成转换之后,将转换后的数据进行返回
# return cases
#
#
# print(work2_1())
# 要求二
# def work2_2():
# # 创建一个空字典,用例存放数据
# dic = {}
# # 通过enumereate去获取列表中的数据和下标
# for index, data in enumerate(datas):
# # 构造数据的key
# print(index, data)
# key = 'data{}'.format(index + 1)
# # print(key)
# # 加入到字典中
# dic[key] = data
# # 将转换之后的数据进行返回
# return dic
#
#
# work2_2(data2)
# 第四题
def work3():
# 读取文件中注册用户的数据
with open('users.txt', 'r', encoding='utf8') as f:
# 读取内容
data = f.read()
# 识别字符串中的列表
users = eval(data)
users = [{'user': 'python23', 'password': 'lemonban'}]
# 注册功能的代码
while True:
username = input('请输入用户名:')
for user in users: # 遍历出所有的用户名
if username == user['user']:
print('用户名已存在,请重新输入!') # 账号存在,重新输入
break
else:
password1 = input('请输入密码:') # 输入密码
password2 = input('请再次确认密码:') # 再次确认密码
if password1 != password2: # 账号和密码不一致,重新输入
print('注册失败,两次的密码不一致!')
# continue
else:
# 用户名不存在,密码不重复,则添加到注册列表
users.append({'user': username, 'password': password1})
print('恭喜你,注册成功!')
break
# 程序运行结束后,将所有用户的数据写入文件中
with open('users.txt','w',encoding='utf8') as f:
# 将列表转换为字符串
content = str(users)
# 写入文件
f.write(content)
work3()
# 第四题
# 模块导入
# 方式一:import 模块名
# 方式二:from 模块名 import 模块中的变量或者函数
# 包导入
# 方式一:from 包名 import 模块名
# 方式二:from 包名,模块名 import 模块中的变量或者函数
cases.txt文件:
url:www.baidu.com,mobilephone:13760266701,pwd:1234
url:www.baidu.com,mobilephone:13560277701,pwd:1234
url:www.baidu.com,mobilephone:13860246701,pwd:1234
url:www.baidu.com,mobilephone:13960266702,pwd:1234
url:www.baidu.com,mobilephone:13660263701,pwd:1234
users.txt文件
[{'user':'python23','password':'lemonban'}]