序言
搭建了Hbase的服务后,可以对照传统数据库去专门的搜索他的功能.这是会发现一些问题.比如只支持一级索引,只支持行级事务.故此要了解针对这些问题的解决方案.这个别文章其实是整合了其它人的劳动成果.当然也欢迎大家聊一下,虽然现在认真聊个事情是非常难.哈哈~但是万一有人有想法呢.请联系[email protected]
关于Hbase查询效率的解决方案
目前 HBase 主要应用在结构化和半结构化的大数据存储上,其在插入和读取上都具有 极高的性能表现,这与它的数据组织方式有着密切的关系,在逻辑上,HBase 的表数据按 RowKey 进行字典排序, RowKey 实际上是数据表的一级索引(Primary Index),由于 HBase 本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠 RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到 RowKey 中,这是 HBase 开发中极为常见的做法,但是无论怎样设计,单一 RowKey 固有 的局限性决定了它不可能有效地支持多条件查询。
通常来说,RowKey 只能针对条件中含有其首字段的查询给予令人满意的性能支持,在 查询其他字段时,表现就差强人意了,在极端情况下某些字段的查询性能可能会退化为全表 扫描的水平,这是因为字段在 RowKey 中的地位是不等价的,它们在 RowKey 中的排位决 定了它们被检索时的性能表现,排序越靠前的字段在查询中越具有优势,特别是首位字段 具有特别的先发优势,如果查询中包含首位字段,检索时就可以通过首位字段的值确定 RowKey 的前缀部分,从而大幅度地收窄检索区间,如果不包含则只能在全体数据的 RowKey 上逐一查找,由此可以想见两者在性能上的差距。
受限于单一 RowKey 在复杂查询上的局限性,基于二级索引(Secondary Index)的解决 方案成为最受关注的研究方向,并且开源社区已经在这方面已经取得了一定的成果,像 ITHBase、IHBase 以及华为的 hindex 项目,这些产品和框架都按照自己的方式实现了二级 索引,各自具有不同的优势,同时也都有一定局限性。
关系型数据库中索引数据与原始数据之间的数据一致性是通过关系型数据库中的组件 负责实现的,对于数据库数据的插入和删除都会在索引中展现出来,对于原始数据和索引的 操作会是一个原子/事务操作,但是在 HBase 中没有框架自身提供的机制,只能靠开发人员 自己去实现。
由于在 HBase 中的二级索引是通过建表的方式实现的,当需要更新时,就是两个表的 数据原子更新,也就是跨表的事务功能,而 Hbase 只提供行级事务,没有跨表和跨行的事 务功能,这就需要开发者自己去实现,如果对数据一致性要求较高,那么就可能需要自己 去实现一套分布式的事务机制,之所以是分布式的事务机制,是因为原始数据可能由一些 HRegionserver 维护,而索引表由另外一些 HRegionserver 维护,这个事务机制就涉及到了多 个 HRegionserver,也就是分布式的事务机制。因此,二级索引是 HBase 自身存在的一个短 板。
二级索引设置
二级索引的本质就是建立各列值与行键之间的映射关系,以列的值为键,以记录的RowKey 为值。

如图所示,当要对 F:C1 这列建立索引时,只需要建立 F:C1 各列值到其对应行键 的映射关系,如 C11->RK1 等,这样就完成了对 F:C1 列值的二级索引的构建,当要查询符 合 F:C1=C11 对应的 F:C2 的列值时(即根据 C1=C11 来查询 C2 的值,图 2-23 青色部分)。
其查询步骤如下:
1. 根据 C1=C11 到索引数据中查找其对应的 RK,查询得到其对应的 RK=RK1;
2. 得到 RK1 后就自然能根据 RK1 来查询 C2 的值了 这是构建二级索引大概思路,其 他组合查询的联合索引的建立也类似。
二级索引设计剖析
“二级多列索引”是针对目标记录的某个或某些列建立的“键-值”数据,以列的值为 键,以记录的 RowKey 为值,当以这些列为条件进行查询时,引擎可以通过检索相应的“键 -值”数据快速找到目标记录。由于 HBase 本身并没有索引机制,为了确保非侵入性,引擎 将索引视为普通数据存放在数据表中,所以,如何解决索引与主数据的划分存储是引擎第 一个需要处理的问题。
为了能获得最佳的性能表现,我们并没有将主数据和索引分表储存,而是将它们存放 在了同一张表里,通过给索引和主数据的 RowKey 添加特别设计的 Hash 前缀,实现了在 Region 切分时,索引能够跟随其主数据划归到同一 Region 上,即任意 Region 上的主数据 其索引也必定驻留在同一 Region 上,这样我们就能把从索引抓取目标主数据的性能损失降 低到最小。
与此同时,特别设计的 Hash 前缀还在逻辑上把索引与主数据进行了自动的分离,当全 体数据按 RowKey 排序时,排在前面的都是索引,我们称之为索引区,排在后面的均为主 数据,我们称之为主数据区。最后,通过给索引和主数据分配不同的 Column Family,又 在物理存储上把它们隔离了起来。逻辑和物理上的双重隔离避免了将两类数据存放在同一 张表里带来的副作用,防止了它们之间的相互干扰,降低了数据维护的复杂性,可以说这是 在性能和可维护性上达到的最佳平衡。
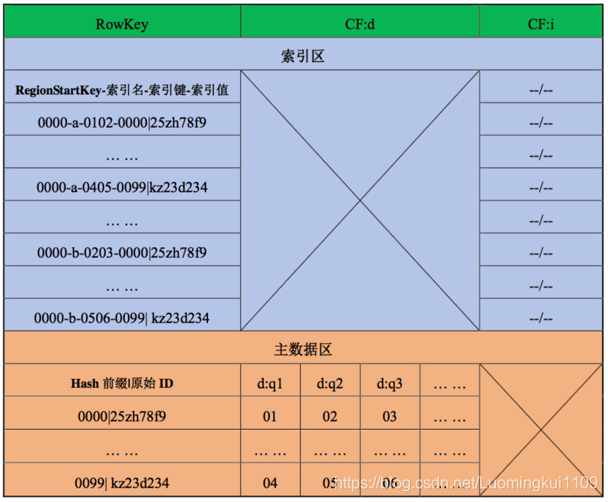
让我们通过一个示例来详细了解一下二级多列索引表的结构:
假定有一张 Sample 表,使用四位数字构成 Hash 前缀,范围从 0000 到 9999,规划切分 100 个 Region,则 100 个 Region 的 RowKey 区间分别为[0000,0099],[0100,0199],......, [9900,9999]。
以第一个 Region 为例,请看图 2-23,所有数据按 RowKey 进行字典排序,自动分成了 索引区和主数据区两段,主数据区的 Column Family 是 d,下辖 q1,q2,q3 等 Qualifier,为了 简单起见,我们假定 q1,q2,q3 的值都是由两位数字组成的字符串,索引区的 Column Family 是 i,它不含任何 Qualifier,这是一个典型的“Dummy Column Family“,作为区别于 d 的 另一个 Column Family,它的作用就是让索引独立于主数据单独存储。
接下来是最重要的部分,即索引和主数据的 RowKey,我们先看主数据的 RowKey,它 由四位 Hash 前缀和原始 ID 两部分组成,其中 Hash 前缀是由引擎分配的一个范围在 0000 到 9999 之间的随机值,通过这个随机的 Hash 前缀可以让主数据均匀地散列到所有的 Region 上,我们看图 1,因为 Region 1 的 RowKey 区间是[0000,0099],所以没有任何例外,凡是且 必须是前缀从 0000 到 0099 的主数据都被分配到了 Region 1 上。
接下来看索引的 RowKey,它的结构要相对复杂一些,格式为:RegionStartKey-索引名 -索引键-索引值,与主数据不同,索引 RowKey 的前缀部分虽然也是由四位数字组成,但却 不是随机分配的,而是固定为当前 Region 的 StartKey,这是非常重要而巧妙的设计,一方 面,这个值处在 Region 的 RowKey 区间之内,它确保了索引必定跟随其主数据被划分到同 一个 Region 里;另一方面,这个值是 RowKey 区间内的最小值,这保证了在同一 Region 里所有索引会集中排在主数据之前。接下来的部分是“索引名”,这是引擎给每类索引添 加的一个标识,用于区分不同类型的索引,图 1 中展示了两种索引:a 和 b,索引 a 是为字 段 q1 和 q2 设计的两列联合索引,索引 b 是为字段 q2 和 q3 设计的两列联合索引,依次类 推,我们可以根据需要设计任意多列的联合索引。再接下来就是索引的键和值了,索引键 是由目标记录各对应字段的值组成,而索引值就是这条记录的 RowKey。
现在,假定需要查询满足条件 q1=01 and q2=02 的 Sample 记录,分析查询字段和索引 匹配情况可知应使用索引 a,也就是说我们首先确定了索引名,于是在 Region 1 上进行 scan 的区间将从主数据全集收窄至[0000-a, 0000-b),接着拼接查询字段的值,我们得到了索引键: 0102,scan 区间又进一步收窄为[0000-a-0102, 0000-a-0103),于是我们可以很快地找到 0000-a-0102-0000|63af51b2 这条索引,进而得到了索引值,也就是目标数据的 RowKey: 0000|63af51b2,通过在 Region 内执行 Get 操作,最终得到了目标数据。需要特别说明的是 这个 Get 操作是在本 Region 上执行的,这和通过 HTable 发出的 Get 有很大的不同,它专 门用于获取 Region 的本地数据,其执行效率是非常高的,这也是为什么我们一定要将索引 和它的主数据放在同一张表的同一个 Region 上的原因。
关于Hbase的行级锁
什么是行锁?
我们知道,数据库中存在事务的概念。事务是作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全的不执行。而事务的四大特点即原子性、一致性、分离性和持久性。其中,原子性首当其冲,那么在HBase内部实现其原子性的重要保证是什么呢?答案就是行锁。
什么是行锁呢?顾名思义,它就是加在行上的一把锁。在它未释放该行前,最起码其他访问者是无法对该行做修改的,即要修改的话,必须得获得该行的锁才能拥有修改改行数据的权限,这就是行锁的含义。
HBase行锁实现原理
HBase行锁是利用Java并发包concurrent里的CountDownLatch(1)来实现的。它的主要思想就是在服务器端每个访问者单独一个数据处理线程,每个处理线程针对特定行数据修改时必须获得该行的行锁,而其他客户端线程想要修改数据的话,必须等待前面的线程释放锁后才被允许,这就利用了Java并发包中的CountDownLatch,CountDownLatch为Java中的一个同步辅助类,在完成一组正在其他线程中进行的操作之前,它允许一个或多个线程一直等待。这里,将线程数设置为1,十分巧妙的实现了独占锁的概念。
关于HBASE的对外接口
最近开始写Hbase的对外接口,发现一个问题.先说结果.建议对外接口使用固定的JSON串格式.如果你使用对象或者考虑泛型.就会有个坑等你. 因为Hbase并没有像Mybatis,Hibernate对象关系映射那样的框架(同时Hbase数据存入的都是Byte[]).所以如果你用对象封装表,就要想办法自己弄一套关系映射规则.这个坑啊~~如果用注解,则要用反射判断一个对象的所有属性,注解还有多个属性,那也要判断.所以一个表有20个属性,每个注解有3个属性(用于定义 列族,列,rowKey).则插入一条数据就要判断60次.而且每次判断都要先反射获取注解,还要反射获取该属性的类型.如果有人发现新的解决方案,也请留言告诉我[email protected]
所以使用固定格式的Json可以避免反射.这个步骤,效率上快一些.(这个是我自己想的,因为毕竟hbase不是一个ORM框架.)
关于Hbase的连接池
很多人在使用客户端api进行hbase连接的时候,会提出hbase是否有连接池,怎么实现hbase的连接池的问题,更有甚者,许多初学者在开发hbase代码的时候,经常出现hbase连接数的限制等连接问题,归根结底还是对hbase的连接对象Connection不甚了解,下面我们来详细剖析一下hbase的连接对象:
常见的使用Connection的错误方法有:
(1)自己实现一个Connection对象的资源池,每次使用都从资源池中取出一个Connection对象;
(2)每个线程一个Connection对象。
(3)每次访问HBase的时候临时创建一个Connection对象,使用完之后调用close关闭连接。
从这些做法来看,这些用户显然是把Connection对象当成了单机数据库里面的连接对象来用了。然而,作为一个分布式数据库,HBase客户端需要和多个服务器中的不同服务角色建立连接,所以HBase客户端中的Connection对象并不是简单对应一个socket连接。HBase的API文档当中对Connection的定义是:
A cluster connection encapsulating lower level individual connections to actual servers and a connection to zookeeper.
我们知道,HBase客户端要连接三个不同的服务角色:
(1)Zookeeper:主要用于获得meta-region位置,集群Id、master等信息。
(2)HBase Master:主要用于执行HBaseAdmin接口的一些操作,例如建表等。
(3)HBase RegionServer:用于读、写数据。
下图简单示意了客户端与服务器交互的步骤:

HBase客户端的Connection包含了对以上三种socket连接的封装。Connection对象和实际的socket连接之间的对应关系如下图:

在HBase客户端代码中,真正对应socket连接的是RpcConnection对象。HBase使用PoolMap这种数据结构来存储客户端到HBase服务器之间的连接。PoolMap封装了ConcurrentHashMap>的结构,key是ConnectionId(封装了服务器地址和用户ticket),value是一个RpcConnection对象的资源池。当HBase需要连接一个服务器时,首先会根据ConnectionId找到对应的连接池,然后从连接池中取出一个连接对象。
HBase中提供了三种资源池的实现,分别是Reusable,RoundRobin和ThreadLocal。具体实现可以通过hbase.client.ipc.pool.type配置项指定,默认为Reusable。连接池的大小也可以通过hbase.client.ipc.pool.size配置项指定,默认为1。
从以上分析不难得出,在HBase中Connection类已经实现了对连接的管理功能,所以我们不需要自己在Connection之上再做额外的管理。另外,Connection是线程安全的,而Table和Admin则不是线程安全的,因此正确的做法是一个进程共用一个Connection对象,而在不同的线程中使用单独的Table和Admin对象。
HBase客户端默认的是连接池大小是1,也就是每个RegionServer 1个连接。如果应用需要使用更大的连接池或指定其他的资源池类型,也可以通过修改配置实现:
config.set("hbase.client.ipc.pool.type",...);
config.set("hbase.client.ipc.pool.size",...);
connection = ConnectionFactory.createConnection(config);
...参考资料
https://blog.csdn.net/Luomingkui1109/article/details/82762852
https://blog.csdn.net/lipeng_bigdata/article/details/50458771